
 Backend-Entwicklung
Python-Tutorial
Wie stellt man mit CDKTF eine SpringBoot-API auf AWS ECS bereit?
Backend-Entwicklung
Python-Tutorial
Wie stellt man mit CDKTF eine SpringBoot-API auf AWS ECS bereit?
Wie stellt man mit CDKTF eine SpringBoot-API auf AWS ECS bereit?

Als mich ein Java-Entwickler fragte, wie er seine Spring Boot-API auf AWS ECS bereitstellen könne, sah ich darin die perfekte Gelegenheit, in die neuesten Updates des CDKTF-Projekts (Cloud Development Kit for Terraform) einzutauchen.
In einem früheren Artikel habe ich CDKTF vorgestellt, ein Framework, das es Ihnen ermöglicht, Infrastructure as Code (IaC) mit allgemeinen Programmiersprachen wie Python zu schreiben. Seitdem hat CDKTF seine erste GA-Veröffentlichung erreicht, was den perfekten Zeitpunkt für einen erneuten Besuch darstellt. In diesem Artikel gehen wir Schritt für Schritt durch die Bereitstellung einer Spring Boot-API auf AWS ECS mithilfe von CDKTF.
Den Code dieses Artikels finden Sie in meinem Github-Repo.
Architekturübersicht
Bevor wir uns mit der Implementierung befassen, werfen wir einen Blick auf die Architektur, die wir bereitstellen möchten:
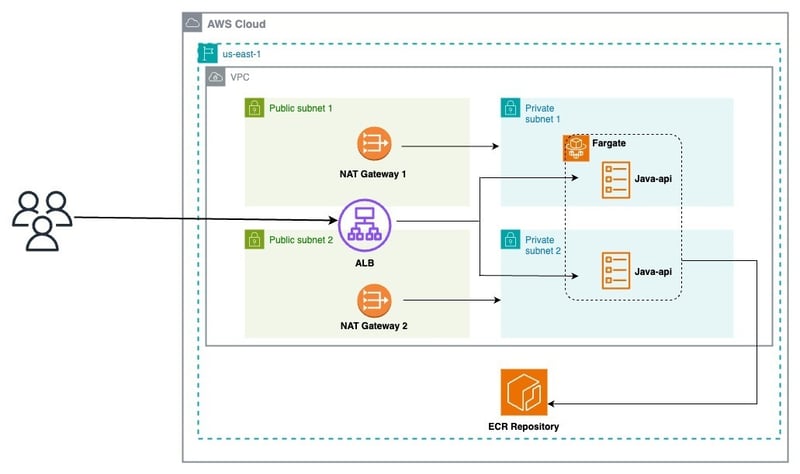
Aus diesem Diagramm können wir die Architektur in 03 Schichten unterteilen:
-
Netzwerk:
- VPC
- Öffentliche und private Subnetze
- Internet-Gateway
- NAT-Gateways
-
Infrastruktur:
- Application Load Balancer (ALB)
- Zuhörer
- ECS-Cluster
-
Service-Stack:
- Zielgruppen
- ECS-Service
- Aufgabendefinitionen
Schritt 1: Containerisieren Sie Ihre Spring Boot-Anwendung
Die von uns bereitgestellte Java-API ist auf GitHub verfügbar.
Es definiert eine einfache REST-API mit drei Endpunkten:
- /ping: Gibt die Zeichenfolge „pong“ zurück. Dieser Endpunkt ist nützlich, um die Reaktionsfähigkeit der API zu testen. Außerdem wird eine Prometheus-Zählermetrik für die Überwachung erhöht.
- /healthcheck: Gibt „ok“ zurück und dient als Endpunkt für die Gesundheitsprüfung, um sicherzustellen, dass die Anwendung ordnungsgemäß ausgeführt wird. Wie /ping aktualisiert es einen Prometheus-Zähler für die Beobachtbarkeit.
- /hello: Akzeptiert einen Namensabfrageparameter (standardmäßig „Welt“) und gibt eine personalisierte Begrüßung zurück, z. B. „Hallo, [Name]!“. Dieser Endpunkt lässt sich auch in den Prometheus-Zähler integrieren.
