

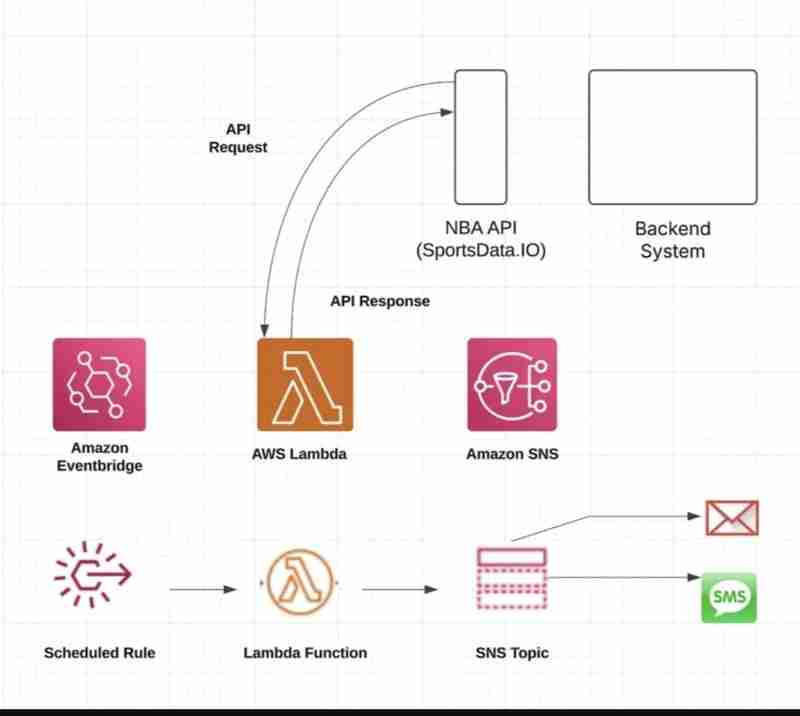
Dieses Tutorial beschreibt die Erstellung einer automatisierten NBA-Statistikdatenpipeline mithilfe von AWS-Diensten, Python und DynamoDB. Egal, ob Sie ein Sportdaten-Enthusiast oder ein AWS-Lerner sind, dieses praktische Projekt bietet wertvolle Erfahrungen in der realen Datenverarbeitung.
Projektübersicht
Diese Pipeline ruft automatisch NBA-Statistiken von der SportsData-API ab, verarbeitet die Daten und speichert sie in DynamoDB. Zu den verwendeten AWS-Diensten gehören:
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie Folgendes haben:
Projekteinrichtung
Klonen Sie das Repository und installieren Sie Abhängigkeiten:
<code class="language-bash">git clone https://github.com/nolunchbreaks/nba-stats-pipeline.git cd nba-stats-pipeline pip install -r requirements.txt</code>
Umgebungskonfiguration
Erstellen Sie eine .env-Datei im Projektstammverzeichnis mit diesen Variablen:
<code>SPORTDATA_API_KEY=your_api_key_here AWS_REGION=us-east-1 DYNAMODB_TABLE_NAME=nba-player-stats</code>
Projektstruktur
Die Verzeichnisstruktur des Projekts ist wie folgt:
<code>nba-stats-pipeline/ ├── src/ │ ├── __init__.py │ ├── nba_stats.py │ └── lambda_function.py ├── tests/ ├── requirements.txt ├── README.md └── .env</code>
Datenspeicherung und -struktur
DynamoDB-Schema
Die Pipeline speichert NBA-Teamstatistiken in DynamoDB unter Verwendung dieses Schemas:
AWS-Infrastruktur

DynamoDB-Tabellenkonfiguration
Konfigurieren Sie die DynamoDB-Tabelle wie folgt:
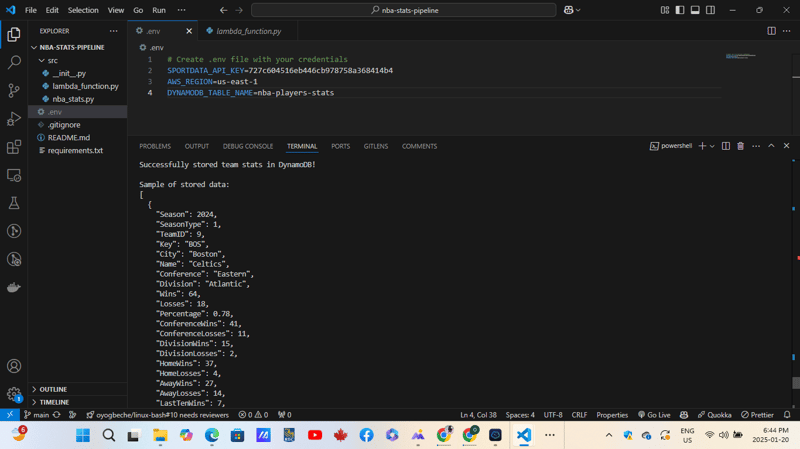
nba-player-stats
TeamID (String)Timestamp (Nummer)Lambda-Funktionskonfiguration (bei Verwendung von Lambda)
lambda_function.lambda_handler
Fehlerbehandlung und -überwachung
Die Pipeline umfasst eine robuste Fehlerbehandlung für API-Fehler, DynamoDB-Drosselung, Datentransformationsprobleme und ungültige API-Antworten. CloudWatch protokolliert alle Ereignisse in strukturiertem JSON zur Leistungsüberwachung, zum Debuggen und zur Sicherstellung einer erfolgreichen Datenverarbeitung.
