
 Technologie-Peripheriegeräte
KI
Entwicklung eines KI-betriebenen Smart-Leitfadens für Geschäftsplanung und Unternehmertum
Technologie-Peripheriegeräte
KI
Entwicklung eines KI-betriebenen Smart-Leitfadens für Geschäftsplanung und Unternehmertum
Entwicklung eines KI-betriebenen Smart-Leitfadens für Geschäftsplanung und Unternehmertum

Wenn Sie kein mittleres Mitglied sind, können Sie die vollständige Geschichte unter diesem Link lesen.
Nach dem Start von ChatGPT und dem folgenden Anstieg großer Sprachmodelle (LLMs), ihren inhärenten Einschränkungen der Halluzination, des Datum des Wissens Cutoffs und der Unfähigkeit, organisatorische oder personenbezogene Informationen bereitzustellen, wurden bald offensichtlich und wurden als Hauptfach angesehen Nachteile. Um diese Probleme anzugehen, hat Abrufenvergrößerungsmethoden (RAG) -Methoden (RAGS -Erzeugung) bald an Traktion gewonnen, die externe Daten in LLMs integrieren und ihr Verhalten leiten, um Fragen aus einer bestimmten Wissensbasis zu beantworten.
Interessanterweise wurde das erste Papier über Rag im Jahr 2020 von Forschern von Facebook AI Research (jetzt Meta AI) veröffentlicht, aber erst als das Aufkommen von Chatgpt wurde sein Potenzial vollständig verwirklicht. Seitdem gab es kein Stopp. Es wurden fortschrittlichere und komplexere RAG -Frameworks eingeführt, die nicht nur die Genauigkeit dieser Technologie verbesserten, sondern es auch ermöglichten, multimodale Daten zu behandeln und das Potenzial für eine Vielzahl von Anwendungen zu erweitern. Ich habe in den folgenden Artikeln zu diesem Thema ausführlich geschrieben und speziell über kontextbezogene multimodale Lappen, multimodale KI -Suche nach Geschäftsanwendungen sowie Informationsextraktion und Matchmaking -Plattformen diskutiert.
Mit der wachsenden Landschaft der Lagentechnologie und den aufstrebenden Datenzugriffsanforderungen wurde erkannt, dass die Funktionalität eines Retriever-Rags, der Fragen aus einer statischen Wissensbasis beantwortet, durch die Integration anderer verschiedener Wissensquellen und -werkzeuge erweitert werden kann wie:Integrieren multimodaler Daten in ein großes Sprachmodell
multimodale KI -Suche nach Geschäftsanwendungen
AI-betriebene Informationsextraktion und Matchmaking
- Mehrere Datenbanken (z. B. Wissensbasis, die Vektordatenbanken und Wissensgraphen umfassen)
- Echtzeit-Websuche, um auf aktuelle Informationen zuzugreifen
- externe APIs zum Sammeln spezifischer Daten wie Börsentrends oder Daten von unternehmensspezifischen Tools wie Slack-Kanälen oder E-Mail-Konten
- Tools für Aufgaben wie Datenanalyse, Berichtsschreiben, Literaturrecherche und Personensuche usw.
- Vergleich und Konsolidieren von Informationen aus mehreren Quellen.
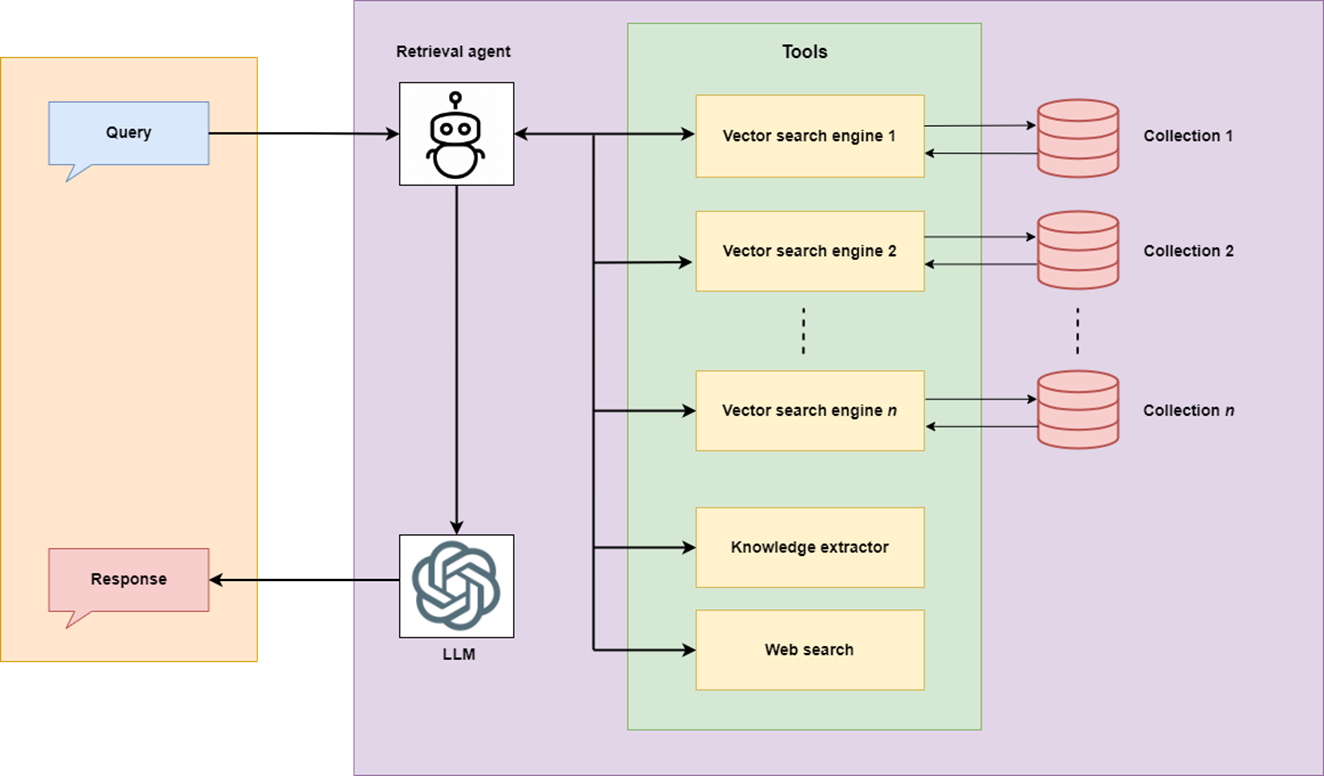 Um dies zu erreichen, sollte ein Lappen in der Lage sein, die beste Wissensquelle und/oder das Werkzeug basierend auf der Abfrage auszuwählen. Die Entstehung von AI -Agenten führte die Idee von "
Um dies zu erreichen, sollte ein Lappen in der Lage sein, die beste Wissensquelle und/oder das Werkzeug basierend auf der Abfrage auszuwählen. Die Entstehung von AI -Agenten führte die Idee von "Agentic Rag " ein, die die beste Vorgehensweise basierend auf der Abfrage auswählen könnte.