Fügen wir die Docker-Datei hinzu:
FROM maven:3.9-amazoncorretto-21 AS builder WORKDIR /app COPY pom.xml . COPY src src RUN mvn clean package # amazon java distribution FROM amazoncorretto:21-alpine COPY --from=builder /app/target/*.jar /app/java-api.jar EXPOSE 8080 ENTRYPOINT ["java","-jar","/app/java-api.jar"]
Unsere Anwendung ist einsatzbereit!
Schritt 2: Richten Sie AWS CDKTF ein
AWS CDKTF ermöglicht Ihnen die Definition und Verwaltung von AWS-Ressourcen mit Python.
1. Voraussetzungen
- [**python (3.13)**](https://www.python.org/) - [**pipenv**](https://pipenv.pypa.io/en/latest/) - [**npm**](https://nodejs.org/en/)
2. CDKTF und Abhängigkeiten installieren
Stellen Sie sicher, dass Sie über die erforderlichen Tools verfügen, indem Sie CDKTF und seine Abhängigkeiten installieren:
$ npm install -g cdktf-cli@latest
Dadurch wird die cdktf-CLI installiert, mit der neue Projekte für verschiedene Sprachen erstellt werden können.
3. Initialisieren Sie Ihre CDKTF-Anwendung
Wir können ein neues Python-Projekt erstellen, indem wir Folgendes ausführen:
FROM maven:3.9-amazoncorretto-21 AS builder WORKDIR /app COPY pom.xml . COPY src src RUN mvn clean package # amazon java distribution FROM amazoncorretto:21-alpine COPY --from=builder /app/target/*.jar /app/java-api.jar EXPOSE 8080 ENTRYPOINT ["java","-jar","/app/java-api.jar"]
Es werden standardmäßig viele Dateien erstellt und alle Abhängigkeiten werden installiert.
unten finden Sie die anfängliche main.pyfile:
- [**python (3.13)**](https://www.python.org/) - [**pipenv**](https://pipenv.pypa.io/en/latest/) - [**npm**](https://nodejs.org/en/)
Schritt 3: Schichten Gebäude
a Stack repräsentiert eine Gruppe von Infrastrukturressourcen, die CDK für Terraform (CDKTF) zu einer unterschiedlichen Terraform -Konfiguration kompiliert. Stapel ermöglichen ein separates staatliches Management für verschiedene Umgebungen innerhalb einer Anwendung. Um Ressourcen über Ebenen hinweg zu teilen, werden wir Cross-Stack-Referenzen verwenden.
1. Netzwerkschicht
Fügen Sie die Datei network_stack.py in Ihrem Projekt hinzu
$ npm install -g cdktf-cli@latest
Fügen Sie den folgenden Code hinzu, um alle Netzwerkressourcen zu erstellen:
# init the project using aws provider $ mkdir samples-fargate $ cd samples-fargate && cdktf init --template=python --providers=aws
Bearbeiten Sie dann die main.py
Datei:
#!/usr/bin/env python
from constructs import Construct
from cdktf import App, TerraformStack
class MyStack(TerraformStack):
def __init__(self, scope: Construct, id: str):
super().__init__(scope, id)
# define resources here
app = App()
MyStack(app, "aws-cdktf-samples-fargate")
app.synth()
Generieren Sie die Terraform -Konfigurationsdateien, indem Sie den folgenden Befehl ausführen:
$ mkdir infra $ cd infra && touch network_stack.py
Bereitstellen Sie den -Netzwerkstapel
bereit:
from constructs import Construct
from cdktf import S3Backend, TerraformStack
from cdktf_cdktf_provider_aws.provider import AwsProvider
from cdktf_cdktf_provider_aws.vpc import Vpc
from cdktf_cdktf_provider_aws.subnet import Subnet
from cdktf_cdktf_provider_aws.eip import Eip
from cdktf_cdktf_provider_aws.nat_gateway import NatGateway
from cdktf_cdktf_provider_aws.route import Route
from cdktf_cdktf_provider_aws.route_table import RouteTable
from cdktf_cdktf_provider_aws.route_table_association import RouteTableAssociation
from cdktf_cdktf_provider_aws.internet_gateway import InternetGateway
class NetworkStack(TerraformStack):
def __init__(self, scope: Construct, ns: str, params: dict):
super().__init__(scope, ns)
self.region = params["region"]
