
 Backend-Entwicklung
Python-Tutorial
Erstellen Sie einen KI-Code-Review-Assistenten mit Vev, Litellm und Agenta
Backend-Entwicklung
Python-Tutorial
Erstellen Sie einen KI-Code-Review-Assistenten mit Vev, Litellm und Agenta
Erstellen Sie einen KI-Code-Review-Assistenten mit Vev, Litellm und Agenta

Dieses Tutorial zeigt den Aufbau eines produktionsbereiten KI-Pull-Request-Reviewers mithilfe von LLMOps-Best Practices. Die endgültige Bewerbung, die hier zugänglich ist, akzeptiert eine öffentliche PR-URL und gibt eine von der KI generierte Bewertung zurück.
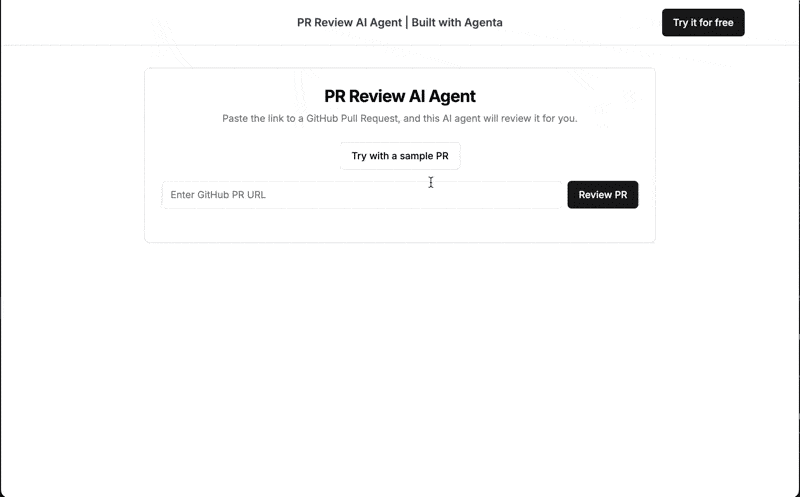
Anwendungsübersicht
Dieses Tutorial behandelt:
- Codeentwicklung: PR-Unterschiede von GitHub abrufen und LiteLLM für die LLM-Interaktion nutzen.
- Beobachtbarkeit:Implementierung von Agenta zur Anwendungsüberwachung und zum Debuggen.
- Prompt Engineering: Iteration von Eingabeaufforderungen und Modellauswahl mithilfe von Agentas Spielplatz.
- LLM-Bewertung:Einsatz von LLM als Richter für eine schnelle und vorbildliche Beurteilung.
- Bereitstellung: Bereitstellung der Anwendung als API und Erstellung einer einfachen Benutzeroberfläche mit v0.dev.
Kernlogik
Der Arbeitsablauf des KI-Assistenten ist einfach: Bei gegebener PR-URL ruft er das Diff von GitHub ab und sendet es zur Überprüfung an ein LLM.
Der Zugriff auf GitHub-Diffs erfolgt über:
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>Diese Python-Funktion ruft den Unterschied ab:
def get_pr_diff(pr_url):
# ... (Code remains the same)
return response.textLiteLLM erleichtert LLM-Interaktionen und bietet eine konsistente Schnittstelle über verschiedene Anbieter hinweg.
prompt_system = """
You are an expert Python developer performing a file-by-file review of a pull request. You have access to the full diff of the file to understand the overall context and structure. However, focus on reviewing only the specific hunk provided.
"""
prompt_user = """
Here is the diff for the file:
{diff}
Please provide a critique of the changes made in this file.
"""
def generate_critique(pr_url: str):
diff = get_pr_diff(pr_url)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.contentObservability mit Agenta implementieren
Agenta verbessert die Beobachtbarkeit, indem es Eingaben, Ausgaben und den Datenfluss verfolgt, um das Debuggen zu erleichtern.
Agenta initialisieren und LiteLLM-Rückrufe konfigurieren:
import agenta as ag ag.init() litellm.callbacks = [ag.callbacks.litellm_handler()]
Instrumentenfunktionen mit Agenta-Dekoratoren:
@ag.instrument()
def generate_critique(pr_url: str):
# ... (Code remains the same)
return response.choices[0].message.contentLegen Sie die Umgebungsvariable AGENTA_API_KEY fest (erhalten von Agenta) und optional AGENTA_HOST für Selbsthosting.