In diesem Artikel werden wir eine bestimmte Agenten -Lag -Anwendung entwickeln, die als Smart Business Guide (SBG) bezeichnet wird - Die erste Version des Tools, das Teil unseres laufenden Projekts namens namens ist Optimistisch, finanziert von Interreg Central Baltic. Das Projekt konzentriert sich auf die Aufwanderung von Einwanderern in Finnland und Estland für Unternehmertum und Geschäftsplanung mit AI. SBG ist eines der Tools, die für den Upskilling -Prozess dieses Projekts verwendet werden sollen. Dieses Tool konzentriert sich auf die Bereitstellung genauer und schneller Informationen von authentischen Quellen an Personen, die beabsichtigen, ein Unternehmen zu gründen, oder denjenigen, die bereits Geschäfte machen.
Der Agentenlappen des SBG umfasst:
- Geschäfts- und Unternehmertum als Wissensbasis mit Informationen zu Geschäftsplanung, Unternehmertum, Registrierung von Unternehmen, Besteuerung, Geschäftsideen, Regeln und Vorschriften, Geschäftsmöglichkeiten, Lizenzen und Genehmigungen, Geschäftsrichtlinien und anderen.
- Websuche, um aktuelle Informationen mit Quellen zu holen.
- Wissensextraktionstools zum Abrufen von Informationen aus vertrauenswürdigen Quellen. Diese Informationen umfassen Kontakte relevanter Behörden, jüngste Besteuerungsregeln, jüngste Regeln für Unternehmensregistrierung und jüngste Lizenzvorschriften.
Was ist das Besondere an diesem Agenten -Lappen?
- Option zur Auswahl unterschiedliche Open-Source-Modelle ( lama, Mistral, Gemma ) ** sowie proprietäres Modell s _ (GPT (GPT) (GPT (GPT) -4o, gpt-4o-min_i) im gesamten agenten-Workflow. Die Open-Source-Modelle laufen nicht lokal und erfordern daher keine leistungsstarke, teure Computermaschine. Stattdessen laufen sie mit einem COQ Cloud von m mit einem freien AP i. Und ja, das macht es zu einem cost-free ** e Agentenlag. Die GPT -Modelle können auch mit einem OpenAI -API -Schlüssel ausgewählt werden.
- Optionen zur Durchsetzung von Wissenssuche, Websuche und Hybridsuche.
- Einstufung von abgerufenen Dokumenten zur Verbesserung der Antwortqualität und intelligent auf Websuche basierend auf der Einstufung.
- Optionen zum Auswählen des Antworttyp Speziell ist der Artikel um die folgenden Themen strukturiert: Daten analysieren, um die Wissensbasis mit Lamaparse
Entwickeln eines agierenden Workflows mit Langgraph. Entwicklung eines fortschrittlichen Agentenlappen (im Folgenden namens Smart Business Guide oder SBG) mit kostenlosen Open-Source-Modellen
- Der gesamte Code dieser Anwendung ist auf GitHub zu finden.
streamlit grafische Benutzeroberfläche. Lassen Sie uns in sie eintauchen.
Wissensbasis mit Lamaparsing und Langchain
konstruierenDie Wissensbasis des SBG umfasst authentische Geschäfts- und Unternehmertumführer, die von finnischen Agenturen veröffentlicht wurden. Da diese Leitfäden voluminös sind und eine erforderliche Information von ihnen zu finden ist, ist es nicht trivial, einen Agentenlappen zu entwickeln, der nicht nur genaue Informationen von diesen Leitfäden liefern kann, sondern sie auch durch eine Websuche und andere vertrauenswürdige Quellen in den Finnland für aktualisierte Informationen.