# configure the AWS provider to use the us-east-1 region
AwsProvider(self, "AWS", region=self.region)
# use S3 as backend
S3Backend(
self,
bucket=params["backend_bucket"],
key=params["backend_key_prefix"] + "/network.tfstate",
region=self.region,
)
# create the vpc
vpc_demo = Vpc(self, "vpc-demo", cidr_block="192.168.0.0/16")
# create two public subnets
public_subnet1 = Subnet(
self,
"public-subnet-1",
vpc_id=vpc_demo.id,
availability_zone=f"{self.region}a",
cidr_block="192.168.1.0/24",
)
public_subnet2 = Subnet(
self,
"public-subnet-2",
vpc_id=vpc_demo.id,
availability_zone=f"{self.region}b",
cidr_block="192.168.2.0/24",
)
# create. the internet gateway
igw = InternetGateway(self, "igw", vpc_id=vpc_demo.id)
# create the public route table
public_rt = Route(
self,
"public-rt",
route_table_id=vpc_demo.main_route_table_id,
destination_cidr_block="0.0.0.0/0",
gateway_id=igw.id,
)
# create the private subnets
private_subnet1 = Subnet(
self,
"private-subnet-1",
vpc_id=vpc_demo.id,
availability_zone=f"{self.region}a",
cidr_block="192.168.10.0/24",
)
private_subnet2 = Subnet(
self,
"private-subnet-2",
vpc_id=vpc_demo.id,
availability_zone=f"{self.region}b",
cidr_block="192.168.20.0/24",
)
# create the Elastic IPs
eip1 = Eip(self, "nat-eip-1", depends_on=[igw])
eip2 = Eip(self, "nat-eip-2", depends_on=[igw])
# create the NAT Gateways
private_nat_gw1 = NatGateway(
self,
"private-nat-1",
subnet_id=public_subnet1.id,
allocation_id=eip1.id,
)
private_nat_gw2 = NatGateway(
self,
"private-nat-2",
subnet_id=public_subnet2.id,
allocation_id=eip2.id,
)
# create Route Tables
private_rt1 = RouteTable(self, "private-rt1", vpc_id=vpc_demo.id)
private_rt2 = RouteTable(self, "private-rt2", vpc_id=vpc_demo.id)
# add default routes to tables
Route(
self,
"private-rt1-default-route",
route_table_id=private_rt1.id,
destination_cidr_block="0.0.0.0/0",
nat_gateway_id=private_nat_gw1.id,
)
Route(
self,
"private-rt2-default-route",
route_table_id=private_rt2.id,
destination_cidr_block="0.0.0.0/0",
nat_gateway_id=private_nat_gw2.id,
)
# associate routes with subnets
RouteTableAssociation(
self,
"public-rt-association",
subnet_id=private_subnet2.id,
route_table_id=private_rt2.id,
)
RouteTableAssociation(
self,
"private-rt1-association",
subnet_id=private_subnet1.id,
route_table_id=private_rt1.id,
)
RouteTableAssociation(
self,
"private-rt2-association",
subnet_id=private_subnet2.id,
route_table_id=private_rt2.id,
)
# terraform outputs
self.vpc_id = vpc_demo.id
self.public_subnets = [public_subnet1.id, public_subnet2.id]
self.private_subnets = [private_subnet1.id, private_subnet2.id]

Unser VPC ist bereit, wie im Bild unten gezeigt:

2. Infrastrukturschicht
Fügen Sie die Datei infra_stack.py
Ihrem Projekt
#!/usr/bin/env python
from constructs import Construct
from cdktf import App, TerraformStack
from infra.network_stack import NetworkStack
ENV = "dev"
AWS_REGION = "us-east-1"
BACKEND_S3_BUCKET = "blog.abdelfare.me"
BACKEND_S3_KEY = f"{ENV}/cdktf-samples"
class MyStack(TerraformStack):
def __init__(self, scope: Construct, id: str):
super().__init__(scope, id)
# define resources here
app = App()
MyStack(app, "aws-cdktf-samples-fargate")
network = NetworkStack(
app,
"network",
{
"region": AWS_REGION,
"backend_bucket": BACKEND_S3_BUCKET,
"backend_key_prefix": BACKEND_S3_KEY,
},
)
app.synth()
Fügen Sie den folgenden Code hinzu, um alle Infrastrukturressourcen zu erstellen:
$ cdktf synth
Bearbeiten Sie die main.py
Datei:
$ cdktf deploy network
Bereitstellen Sie die Infra Stack
damit ein:
$ cd infra && touch infra_stack.py
Beachten Sie den DNS -Namen des ALB, wir werden ihn später verwenden.