Einen LLM-Spielplatz schaffen
Agentas benutzerdefinierte Workflow-Funktion bietet einen IDE-ähnlichen Spielplatz für die iterative Entwicklung. Der folgende Codeausschnitt demonstriert die Konfiguration und Integration mit Agenta:
from pydantic import BaseModel, Field
from typing import Annotated
import agenta as ag
import litellm
from agenta.sdk.assets import supported_llm_models
# ... (previous code)
class Config(BaseModel):
system_prompt: str = prompt_system
user_prompt: str = prompt_user
model: Annotated[str, ag.MultipleChoice(choices=supported_llm_models)] = Field(default="gpt-3.5-turbo")
@ag.route("/", config_schema=Config)
@ag.instrument()
def generate_critique(pr_url:str):
diff = get_pr_diff(pr_url)
config = ag.ConfigManager.get_from_route(schema=Config)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.contentBetreuung und Bewertung mit Agenta
- Führen Sie
agenta initaus und geben Sie dabei den App-Namen und den API-Schlüssel an. - Führen Sie
agenta variant serve app.pyaus.
Dadurch wird die Anwendung über den Spielplatz von Agenta für End-to-End-Tests zugänglich gemacht. Für die Bewertung wird das LLM-as-a-Judge-Studium verwendet. Die Evaluator-Eingabeaufforderung lautet:
<code>You are an evaluator grading the quality of a PR review. CRITERIA: ... (criteria remain the same) ANSWER ONLY THE SCORE. DO NOT USE MARKDOWN. DO NOT PROVIDE ANYTHING OTHER THAN THE NUMBER</code>
Die Benutzeraufforderung für den Bewerter:
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>
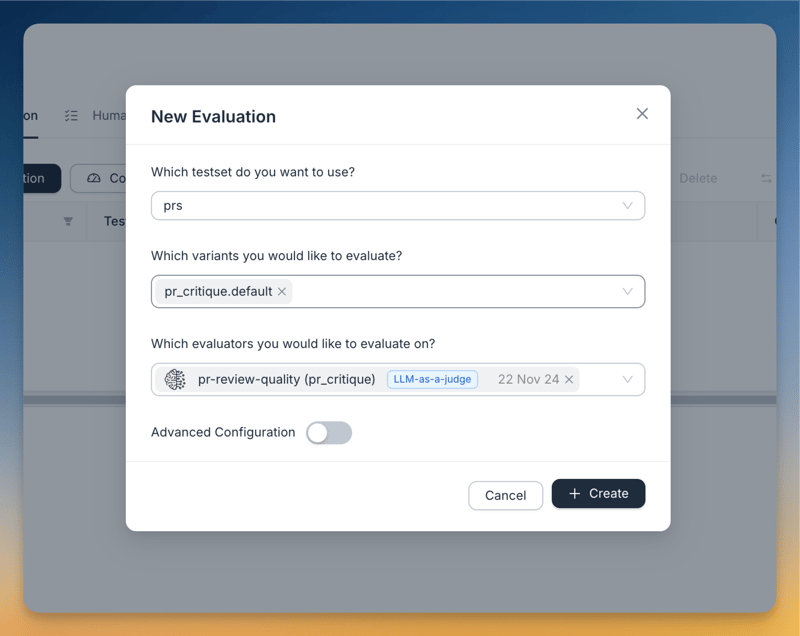
Bereitstellung und Frontend
Die Bereitstellung erfolgt über die Benutzeroberfläche von Agenta:
- Navigieren Sie zur Übersichtsseite.
- Klicken Sie auf die drei Punkte neben der gewählten Variante.
- Wählen Sie „In der Produktion bereitstellen“ aus.