llamaparse ist eine genai-native Dokument-Parsing-Plattform mit LLMs und für LLM-Anwendungsfälle. Ich habe die Verwendung von Llamaparse in den oben genannten Artikeln erklärt. Diesmal habe ich die Dokumente direkt in Lamacloud analysiert. Llamaparse bietet 1000 kostenlose Credits pro Tag an. Die Verwendung dieser Credits hängt vom Parsing -Modus ab. Für Text-Nur-Text-PDF funktioniert „ Fast “ -Modus (1 Kredit / 3 Seiten) gut, die OCR, Bildextraktion und Tabelle / Überschrift Identifikation übersprungen. Es sind weitere erweiterte Modi mit einer höheren Anzahl von Kreditpunkten pro Seite verfügbar. Ich habe den Modus „ Premium
“ ausgewählt, der OCR, Bildextraktion und Tabelle/Überschrift Identifikation ausführt und ideal für komplexe Dokumente mit Bildern ist.Ich habe die folgenden Parsing -Anweisungen definiert.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Die analysierten Dokumente wurden im Markdown -Format aus Lamacloud heruntergeladen. Das gleiche Parsen kann durch Lamacloud -API wie folgt durchgeführt werden.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Hier ist eine Beispielseite aus der Kreativität und des Geschäfts von Leitfaden von Pikkala, A. et al., (2015) (" kostenlos kopieren für nichtkommerzielle private oder öffentliche Verwendung mit Attribution
").
Hier ist die analysierte Ausgabe dieser Seite. Lamaparse extrahierte Informationen aus allen Strukturen auf der Seite effizient. Das in der Seite gezeigte Notizbuch befindet sich im Bildformat.
[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
Die analysierten Markdown -Dokumente werden dann unter Verwendung von Langchains recursivecharactertextSPSPLITTERT
mit chunk_size = 3000 und chunk_overlap = 200.def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docsAnschließend wird ein VectorStore in der Chroma-Datenbank unter Verwendung eines Einbettungsmodells wie Open-Source All-Minilm-L6-V2 -Modell oder OpenAIs textembeding-3-large
erstellt .def load_or_create_vs(persist_directory):
# Check if the vector store directory exists
if os.path.exists(persist_directory):
print("Loading existing vector store...")
# Load the existing vector store
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=st.session_state.embed_model,
collection_name=collection_name
)
else:
print("Vector store not found. Creating a new one...n")
docs = staticChunker(DATA_FOLDER)
print("Computing embeddings...")
# Create and persist a new Chroma vector store
vectorstore = Chroma.from_documents(
documents=docs,
embedding=st.session_state.embed_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print('Vector store created and persisted successfully!')
return vectorstoreagenten -Workflow erstellen
Ein AI-Agent ist die Kombination des Workflows und der Entscheidungslogik, um Fragen intelligent zu beantworten oder andere komplexe Aufgaben auszuführen, die in einfachere Unteraufgaben unterteilt werden müssen.
Ich habe Langgraph verwendet, um einen Workflow für unseren AI -Agenten für die Abfolge von Aktionen oder Entscheidungen in Form eines Diagramms zu entwerfen. Unser Agent muss entscheiden, ob die Frage aus der Vektor -Datenbank (Wissensbasis), Websuche, Hybridsuche oder mithilfe eines Tools beantwortet werden soll.
In meinem folgenden Artikel habe ich den Prozess des Erstellens eines agierenden Workflows mit Langgraph erläutert.
So entwickeln Sie einen kostenlosen AI -Agenten mit automatischer Internetsuche
Wir müssen Graph Knoten erstellen, die einen Workflow darstellen, um Entscheidungen zu treffen (z. B. Websuche oder Vektor -Datenbanksuche). Die Knoten sind durch Kanten verbunden, die den Entscheidungsfluss und Handlungen definieren (z. B. was ist der nächste Zustand nach dem Abrufen). Das Diagramm Status verfolgt die Informationen, die sich durch den Diagramm bewegt, so dass der Agent die richtigen Daten für jeden Schritt verwendet.
Der Einstiegspunkt im Workflow ist eine Routerfunktion, die den anfänglichen Knoten bestimmt, der im Workflow ausgeführt wird, indem die Abfrage des Benutzers analysiert wird. Der gesamte Workflow enthält die folgenden Knoten.
- abrufen : semantisch ähnliche Informationsbrocken aus dem Vectorstore abrufen.
- _ addocuments _: Grade Die Relevanz von abgerufenen Brocken basierend auf der Abfrage des Benutzers.
- _ Route_after_grading _: Basierend auf der Bewertung bestimmt, ob eine Antwort mit den abgerufenen Dokumenten genreiert werden soll oder mit der Websuche fortgesetzt werden soll.
- WebSearch : Abrufen Informationen aus Webquellen mithilfe der API von Tavily Suchmaschine.
- Generieren Sie : generiert eine Antwort auf die Abfrage des Benutzers mit dem bereitgestellten Kontext (Informationen, die aus dem Vektorspeicher und/oder der Websuche abgerufen wurden).
- _ get_contact_tool _: holt Kontaktinformationen von vordefinierten vertrauenswürdigen URLs im Zusammenhang mit finnischen Einwanderungsdiensten ab.
- _ get_tax_info _: ruft steuerbezogene Informationen von vordefinierten vertrauenswürdigen URLs ab.
- _ get_registration_info _: Ruft Details zu Unternehmensregistrierungsprozessen in Finnland aus vordefinierten vertrauenswürdigen URLs ab.
- _ get_licensing_info _: Fetches Informationen zu Lizenzen und Genehmigungen, die für die Start eines Unternehmens in Finnland erforderlich sind.
- _ hybrid_search _: kombiniert das Abrufen von Dokumenten und die Internet -Suchergebnisse, um einen breiteren Kontext für die Beantwortung der Abfrage bereitzustellen.
- nicht verwandt : Fragen, die nicht mit dem Fokus des Workflows zu tun haben
Hier sind die Kanten im Workflow.
- _ abrufen → grade_documents _: Abgerufene Dokumente werden zur Bewertung gesendet.
- _ adr. _ adr.