3. Service Layer
Fügen Sie die Datei service_stack.py
zu Ihrem Projekt hinzu
from constructs import Construct
from cdktf import S3Backend, TerraformStack
from cdktf_cdktf_provider_aws.provider import AwsProvider
from cdktf_cdktf_provider_aws.ecs_cluster import EcsCluster
from cdktf_cdktf_provider_aws.lb import Lb
from cdktf_cdktf_provider_aws.lb_listener import (
LbListener,
LbListenerDefaultAction,
LbListenerDefaultActionFixedResponse,
)
from cdktf_cdktf_provider_aws.security_group import (
SecurityGroup,
SecurityGroupIngress,
SecurityGroupEgress,
)
class InfraStack(TerraformStack):
def __init__(self, scope: Construct, ns: str, network: dict, params: dict):
super().__init__(scope, ns)
self.region = params["region"]
# Configure the AWS provider to use the us-east-1 region
AwsProvider(self, "AWS", region=self.region)
# use S3 as backend
S3Backend(
self,
bucket=params["backend_bucket"],
key=params["backend_key_prefix"] + "/load_balancer.tfstate",
region=self.region,
)
# create the ALB security group
alb_sg = SecurityGroup(
self,
"alb-sg",
vpc_id=network["vpc_id"],
ingress=[
SecurityGroupIngress(
protocol="tcp", from_port=80, to_port=80, cidr_blocks=["0.0.0.0/0"]
)
],
egress=[
SecurityGroupEgress(
protocol="-1", from_port=0, to_port=0, cidr_blocks=["0.0.0.0/0"]
)
],
)
# create the ALB
alb = Lb(
self,
"alb",
internal=False,
load_balancer_type="application",
security_groups=[alb_sg.id],
subnets=network["public_subnets"],
)
# create the LB Listener
alb_listener = LbListener(
self,
"alb-listener",
load_balancer_arn=alb.arn,
port=80,
protocol="HTTP",
default_action=[
LbListenerDefaultAction(
type="fixed-response",
fixed_response=LbListenerDefaultActionFixedResponse(
content_type="text/plain",
status_code="404",
message_body="Could not find the resource you are looking for",
),
)
],
)
# create the ECS cluster
cluster = EcsCluster(self, "cluster", name=params["cluster_name"])
self.alb_arn = alb.arn
self.alb_listener = alb_listener.arn
self.alb_sg = alb_sg.id
self.cluster_id = cluster.id
Fügen Sie den folgenden Code hinzu, um alle ECS -Service -Ressourcen zu erstellen:
...
CLUSTER_NAME = "cdktf-samples"
...
infra = InfraStack(
app,
"infra",
{
"vpc_id": network.vpc_id,
"public_subnets": network.public_subnets,
},
{
"region": AWS_REGION,
"backend_bucket": BACKEND_S3_BUCKET,
"backend_key_prefix": BACKEND_S3_KEY,
"cluster_name": CLUSTER_NAME,
},
)
...
aktualisieren Sie die main.py (zum letzten Mal?):
$ cdktf deploy network infra
Bereitstellen Sie den Service -Stack
bereit:
$ mkdir apps $ cd apps && touch service_stack.py
Hier gehen wir!
Wir haben alle Ressourcen erfolgreich erstellt, um einen neuen Dienst auf AWS ECS Fargate bereitzustellen.
