

Unsere aktuellen Websites stützen sich normalerweise auf Dutzende verschiedener Ressourcen, wie zum Beispiel eine monolithische Sammlung von Bildern, CSS, Schriftarten, JavaScript, JSON-Daten usw. Die erste Website der Welt wurde jedoch nur in HTML geschrieben.
JavaScript hat als hervorragende clientseitige Skriptsprache eine wichtige Rolle bei der Entwicklung von Websites gespielt. Mit Hilfe von XMLHttpRequest- oder XHR-Objekten kann JavaScript die Kommunikation zwischen Clients und Servern erreichen, ohne die Seite neu laden zu müssen.
Dieser dynamische Prozess wird jedoch durch die Fetch-API herausgefordert. Was ist die Fetch-API? Wie verwende ich die Fetch-API in Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API?? Warum ist die Fetch-API die bessere Wahl?
Bekommen Sie jetzt Antworten aus diesem Artikel!
In Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API? sind HTTP-Anfragen ein grundlegender Bestandteil beim Erstellen von Webanwendungen oder der Interaktion mit Webdiensten. Sie ermöglichen einem Client (wie einem Browser oder einer anderen Anwendung), Daten an einen Server zu senden oder Daten von einem Server anzufordern. Diese Anfragen verwenden das Hypertext Transfer Protocol (HTTP), das die Grundlage der Datenkommunikation im Web bildet.
Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API? hat sich aufgrund seiner einzigartigen Eigenschaften, seines robusten Ökosystems und seiner asynchronen, nicht blockierenden Architektur zu einer der bevorzugten Technologien für Web-Scraping- und Automatisierungsaufgaben entwickelt.
Warum ist Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API? ideal für Web Scraping und Automatisierung? Lasst uns sie herausfinden!
Node-fetch ist ein leichtgewichtiges Modul, das die Fetch-API in die Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API?-Umgebung bringt. Es vereinfacht den Prozess der Erstellung von HTTP-Anfragen und der Bearbeitung von Antworten.
Die Fetch-API basiert auf Promises und eignet sich gut für asynchrone Vorgänge wie das Scrapen von Daten von einer Website, die Interaktion mit einer RESTful-API oder die Automatisierung von Aufgaben.
Die Fetch-API ist eine moderne, Promise-basierte Schnittstelle, die dafür entwickelt wurde, Netzwerkanfragen im Vergleich zum herkömmlichen XMLHttpRequest-Objekt effizienter und flexibler zu verarbeiten.
Es wird nativ in modernen Browsern unterstützt, sodass keine zusätzlichen Bibliotheken oder Plugins erforderlich sind. In diesem Leitfaden erfahren Sie, wie Sie die Fetch-API zum Ausführen von GET- und POST-Anfragen nutzen und wie Sie Antworten und Fehler effektiv verwalten.
? Hinweis: Wenn Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API? nicht auf Ihrem Computer installiert ist, müssen Sie es zuerst installieren. Das für Ihr Betriebssystem passende Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API?-Installationspaket können Sie hier herunterladen. Die empfohlene Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API?-Version ist 18 und höher.
Wenn Sie noch kein Projekt erstellt haben, können Sie mit dem folgenden Befehl ein neues Projekt erstellen:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
Öffnen Sie die Datei package.json, fügen Sie das Typfeld hinzu und setzen Sie es auf module:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Dies ist eine Bibliothek zur Verwendung der Fetch-API in Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API?. Sie können die Node-Fetch-Bibliothek mit dem folgenden Befehl installieren:
npm install node-fetch
Nachdem der Download abgeschlossen ist, können wir mit der Fetch-API zum Senden von Netzwerkanfragen beginnen. Erstellen Sie eine neue Datei index.js im Stammverzeichnis des Projekts und fügen Sie den folgenden Code hinzu:
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));
Führen Sie den folgenden Befehl aus, um den Code auszuführen:
node index.js
Wir werden die folgende Ausgabe sehen:

Wie verwende ich die Fetch-API, um die POST-Anfrage zu senden? Bitte beachten Sie die folgende Methode. Erstellen Sie eine neue Datei post.js im Stammverzeichnis des Projekts und fügen Sie den folgenden Code hinzu:
import fetch from 'node-fetch';
const postData = {
title: 'foo',
body: 'bar',
userId: 1,
};
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));
Lassen Sie uns diesen Code analysieren:
Führen Sie den folgenden Befehl aus, um den Code auszuführen:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
Die Ausgabe, die Sie sehen können:

Wir müssen eine neue Datei „response.js“ im Stammverzeichnis des Projekts erstellen und den folgenden Code hinzufügen:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Im obigen Code geben wir zunächst eine falsche URL-Adresse ein, um einen HTTP-Fehler auszulösen. Dann prüfen wir den Statuscode der resultierenden Antwort in der then-Methode und geben einen Fehler aus, wenn der Statuscode nicht 200 ist. Schließlich fangen wir den Fehler in der Catch-Methode ab und drucken ihn aus.
Führen Sie den folgenden Befehl aus, um den Code auszuführen:
npm install node-fetch
Nachdem der Code ausgeführt wurde, sehen Sie die folgende Ausgabe:

CAPTCHAs (Completely Automated Public Turing Tests to Tell Computers and Humans Apart) sollen verhindern, dass automatisierte Systeme wie Web Scraper auf Websites zugreifen. Normalerweise müssen Benutzer beweisen, dass sie ein Mensch sind, indem sie Rätsel lösen, Objekte in Bildern identifizieren oder verzerrte Zeichen eingeben.
Viele moderne Websites verwenden JavaScript-Frameworks wie React, Angular oder Vue.js, um Inhalte dynamisch zu laden. Das bedeutet, dass der Inhalt, den Sie im Browser sehen, oft nach dem Laden der Seite gerendert wird, was das Scrapen mit herkömmlichen Methoden, die auf statischem HTML basieren, schwierig macht.
Websites implementieren häufig Maßnahmen zur Erkennung und Blockierung von Scraping-Aktivitäten. Eine der häufigsten Methoden ist die IP-Blockierung. Dies geschieht, wenn in kurzer Zeit zu viele Anfragen von derselben IP-Adresse gesendet werden, was dazu führt, dass die Website diese IP markiert und blockiert.
Scrapeless ist eines der besten umfassenden Scraping-Tools, da es Website-Blockierungen in Echtzeit umgehen kann, einschließlich IP-Blockierung, CAPTCHA-Herausforderungen und JavaScript-Rendering. Es unterstützt erweiterte Funktionen wie IP-Rotation, TLS-Fingerabdruckverwaltung und CAPTCHA-Lösung und ist somit ideal für groß angelegtes Web-Scraping.
Seine einfache Integration mit Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API? und die hohe Erfolgsquote bei der Vermeidung von Erkennung machen Scrapeless zu einer zuverlässigen und effizienten Wahl, um moderne Anti-Bot-Abwehrmaßnahmen zu umgehen und einen reibungslosen und unterbrechungsfreien Scraping-Vorgang zu gewährleisten.
Befolgen Sie einfach einige einfache Schritte, um Scrapeless in Ihr Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API?-Projekt zu integrieren.
Es ist Zeit, weiter zu scrollen! Das Folgende wird noch schöner!
Bevor Sie beginnen, müssen Sie ein Scrapeless-Konto registrieren.
Wir müssen zum Scrapeless-Dashboard gehen, links auf das Menü „Scraping API“ klicken und dann einen Dienst auswählen, den Sie verwenden möchten.
Hier können wir den Dienst „Amazon“ nutzen