- WebSearch → Generieren
- : Übergibt die Ergebnisse der Websuche für die Antwortgenerierung. _get_contact_tool, get_tax info , _get_registration
- info , _get_licensing Info → Generieren : Die Kanten aus diesen vier Tools zu to generieren Generieren Sie Knoten über die abgerufenen Informationen aus bestimmten vertrauenswürdigen Quellen für die Reaktionsgenerierung. _hybrid such
- → Generieren : Übergibt die kombinierten Ergebnisse (VectorStore WebSearch) zur Antwortgenerierung. nicht verwandt
- → Erzeugen : Bietet eine Fallback -Antwort für nicht verwandte Fragen. Eine Grafikzustandsstruktur fungiert als Container für die Aufrechterhaltung des Zustands des Arbeitsablaufs und enthält die folgenden Elemente:
- Frage
- : Die Abfrage oder Eingabe des Benutzers, die den Workflow antreibt. Erzeugung
- : Die endgültige generierte Antwort auf die nach der Verarbeitung besiedelte Nutzerabfrage. _ web_search_needed _: Ein Flag, das angibt, ob eine Websuche basierend auf der Relevanz abgerufener Dokumente erforderlich ist.
- Dokumente
- : Eine Liste von abgerufenen oder verarbeiteten Dokumenten, die für die Abfrage relevant sind. _ Antwort_Style _: Gibt den gewünschten Stil der Antwort an, wie "prägnant", "moderat" oder "erklärend".
- Die Grafikzustandsstruktur ist wie folgt definiert:
Nachfolger der Router -Funktion analysiert die Abfrage und leitet sie zur Verarbeitung an einen relevanten Knoten weiter. Es wird eine Kette erstellt, die eine Eingabeaufforderung umfasst, um einen Werkzeug/Knoten aus einem Werkzeugauswahlwörterbuch und der Abfrage auszuwählen. Die Kette ruft einen Router LLM an, um das relevante Werkzeug auszuwählen.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Die Fragen, die für den Workflow nicht relevant sind
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)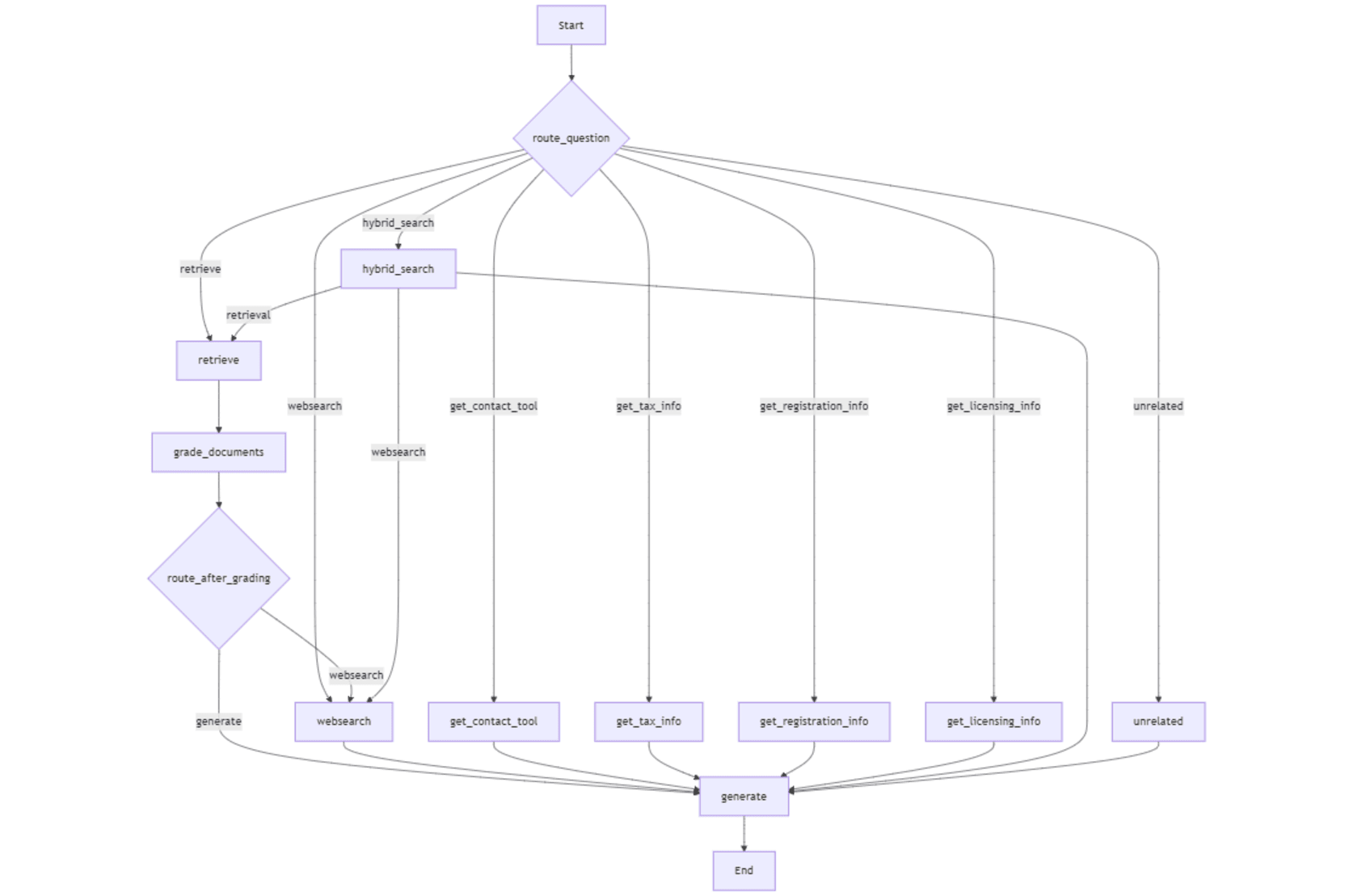
Abruf und Bewertung
Der -Aring Knoten ruft den Retriever mit der Frage auf, um relevante Informationsbrocken aus dem Vektorspeicher abzurufen. Diese Brocken (" Dokumente ") werden an den _grade -Dokumente Knoten gesendet, um ihre Relevanz zu bewerten. Basierend auf den abgestuften Brocken ("_Filtered docs ") entscheidet der _route_after -Regstortierung , ob mit den abgerufenen Informationen mit den abgerufenen Informationen fortfahren oder auf Web -Suche aufgerufen werden soll. Die Helferfunktion _initialize_Ger Kette initialisiert die Graderkette mit einer Eingabeaufforderung, die den LLM der Grader leitet, um die Relevanz jedes Stücks zu bewerten. Die _grade dokumentiert Knoten analysiert jeden Chunk, um festzustellen, ob es für die Frage relevant ist. Für jeden Chunk gibt es " Ja " oder " nein " aus, je nachdem, ob der Stadium für die Frage relevant ist.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Web und Hybridsuche
Der _web such Knoten wird entweder durch _route_after bewertet Knoten, wenn in den abgerufenen Informationen keine relevanten Teile gefunden werden, oder direkt von _Route Frage Knoten, wenn Entweder _internet_search aktiviert Status -Flag ist " true " (ausgewählt von der ausgewählt Optionsschaltfläche in der Benutzeroberfläche) oder die Router -Funktion beschließt, die Abfrage an _web such zu leiten, um aktuelle und relevantere Informationen abzurufen.
Die kostenlose API der Suchmaschinen von der Suchmaschine kann durch Erstellen eines Kontos auf ihrer Website erhalten werden. Der kostenlose Plan bietet 1000 Kreditpunkte pro Monat. Tavily Suchergebnisse werden an die Statusvariable "document " angehängt, die dann an übergeben wird Knoten mit der Statusvariablen " Frage ".