Führen Sie Folgendes aus, um die Liste Ihrer Stapel zu erhalten
from constructs import Construct
import json
from cdktf import S3Backend, TerraformStack, Token, TerraformOutput
from cdktf_cdktf_provider_aws.provider import AwsProvider
from cdktf_cdktf_provider_aws.ecs_service import (
EcsService,
EcsServiceLoadBalancer,
EcsServiceNetworkConfiguration,
)
from cdktf_cdktf_provider_aws.ecr_repository import (
EcrRepository,
EcrRepositoryImageScanningConfiguration,
)
from cdktf_cdktf_provider_aws.ecr_lifecycle_policy import EcrLifecyclePolicy
from cdktf_cdktf_provider_aws.ecs_task_definition import (
EcsTaskDefinition,
)
from cdktf_cdktf_provider_aws.lb_listener_rule import (
LbListenerRule,
LbListenerRuleAction,
LbListenerRuleCondition,
LbListenerRuleConditionPathPattern,
)
from cdktf_cdktf_provider_aws.lb_target_group import (
LbTargetGroup,
LbTargetGroupHealthCheck,
)
from cdktf_cdktf_provider_aws.security_group import (
SecurityGroup,
SecurityGroupIngress,
SecurityGroupEgress,
)
from cdktf_cdktf_provider_aws.cloudwatch_log_group import CloudwatchLogGroup
from cdktf_cdktf_provider_aws.data_aws_iam_policy_document import (
DataAwsIamPolicyDocument,
)
from cdktf_cdktf_provider_aws.iam_role import IamRole
from cdktf_cdktf_provider_aws.iam_role_policy_attachment import IamRolePolicyAttachment
class ServiceStack(TerraformStack):
def __init__(
self, scope: Construct, ns: str, network: dict, infra: dict, params: dict
):
super().__init__(scope, ns)
self.region = params["region"]
# Configure the AWS provider to use the us-east-1 region
AwsProvider(self, "AWS", region=self.region)
# use S3 as backend
S3Backend(
self,
bucket=params["backend_bucket"],
key=params["backend_key_prefix"] + "/" + params["app_name"] + ".tfstate",
region=self.region,
)
# create the service security group
svc_sg = SecurityGroup(
self,
"svc-sg",
vpc_id=network["vpc_id"],
ingress=[
SecurityGroupIngress(
protocol="tcp",
from_port=params["app_port"],
to_port=params["app_port"],
security_groups=[infra["alb_sg"]],
)
],
egress=[
SecurityGroupEgress(
protocol="-1", from_port=0, to_port=0, cidr_blocks=["0.0.0.0/0"]
)
],
)
# create the service target group
svc_tg = LbTargetGroup(
self,
"svc-target-group",
name="svc-tg",
port=params["app_port"],
protocol="HTTP",
vpc_id=network["vpc_id"],
target_type="ip",
health_check=LbTargetGroupHealthCheck(path="/ping", matcher="200"),
)
# create the service listener rule
LbListenerRule(
self,
"alb-rule",
listener_arn=infra["alb_listener"],
action=[LbListenerRuleAction(type="forward", target_group_arn=svc_tg.arn)],
condition=[
LbListenerRuleCondition(
path_pattern=LbListenerRuleConditionPathPattern(values=["/*"])
)
],
)
# create the ECR repository
repo = EcrRepository(
self,
params["app_name"],
image_scanning_configuration=EcrRepositoryImageScanningConfiguration(
scan_on_push=True
),
image_tag_mutability="MUTABLE",
name=params["app_name"],
)
EcrLifecyclePolicy(
self,
"this",
repository=repo.name,
policy=json.dumps(
{
"rules": [
{
"rulePriority": 1,
"description": "Keep last 10 images",
"selection": {
"tagStatus": "tagged",
"tagPrefixList": ["v"],
"countType": "imageCountMoreThan",
"countNumber": 10,
},
"action": {"type": "expire"},
},
{
"rulePriority": 2,
"description": "Expire images older than 3 days",
"selection": {
"tagStatus": "untagged",
"countType": "sinceImagePushed",
"countUnit": "days",
"countNumber": 3,
},
"action": {"type": "expire"},
},
]
}
),
)
# create the service log group
service_log_group = CloudwatchLogGroup(
self,
"svc_log_group",
name=params["app_name"],
retention_in_days=1,
)
ecs_assume_role = DataAwsIamPolicyDocument(
self,
"assume_role",
statement=[
{
"actions": ["sts:AssumeRole"],
"principals": [
