

Nutzen Sie die Kraft des Web Scraping mit Python und Beautiful Soup: Ein MIDI-Musikbeispiel
Das Internet ist eine Schatzkammer an Informationen, aber der programmgesteuerte Zugriff darauf kann ohne dedizierte APIs eine Herausforderung sein. Die Beautiful Soup-Bibliothek von Python bietet eine leistungsstarke Lösung, mit der Sie Daten direkt von Webseiten extrahieren und analysieren können.
Lassen Sie uns dies untersuchen, indem wir MIDI-Daten extrahieren, um ein Magenta-Neuronales Netzwerk für die Erzeugung klassischer Nintendo-Musik zu trainieren. Wir beziehen MIDI-Dateien aus dem Video Game Music Archive (VGM).
Einrichten Ihrer Umgebung
Stellen Sie sicher, dass Python 3 und pip installiert sind. Es ist wichtig, eine virtuelle Umgebung zu erstellen und zu aktivieren, bevor Abhängigkeiten installiert werden:
<code class="language-bash">pip install requests==2.22.0 beautifulsoup4==4.8.1</code>
Wir verwenden Beautiful Soup 4 (Beautiful Soup 3 wird nicht mehr gepflegt).
Scraping und Parsing mit Anfragen und schöner Suppe
Zuerst holen wir uns den HTML-Code und erstellen ein BeautifulSoup-Objekt:
<code class="language-python">import requests from bs4 import BeautifulSoup vgm_url = 'https://www.vgmusic.com/music/console/nintendo/nes/' html_text = requests.get(vgm_url).text soup = BeautifulSoup(html_text, 'html.parser')</code>
Das soup-Objekt ermöglicht die Navigation im HTML. soup.title gibt den Seitentitel an; print(soup.get_text()) zeigt den gesamten Text an.
Die Kraft der schönen Suppe meistern
Die Methoden find() und find_all() sind unerlässlich. soup.find() zielt auf einzelne Elemente ab (z. B. erhält soup.find(id='banner_ad').text Banner-Werbetext). soup.find_all() iteriert durch mehrere Elemente. Dies druckt beispielsweise alle Hyperlink-URLs:
<code class="language-python">for link in soup.find_all('a'):
print(link.get('href'))</code>find_all() akzeptiert Argumente wie reguläre Ausdrücke oder Tag-Attribute für eine präzise Filterung. Weitere Informationen zu erweiterten Funktionen finden Sie in der Beautiful Soup-Dokumentation.
HTML navigieren und analysieren
Bevor Sie Parsing-Code schreiben, prüfen Sie den vom Browser gerenderten HTML-Code. Jede Webseite ist einzigartig; Die Datenextraktion erfordert oft Kreativität und Experimentierfreudigkeit.

Unser Ziel ist es, einzigartige MIDI-Dateien herunterzuladen, ausgenommen Duplikate und Remixe. Browser-Entwicklertools (Rechtsklick, „Inspizieren“) helfen dabei, HTML-Elemente für den programmgesteuerten Zugriff zu identifizieren.
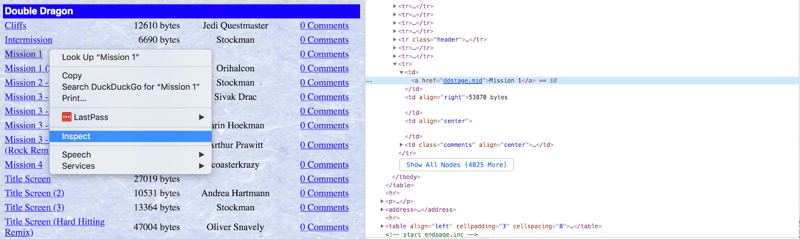
Verwenden wir find_all() mit regulären Ausdrücken, um Links zu filtern, die MIDI-Dateien enthalten (ausgenommen solche mit Klammern im Namen):
Erstellen Sie nes_midi_scraper.py:
<code class="language-python">import re
import requests
from bs4 import BeautifulSoup
vgm_url = 'https://www.vgmusic.com/music/console/nintendo/nes/'
html_text = requests.get(vgm_url).text
soup = BeautifulSoup(html_text, 'html.parser')
if __name__ == '__main__':
attrs = {'href': re.compile(r'\.mid$')}
tracks = soup.find_all('a', attrs=attrs, string=re.compile(r'^((?!\().)*$'))
count = 0
for track in tracks:
print(track)
count += 1
print(len(tracks))</code>Dies filtert MIDI-Dateien, druckt ihre Link-Tags und zeigt die Gesamtzahl an. Führen Sie mit python nes_midi_scraper.py.
Herunterladen der MIDI-Dateien
Jetzt laden wir die gefilterten MIDI-Dateien herunter. Fügen Sie die Funktion download_track zu nes_midi_scraper.py:
<code class="language-bash">pip install requests==2.22.0 beautifulsoup4==4.8.1</code>
Diese Funktion lädt jeden Titel herunter und speichert ihn unter einem eindeutigen Dateinamen. Führen Sie das Skript im gewünschten Speicherverzeichnis aus. Sie sollten ungefähr 2230 MIDI-Dateien herunterladen (abhängig vom aktuellen Inhalt der Website).

Das Potenzial des Webs erkunden
Web Scraping öffnet Türen zu riesigen Datensätzen. Denken Sie daran, dass Webseitenänderungen Ihren Code beschädigen können. Halten Sie Ihre Skripte auf dem neuesten Stand. Verwenden Sie Bibliotheken wie Mido (für die MIDI-Datenverarbeitung) und Magenta (für das Training neuronaler Netzwerke), um auf dieser Grundlage aufzubauen.
Das obige ist der detaillierte Inhalt vonWeb Scraping und Parsing von HTML in Python mit Beautiful Soup. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was sind die neuen Funktionen von Hongmeng OS 3.0?
Was sind die neuen Funktionen von Hongmeng OS 3.0?
 Wie man die Fans von Douyin schnell und effektiv steigert
Wie man die Fans von Douyin schnell und effektiv steigert
 Tastenkombinationen für Python-Kommentare
Tastenkombinationen für Python-Kommentare
 So verwenden Sie Spyder
So verwenden Sie Spyder
 Was soll ich tun, wenn die temporäre PS-Festplatte voll ist?
Was soll ich tun, wenn die temporäre PS-Festplatte voll ist?
 iPad Airplay
iPad Airplay
 string zu int
string zu int
 Passende Zeichenfolge für einen regulären Java-Ausdruck
Passende Zeichenfolge für einen regulären Java-Ausdruck








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