Hybridsuche kombiniert die Ergebnisse von Retriever und Tavy -Suche "Dokument " Statusvariable, die zum Generieren von Knoten mit " Frage " Statusvariable übergeben wird. .
.import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Invoching -Tools
Die in diesem Agenten -Workflow verwendeten Tools sind die Schrottfunktionen, um Informationen von vordefinierten vertrauenswürdigen URLs abzurufen. Der Unterschied zwischen Tavily und diesen Tools besteht darin, dass Tavily eine breitere Internetsuche ausführt, um Ergebnisse aus verschiedenen Quellen zu erzielen. Diese Tools verwenden Pythons wunderschöne Suppennetzbibliothek, um Informationen aus vertrauenswürdigen Quellen (vordefinierte URLs) zu extrahieren. Auf diese Weise stellen wir sicher, dass die Informationen zu bestimmten Fragen aus bekannten, vertrauenswürdigen Quellen extrahiert werden. Darüber hinaus ist dieses Informationsabruf völlig kostenlos.
Hier ist, wie _get_tax Info Knoten mit einigen Helferfunktionen funktioniert. Die anderen Tools (Knoten) dieses Typs funktionieren ebenfalls auf die gleiche Weise.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
reagieren
generierenDer Knoten, erzeugt , erstellt die endgültige Antwort, indem er eine Kette mit einer vordefinierten Eingabeaufforderung (Langchains promptTemplate Klasse) aufgerufen wird. Die _rag Eingabeaufforderung empfängt die Statusvariablen _ "Questio n", "condex t" und "Antwort_styl_e" und führt die gesamte Verhalten der Antwortgenerierung einschließlich Anweisungen zum Antwortstil, dem Gesprächston, der Formatierung von Richtlinien, Zitierregeln, hybriden Kontexthandhabung und Nur-Kontext-Nur-Kontext Fokus.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Der erzeugen Knoten ruft zuerst die Zustandsvariablen " Frage ", " Dokumente " und "_answer style " und Formate ab Die " dokumentiert " in eine einzelne Zeichenfolge, die als Kontext dient. Anschließend ruft es die Erzeugungskette mit _grag Eingabeaufforderung und einer Antwortgenerierung LLM _ auf, um die endgültige Antwort zu generieren, die in "Generatio_N" -Abgleisvariable besiedelt ist. Diese Statusvariable wird von _app.p_y verwendet, um die generierte Antwort in der Benutzeroberfläche streamlit zu zeigen.
Mit der freien API von GREQ besteht die Möglichkeit, die Rate- oder Kontextfenstergrenze eines Modells zu erreichen. In diesem Fall habe ichKnoten erweitert, um die Modelle dynamisch aus der Liste der Modellnamen zu schalten und nach der Generierung der Antwort zum aktuellen Modell zurückzukehren. .
[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
Helferfunktionen
Es gibt andere hilfsbereite Funktionen in _agentischer rag.py für die Initialisierung von Anwendungen, LLMs, Einbettungsmodellen und Sitzungsvariablen. Die Funktion _initialize app wird während der App -Initialisierung app.py aufgerufen und __ wird jedes Mal ausgelöst, wenn eine Modell- oder Statusvariable über die streamlit App geändert wird. Es initialisiert die Komponenten neu und speichert die aktualisierten Zustände. Diese Funktion verfolgt auch verschiedene Sitzungsvariablen und verhindert eine redundante Initialisierung.
def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docsDie folgenden Helferfunktionen initialisieren ein antwortendes LLM, ein Einbettungsmodell, ein Router LLM und die Bewertung von LLM. Die Liste der Modellnamen _model list wird verwendet, um die Modelle während des dynamischen Wechsels von Modellen durch zu verfolgen Knoten.
def load_or_create_vs(persist_directory):
# Check if the vector store directory exists
if os.path.exists(persist_directory):
print("Loading existing vector store...")