{
"identifiers": ["ecs-tasks.amazonaws.com"],
"type": "Service",
},
],
},
],
)
# create the service execution role
service_execution_role = IamRole(
self,
"service_execution_role",
assume_role_policy=ecs_assume_role.json,
name=params["app_name"] + "-exec-role",
)
IamRolePolicyAttachment(
self,
"ecs_role_policy",
policy_arn="arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy",
role=service_execution_role.name,
)
# create the service task role
service_task_role = IamRole(
self,
"service_task_role",
assume_role_policy=ecs_assume_role.json,
name=params["app_name"] + "-task-role",
)
# create the service task definition
task = EcsTaskDefinition(
self,
"svc-task",
family="service",
network_mode="awsvpc",
requires_compatibilities=["FARGATE"],
cpu="256",
memory="512",
task_role_arn=service_task_role.arn,
execution_role_arn=service_execution_role.arn,
container_definitions=json.dumps(
[
{
"name": "svc",
"image": f"{repo.repository_url}:latest",
"networkMode": "awsvpc",
"healthCheck": {
"Command": ["CMD-SHELL", "echo hello"],
"Interval": 5,
"Timeout": 2,
"Retries": 3,
},
"portMappings": [
{
"containerPort": params["app_port"],
"hostPort": params["app_port"],
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": service_log_group.name,
"awslogs-region": params["region"],
"awslogs-stream-prefix": params["app_name"],
},
},
}
]
),
)
# create the ECS service
EcsService(
self,
"ecs_service",
name=params["app_name"] + "-service",
cluster=infra["cluster_id"],
task_definition=task.arn,
desired_count=params["desired_count"],
launch_type="FARGATE",
force_new_deployment=True,
network_configuration=EcsServiceNetworkConfiguration(
subnets=network["private_subnets"],
security_groups=[svc_sg.id],
),
load_balancer=[
EcsServiceLoadBalancer(
target_group_arn=svc_tg.id,
container_name="svc",
container_port=params["app_port"],
)
],
)
TerraformOutput(
self,
"ecr_repository_url",
description="url of the ecr repo",
value=repo.repository_url,
)

Schritt 4: GitHub Action Workflow
Um Bereitstellungen zu automatisieren, integrieren wir einen Workflow von GitHub-Aktionen in unser java-api . Nach dem Aktivieren von GitHub -Aktionen erstellen Sie die Geheimnisse und Variablen für Ihr Repository, erstellen Sie die Datei .github/Workflows/Deploy.yml und fügen Sie den folgenden Inhalt hinzu:
FROM maven:3.9-amazoncorretto-21 AS builder WORKDIR /app COPY pom.xml . COPY src src RUN mvn clean package # amazon java distribution FROM amazoncorretto:21-alpine COPY --from=builder /app/target/*.jar /app/java-api.jar EXPOSE 8080 ENTRYPOINT ["java","-jar","/app/java-api.jar"]
Unser Workflow funktioniert gut:

Der Dienst wurde erfolgreich bereitgestellt, wie im Bild unten gezeigt:

Schritt 5: Validieren Sie die Bereitstellung
Testen Sie Ihre Bereitstellung mit dem folgenden Skript ( Ersetzen Sie die AlB -URL durch Ihre ):
- [**python (3.13)**](https://www.python.org/) - [**pipenv**](https://pipenv.pypa.io/en/latest/) - [**npm**](https://nodejs.org/en/)
Der ALB ist jetzt bereit, Verkehr zu servieren!
endgültige Gedanken
Durch die Nutzung von AWS -CDKTF können wir mit Python sauberen, wartenable IAC -Code schreiben. Dieser Ansatz vereinfacht die Bereitstellung von Containeranwendungen wie eine Spring -Boot -API auf AWS ECS Fargate.
CDKTFs Flexibilität in Kombination mit den robusten Funktionen von Terraform ist eine hervorragende Wahl für moderne Cloud -Bereitstellungen.
Während das CDKTF -Projekt viele interessante Funktionen für das Infrastrukturmanagement bietet, muss ich zugeben, dass ich es manchmal etwas zu ausführlich finde.
Haben Sie Erfahrung mit CDKTF? Haben Sie es in der Produktion verwendet?
Sie können Ihre Erfahrungen mit uns teilen.