Wenn wir die Amazon-API-Seite aufrufen, können wir sehen, dass Scrapeless uns Standardparameter und Codebeispiele in drei Sprachen bereitgestellt hat:
Hier wählen wir Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API? und kopieren das Codebeispiel in unser Projekt:
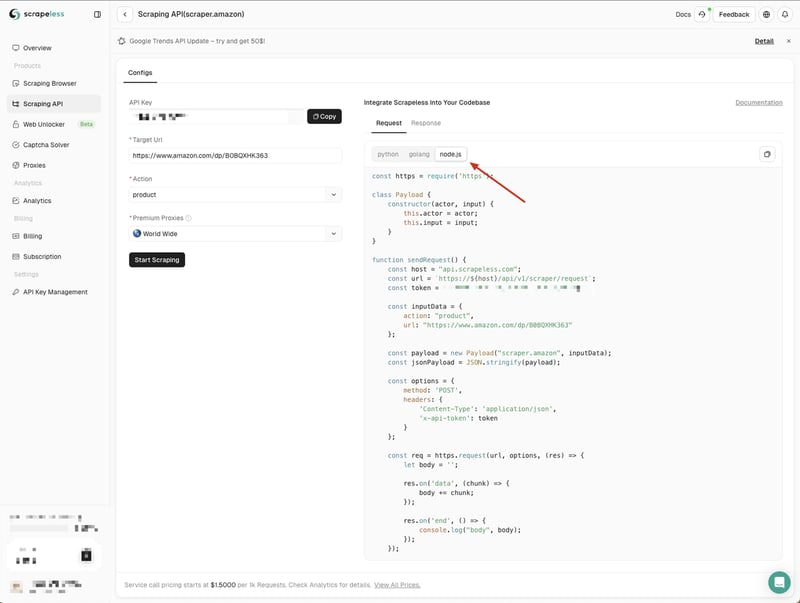
Die Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API?-Codebeispiele von Scrapeless verwenden standardmäßig das http-Modul. Wir können das Node-Fetch-Modul verwenden, um das http-Modul zu ersetzen, sodass wir die Fetch-API zum Senden von Netzwerkanfragen verwenden können.
Erstellen Sie zunächst eine scraping-api-amazon.js-Datei in unserem Projekt und ersetzen Sie dann die von Scrapeless bereitgestellten Codebeispiele durch die folgenden Codebeispiele:
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
Führen Sie den Code aus, indem Sie den folgenden Befehl ausführen:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Wir werden die von der Scrapeless API zurückgegebenen Ergebnisse sehen. Hier drucken wir sie einfach aus. Sie können die zurückgegebenen Ergebnisse entsprechend Ihren Anforderungen verarbeiten.

Scrapeless bietet einen Web Unlocker-Dienst, der Ihnen dabei helfen kann, gängige Anti-Scraping-Maßnahmen wie CAPTCHA-Umgehung, IP-Blockierung usw. zu umgehen. Der Web Unlocker-Dienst kann Ihnen dabei helfen, einige häufige Crawling-Probleme zu lösen und zu beheben Ihre Crawling-Aufgaben werden reibungsloser.
Um die Wirksamkeit des Web-Unlocker-Dienstes zu überprüfen, können wir zunächst den Curl-Befehl verwenden, um auf eine Website zuzugreifen, die ein CAPTCHA erfordert, und dann den Scrapeless Web-Unlocker-Dienst verwenden, um auf dieselbe Website zuzugreifen, um zu sehen, ob das CAPTCHA erfolgreich sein kann umgangen.
mkdir fetch-api-tutorial cd fetch-api-tutorial npm init -y
Anhand der zurückgegebenen Ergebnisse können wir erkennen, dass diese Website mit dem Cloudflare-Verifizierungsmechanismus verbunden ist und wir den Bestätigungscode eingeben müssen, um weiterhin auf die Website zugreifen zu können.


Hier erstellen wir eine neue web-unlocker.js-Datei. Wir müssen weiterhin das Node-Fetch-Modul zum Senden von Netzwerkanforderungen verwenden, daher müssen wir das http-Modul im von Scrapeless bereitgestellten Codebeispiel durch das Node-Fetch-Modul ersetzen:
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Führen Sie den folgenden Befehl aus, um das Skript auszuführen:
npm install node-fetch


Schau! Scrapeless Web Unlocker hat den Bestätigungscode erfolgreich umgangen und wir können sehen, dass die zurückgegebenen Ergebnisse den von uns benötigten Webseiteninhalt enthalten.
Um Ihnen die Auswahl zu erleichtern, weisen Axios und Fetch API die folgenden Unterschiede auf:
Das bemerkenswerteste Merkmal von Node. js v21 ist die Stabilisierung der Fetch-API.
Für neue Projekte wird aufgrund ihrer modernen Funktionen und Einfachheit die Verwendung der Fetch-API empfohlen. Wenn Sie jedoch sehr alte Browser unterstützen müssen oder Legacy-Code beibehalten, ist Ajax möglicherweise dennoch erforderlich.
Die Hinzufügung der Fetch-API in Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API? ist eine lang erwartete Funktion. Durch die Verwendung der Fetch-API in Wie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API? können Sie sicherstellen, dass Ihre Scraping-Arbeit problemlos erledigt wird. Allerdings ist es unvermeidlich, dass es bei der Verwendung der Node Fetch API zu ernsthaften Netzwerkblockaden kommt.
Das obige ist der detaillierte Inhalt vonWie mache ich HTTP-Anfragen in Node.js mit der Node-Fetch-API?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