# Load the existing vector store
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=st.session_state.embed_model,
collection_name=collection_name
)
else:
print("Vector store not found. Creating a new one...n")
docs = staticChunker(DATA_FOLDER)
print("Computing embeddings...")
# Create and persist a new Chroma vector store
vectorstore = Chroma.from_documents(
documents=docs,
embedding=st.session_state.embed_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print('Vector store created and persisted successfully!')
return vectorstoreErstellen des Workflows
Jetzt werden der Grafikzustand, die Knoten, die bedingten Einstiegspunkte mit _route Frage und Kanten definiert, um den Fluss zwischen Knoten zu ermitteln. Schließlich wird der Workflow in eine ausführbare App für die Verwendung in der streamlit -Schinnee zusammengestellt. Der Bedingungseinstiegspunkt im Workflow verwendet _route Frage , um den ersten Knoten im Workflow basierend auf der Abfrage auszuwählen. Die bedingte Kante (_WORKFLOW.ADD_CONDITIONAL Kanten ) beschreibt, ob der Übergang zu WebSearch oder zu basierend auf der Relevanz der durch _grade ermittelten -Klussen übergang Dokumente Knoten.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Die optimistische Schnittstelle
Die Streamlit-Anwendung in app.py bietet eine interaktive Schnittstelle, mit der Fragen und Antworten mithilfe der dynamischen Einstellungen für die Modellauswahl, die Beantwortung von Stilen und abfragespezifische Tools angezeigt werden können. Die _initialize App -Funktion, importiert aus _agentic rag.py, initialisiert alle Sitzungsvariablen, einschließlich aller LLMs, des Einbettungsmodells und anderer Optionen aus der linken Seitenleiste.
Die Druckanweisungen in _agentic_rag.p_y werden durch Umleitung sys.stdout zu einem io.stringio erfasst. Der Inhalt dieses Puffers wird dann im Debug -Platzhalter verwendet, wobei die _text Bereich in streamlit.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)Hier ist der Schnappschuss der streamliten Schnittstelle:

Das folgende Bild zeigt die Antwort, die durch lama-3.3–70b-cayile mit " präzise" Antwortstil ausgewählt wurde. Der Abfragerouter (_Route Frage ) ruft die Retriever (Vektorsuche) auf und die Graderfunktion findet alle abgerufenen Brocken relevant. Daher wird eine Entscheidung, die Antwort durch zu generieren, Knoten generieren. Das folgende Bild zeigt die Antwort auf dieselbe Frage mit „
erklären “ Antwortstil. Wie in _Rag
“ Antwortstil. Wie in _Rag Eingabeaufforderung angewiesen, erarbeitet der LLM die Antwort mit weiteren Erklärungen. Das folgende Bild zeigt das Router -Auslöser _get_license
Info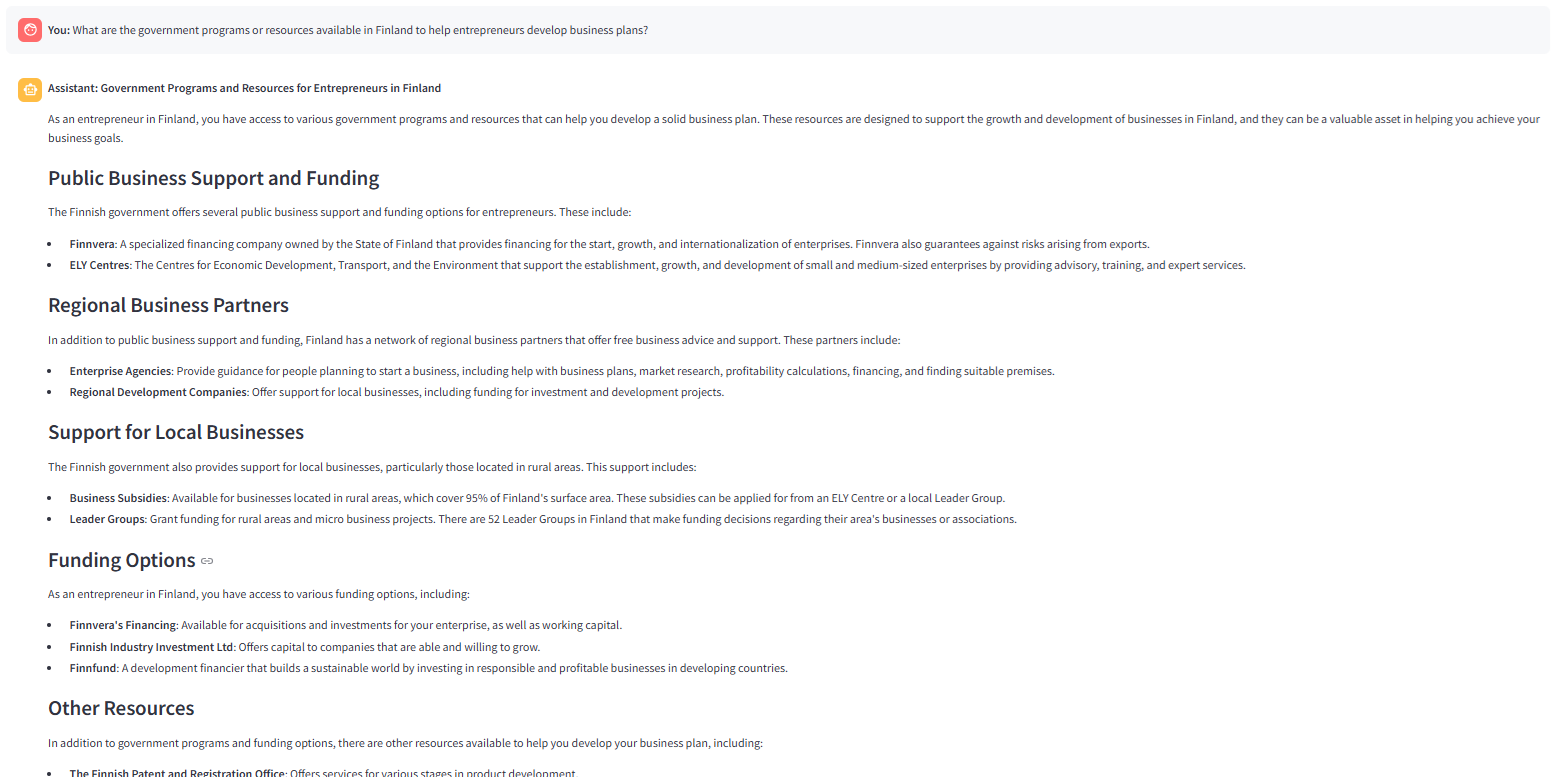 Tool als Antwort auf die Frage.