Ressourcenbereinigung
Nach Abschluss des Projekts bereinigen Sie die AWS-Ressourcen:
<code class="language-bash">git clone https://github.com/nolunchbreaks/nba-stats-pipeline.git cd nba-stats-pipeline pip install -r requirements.txt</code>
Wichtige Erkenntnisse
Dieses Projekt hat Folgendes hervorgehoben:
Zukünftige Verbesserungen
Mögliche Projekterweiterungen sind:
Fazit
Diese NBA-Statistikpipeline demonstriert die Leistungsfähigkeit der Kombination von AWS-Diensten und Python zum Aufbau funktionaler Datenpipelines. Es ist eine wertvolle Ressource für alle, die sich für Sportanalysen oder AWS-Datenverarbeitung interessieren. Teilen Sie Ihre Erfahrungen und Verbesserungsvorschläge!
Folgen Sie für weitere AWS- und Python-Tutorials! Schätzen Sie ein ❤️ und ein ? wenn Sie das hilfreich fanden!
Das obige ist der detaillierte Inhalt vonAufbau einer NBA-Statistik-Pipeline mit AWS, Python und DynamoDB. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So lösen Sie verstümmelte Tomcat-Protokolle
So lösen Sie verstümmelte Tomcat-Protokolle
 Was sind die Lebenszyklen von vue3?
Was sind die Lebenszyklen von vue3?
 Was soll ich tun, wenn mein Laufwerk C rot wird?
Was soll ich tun, wenn mein Laufwerk C rot wird?
 So kaufen Sie Ripple in China
So kaufen Sie Ripple in China
 So lösen Sie das Problem, dass WLAN keine gültige IP-Konfiguration hat
So lösen Sie das Problem, dass WLAN keine gültige IP-Konfiguration hat
 Was tun, wenn der Ordner „Dokumente' beim Einschalten des Computers angezeigt wird?
Was tun, wenn der Ordner „Dokumente' beim Einschalten des Computers angezeigt wird?
 Können Douyin-Kurzvideos nach dem Löschen wiederhergestellt werden?
Können Douyin-Kurzvideos nach dem Löschen wiederhergestellt werden?
 Software zur Verschlüsselung von Mobiltelefonen
Software zur Verschlüsselung von Mobiltelefonen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