Das obige ist der detaillierte Inhalt vonWie stellt man mit CDKTF eine SpringBoot-API auf AWS ECS bereit?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1673
1673
 14
1428
52
1333
25
1277
29
1257
24
14
1428
52
1333
25
1277
29
1257
24

 Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python ist leichter zu lernen und zu verwenden, während C leistungsfähiger, aber komplexer ist. 1. Python -Syntax ist prägnant und für Anfänger geeignet. Durch die dynamische Tippen und die automatische Speicherverwaltung können Sie die Verwendung einfach zu verwenden, kann jedoch zur Laufzeitfehler führen. 2.C bietet Steuerung und erweiterte Funktionen auf niedrigem Niveau, geeignet für Hochleistungsanwendungen, hat jedoch einen hohen Lernschwellenwert und erfordert manuellem Speicher und Typensicherheitsmanagement.
 Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Ist es genug, um Python für zwei Stunden am Tag zu lernen? Es hängt von Ihren Zielen und Lernmethoden ab. 1) Entwickeln Sie einen klaren Lernplan, 2) Wählen Sie geeignete Lernressourcen und -methoden aus, 3) praktizieren und prüfen und konsolidieren Sie praktische Praxis und Überprüfung und konsolidieren Sie und Sie können die Grundkenntnisse und die erweiterten Funktionen von Python während dieser Zeit nach und nach beherrschen.
 Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python ist in der Entwicklungseffizienz besser als C, aber C ist in der Ausführungsleistung höher. 1. Pythons prägnante Syntax und reiche Bibliotheken verbessern die Entwicklungseffizienz. 2. Die Kompilierungsmerkmale von Compilation und die Hardwarekontrolle verbessern die Ausführungsleistung. Bei einer Auswahl müssen Sie die Entwicklungsgeschwindigkeit und die Ausführungseffizienz basierend auf den Projektanforderungen abwägen.
 Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python und C haben jeweils ihre eigenen Vorteile, und die Wahl sollte auf Projektanforderungen beruhen. 1) Python ist aufgrund seiner prägnanten Syntax und der dynamischen Typisierung für die schnelle Entwicklung und Datenverarbeitung geeignet. 2) C ist aufgrund seiner statischen Tipp- und manuellen Speicherverwaltung für hohe Leistung und Systemprogrammierung geeignet.
 Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
PythonlistsarePartThestandardlibrary, whilearraysarenot.listarebuilt-in, vielseitig und UNDUSEDFORSPORINGECollections, während dieArrayRay-thearrayModulei und loses und loses und losesaluseduetolimitedFunctionality.
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Python für wissenschaftliches Computer: Ein detailliertes Aussehen
Apr 19, 2025 am 12:15 AM
Python für wissenschaftliches Computer: Ein detailliertes Aussehen
Apr 19, 2025 am 12:15 AM
Zu den Anwendungen von Python im wissenschaftlichen Computer gehören Datenanalyse, maschinelles Lernen, numerische Simulation und Visualisierung. 1.Numpy bietet effiziente mehrdimensionale Arrays und mathematische Funktionen. 2. Scipy erweitert die Numpy -Funktionalität und bietet Optimierungs- und lineare Algebra -Tools. 3.. Pandas wird zur Datenverarbeitung und -analyse verwendet. 4.Matplotlib wird verwendet, um verschiedene Grafiken und visuelle Ergebnisse zu erzeugen.
 Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Zu den wichtigsten Anwendungen von Python in der Webentwicklung gehören die Verwendung von Django- und Flask -Frameworks, API -Entwicklung, Datenanalyse und Visualisierung, maschinelles Lernen und KI sowie Leistungsoptimierung. 1. Django und Flask Framework: Django eignet sich für die schnelle Entwicklung komplexer Anwendungen, und Flask eignet sich für kleine oder hochmobile Projekte. 2. API -Entwicklung: Verwenden Sie Flask oder Djangorestframework, um RESTFUFFUPI zu erstellen. 3. Datenanalyse und Visualisierung: Verwenden Sie Python, um Daten zu verarbeiten und über die Webschnittstelle anzuzeigen. 4. Maschinelles Lernen und KI: Python wird verwendet, um intelligente Webanwendungen zu erstellen. 5. Leistungsoptimierung: optimiert durch asynchrones Programmieren, Caching und Code