Tool als Antwort auf die Frage. Das folgende Bild zeigt eine Websuche, die von _route_after
bewertet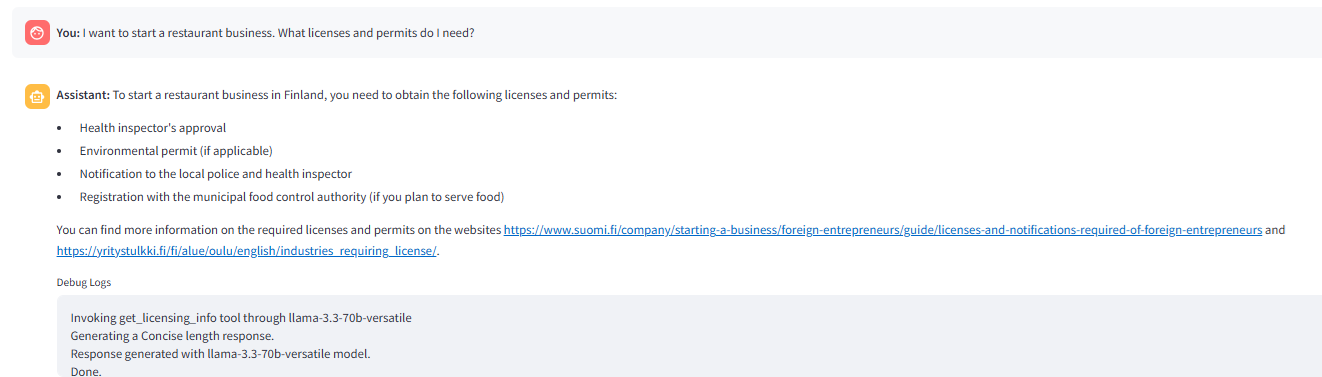 Knoten, wenn kein relevanter Chunk in der Vektorsuche gefunden wird.
Knoten, wenn kein relevanter Chunk in der Vektorsuche gefunden wird. Das folgende Bild zeigt die Antwort, die mit der Option Hybridsuche erzeugt wird, die in der Anwendung
streamlit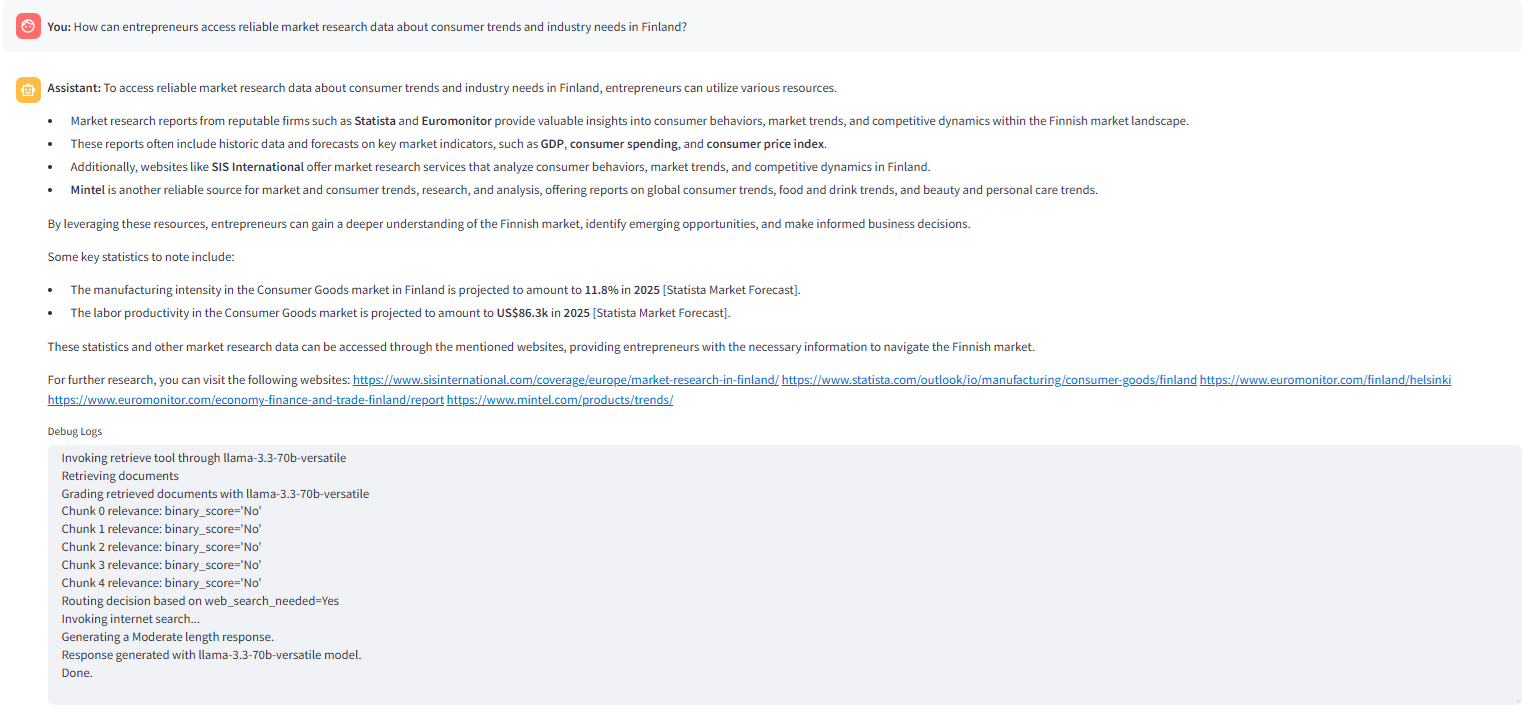 ausgewählt wurde. Der _Route
ausgewählt wurde. Der _Route QuStion -Knode findet das _internet_search aktiviert Status -Flag „ true „ und weiter Anweisungen für Erweiterung Diese Anwendung kann in mehreren Richtungen verbessert werden, z. B.
- Sprach-fähige Suche und Frage-Antwort in mehreren Sprachen (z. B. Russisch, Estnisch, Arabisch usw.)
- Auswählen verschiedener Teile einer Antwort und fragen Sie nach weiteren Informationen oder Erläuterungen.
- Speicher des letzten n Anzahl der Nachrichten hinzufügen.
- einschließlich anderer Modalitäten (wie z. B. der Bilder), in denen die fraglichen Antworten.
- Mehr Agenten für Brainstorming, Schreiben und Ideengenerierung hinzufügen.
Das sind alles Leute!
Das obige ist der detaillierte Inhalt vonEntwicklung eines KI-betriebenen Smart-Leitfadens für Geschäftsplanung und Unternehmertum. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1664
1664
 14
1423
52
1317
25
1268
29
1248
24
14
1423
52
1317
25
1268
29
1248
24

 Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Metas Lama 3.2: Ein Sprung nach vorne in der multimodalen und mobilen KI Meta hat kürzlich Lama 3.2 vorgestellt, ein bedeutender Fortschritt in der KI mit leistungsstarken Sichtfunktionen und leichten Textmodellen, die für mobile Geräte optimiert sind. Aufbau auf dem Erfolg o
 10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
Hey da, codieren Ninja! Welche Codierungsaufgaben haben Sie für den Tag geplant? Bevor Sie weiter in diesen Blog eintauchen, möchte ich, dass Sie über all Ihre Coding-Leiden nachdenken-die Auflistung auflisten diese auf. Erledigt? - Lassen Sie ’
 AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