Für die schnelle Erstellung der Benutzeroberfläche wurde ein v0.dev-Frontend verwendet.
Nächste Schritte und Schlussfolgerung
Zukünftige Verbesserungen umfassen eine schnelle Verfeinerung, die Einbeziehung des vollständigen Codekontexts und die Handhabung großer Unterschiede. In diesem Tutorial wird erfolgreich das Erstellen, Bewerten und Bereitstellen eines produktionsbereiten KI-Pull-Request-Reviewers mit Agenta und LiteLLM demonstriert.

Das obige ist der detaillierte Inhalt vonErstellen Sie einen KI-Code-Review-Assistenten mit Vev, Litellm und Agenta. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1670
1670
 14
1428
52
1329
25
1273
29
1256
24
14
1428
52
1329
25
1273
29
1256
24

 Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python ist leichter zu lernen und zu verwenden, während C leistungsfähiger, aber komplexer ist. 1. Python -Syntax ist prägnant und für Anfänger geeignet. Durch die dynamische Tippen und die automatische Speicherverwaltung können Sie die Verwendung einfach zu verwenden, kann jedoch zur Laufzeitfehler führen. 2.C bietet Steuerung und erweiterte Funktionen auf niedrigem Niveau, geeignet für Hochleistungsanwendungen, hat jedoch einen hohen Lernschwellenwert und erfordert manuellem Speicher und Typensicherheitsmanagement.
 Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Um die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python ist in der Entwicklungseffizienz besser als C, aber C ist in der Ausführungsleistung höher. 1. Pythons prägnante Syntax und reiche Bibliotheken verbessern die Entwicklungseffizienz. 2. Die Kompilierungsmerkmale von Compilation und die Hardwarekontrolle verbessern die Ausführungsleistung. Bei einer Auswahl müssen Sie die Entwicklungsgeschwindigkeit und die Ausführungseffizienz basierend auf den Projektanforderungen abwägen.
 Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Ist es genug, um Python für zwei Stunden am Tag zu lernen? Es hängt von Ihren Zielen und Lernmethoden ab. 1) Entwickeln Sie einen klaren Lernplan, 2) Wählen Sie geeignete Lernressourcen und -methoden aus, 3) praktizieren und prüfen und konsolidieren Sie praktische Praxis und Überprüfung und konsolidieren Sie und Sie können die Grundkenntnisse und die erweiterten Funktionen von Python während dieser Zeit nach und nach beherrschen.
 Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python und C haben jeweils ihre eigenen Vorteile, und die Wahl sollte auf Projektanforderungen beruhen. 1) Python ist aufgrund seiner prägnanten Syntax und der dynamischen Typisierung für die schnelle Entwicklung und Datenverarbeitung geeignet. 2) C ist aufgrund seiner statischen Tipp- und manuellen Speicherverwaltung für hohe Leistung und Systemprogrammierung geeignet.
 Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
PythonlistsarePartThestandardlibrary, whilearraysarenot.listarebuilt-in, vielseitig und UNDUSEDFORSPORINGECollections, während dieArrayRay-thearrayModulei und loses und loses und losesaluseduetolimitedFunctionality.
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Zu den wichtigsten Anwendungen von Python in der Webentwicklung gehören die Verwendung von Django- und Flask -Frameworks, API -Entwicklung, Datenanalyse und Visualisierung, maschinelles Lernen und KI sowie Leistungsoptimierung. 1. Django und Flask Framework: Django eignet sich für die schnelle Entwicklung komplexer Anwendungen, und Flask eignet sich für kleine oder hochmobile Projekte. 2. API -Entwicklung: Verwenden Sie Flask oder Djangorestframework, um RESTFUFFUPI zu erstellen. 3. Datenanalyse und Visualisierung: Verwenden Sie Python, um Daten zu verarbeiten und über die Webschnittstelle anzuzeigen. 4. Maschinelles Lernen und KI: Python wird verwendet, um intelligente Webanwendungen zu erstellen. 5. Leistungsoptimierung: optimiert durch asynchrones Programmieren, Caching und Code