Die KI -Landschaft dieser Woche: Ein Wirbelsturm von Fortschritten, ethischen Überlegungen und regulatorischen Debatten. Hauptakteure wie OpenAI, Google, Meta und Microsoft haben einen Strom von Updates veröffentlicht, von bahnbrechenden neuen Modellen bis hin zu entscheidenden Verschiebungen in LE
 Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Das jüngste Memo von Shopify -CEO Tobi Lütke erklärt kühn für jeden Mitarbeiter eine grundlegende Erwartung und kennzeichnet eine bedeutende kulturelle Veränderung innerhalb des Unternehmens. Dies ist kein flüchtiger Trend; Es ist ein neues operatives Paradigma, das in P integriert ist
 GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?
Apr 13, 2025 am 10:18 AM
GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?
Apr 13, 2025 am 10:18 AM
Einführung OpenAI hat sein neues Modell auf der Grundlage der mit Spannung erwarteten „Strawberry“ -Scharchitektur veröffentlicht. Dieses innovative Modell, bekannt als O1
 Ein umfassender Leitfaden zu Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Ein umfassender Leitfaden zu Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Einführung Stellen Sie sich vor, Sie gehen durch eine Kunstgalerie, umgeben von lebhaften Gemälden und Skulpturen. Was wäre, wenn Sie jedem Stück eine Frage stellen und eine sinnvolle Antwort erhalten könnten? Sie könnten fragen: „Welche Geschichte erzählst du?
 Neueste jährliche Zusammenstellung der besten technischen Techniken
Apr 10, 2025 am 11:22 AM
Neueste jährliche Zusammenstellung der besten technischen Techniken
Apr 10, 2025 am 11:22 AM
Für diejenigen unter Ihnen, die in meiner Kolumne neu sein könnten, erforsche ich allgemein die neuesten Fortschritte in der KI auf dem gesamten Vorstand, einschließlich Themen wie verkörpertes KI, KI-Argumentation, High-Tech
 3 Methoden zum Ausführen von LLAMA 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3 Methoden zum Ausführen von LLAMA 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
METAs Lama 3.2: Ein multimodales KI -Kraftpaket Das neueste multimodale Modell von META, Lama 3.2, stellt einen erheblichen Fortschritt in der KI dar, das ein verbessertes Sprachverständnis, eine verbesserte Genauigkeit und die überlegenen Funktionen der Textgenerierung bietet. Seine Fähigkeit t
