

Reft: Ein revolutionärer Ansatz zur Feinabstimmung LLMs
Reft (Repräsentation Fonetuning), eingeführt in Stanfords Papier im Mai 2024, bietet eine bahnbrechende Methode für effizient Feinabstimmungsmodelle (LLMs). Sein Potenzial wurde sofort erkennbar und wurde in nur 14 Minuten durch Oxen.
Im Gegensatz zu vorhandenen Parameter-effizienten Fine-Tuning-Methoden (PEFT) wie LORA, die Modellgewichte oder Eingabe modifizieren, nutzt REFT die Methode Distributed Interchange Intervention (DII). Dii-Projekte verbringen in einen niedrigerdimensionalen Unterraum und ermöglichen die Feinabstimmung durch diesen Unterraum.Dieser Artikel bewertet die beliebten PEFT -Algorithmen (Lora, sofortiges Tuning, Präfix -Tuning) und erklärt DII, bevor er sich in REFT und seine experimentellen Ergebnisse einleitet.

lora (Anpassung mit niedriger Rang): Eingeführt im Jahr 2021 hat Loras Einfachheit und Generalisierbarkeit eine führende Technik für feine StimmungslLMs und Diffusionsmodelle gemacht. Anstatt alle Schichtgewichte anzupassen, fügt LORA niedrige Matrizen hinzu, wodurch die trainierbaren Parameter (häufig weniger als 0,3%) reduziert, das Training beschleunigt und die Verwendung von GPU-Speicher minimiert.

Umkämpftes Tuning: Diese Methode verwendet "Soft-Eingabeaufforderungen"-larnierbare aufgabenspezifische Einbettung-als Präfixe, wodurch eine effiziente Vorhersage der Multitasking-Vorhersage ermöglicht wird, ohne das Modell für jede Aufgabe zu duplizieren. .
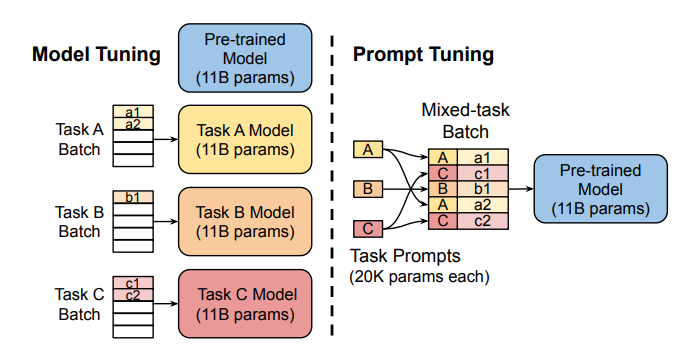
Präfix-Tuning (P-Tuning V2): Beschränkungen des schnellen Tunings im Maßstab addieren, und das Präfix-Tuning fügt zu verschiedenen Schichten zu trainierbaren Einbettungsdings hinzu und ermöglicht das aufgabenspezifische Lernen auf verschiedenen Ebenen.
.
Die Robustheit und Effizienz von Lora machen es zur am häufigsten verwendeten PEFT -Methode für LLMs. Ein detaillierter empirischer Vergleich findet sich in in diesem Papier
.Der DII -Prozess kann mathematisch als:
dargestellt werden 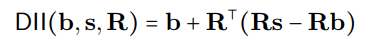
wobei R orthogonale Projektionen darstellt, und die verteilte Ausrichtungssuche (DAS) optimiert den Unterraum, um die Wahrscheinlichkeit der erwarteten kontrafaktischen Ausgänge nach der Intervention zu maximieren.
reft stellt die verborgene Darstellung des Modells innerhalb eines niedrigeren Raums ein. Die folgende Abbildung zeigt die Intervention (PHI), die auf Schicht L und Position P:
angewendet wird 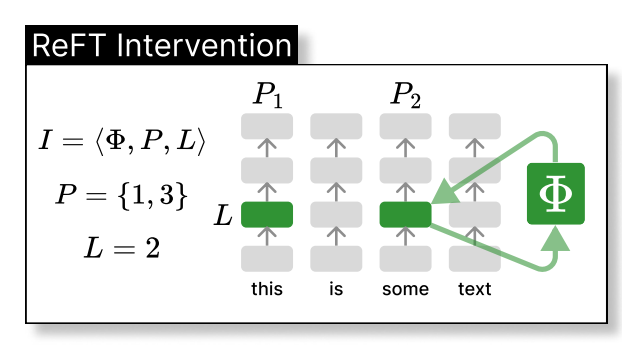
lorft (Low-Rank Linear Subspace Reft) führt eine erlernte projizierte Quelle ein:
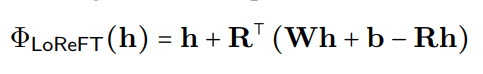
wobei h die verborgene Darstellung ist und Rs pittet h im niedrigdimensionalen Raum, der von R überspannt ist. Die Lorft -Integration in eine neuronale Netzwerkschicht ist unten dargestellt:
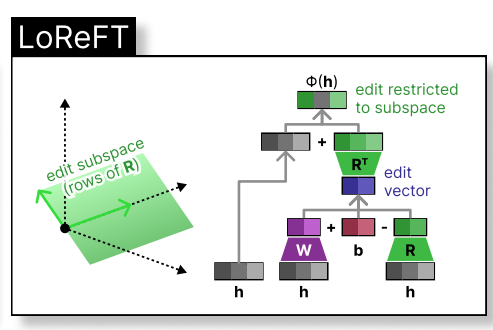
Während der Feinabstimmung der LLM bleiben die LLM-Parameter gefroren, und nur die Projektionsparameter (phi={R, W, b}).
Das ursprüngliche Reft-Papier präsentiert vergleichende Experimente gegen vollständige Feinabstimmungen (FT), Lora und Präfix-Stimmen über verschiedene Benchmarks. Übertechniken übertrieben vorhandene Methoden konsequent übertrieben, wodurch die Parameter um mindestens 90% reduziert werden und gleichzeitig eine überlegene Leistung erzielt werden.

Reft beruht auf seiner überlegenen Leistung mit Lama-Familie-Modellen für verschiedene Benchmarks und deren Grundlage in der kausalen Abstraktion, was die Modellinterpretierbarkeit unterstützt. REFT zeigt, dass ein linearer Unterraum, der über Neuronen verteilt ist, zahlreiche Aufgaben wirksam steuern kann und wertvolle Einblicke in LLMs bietet.
Das obige ist der detaillierte Inhalt vonIst Reft alles, was wir brauchten?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Kann pagefile.sys gelöscht werden?
Kann pagefile.sys gelöscht werden?
 So lösen Sie das Problem, dass der DNS-Server nicht reagiert
So lösen Sie das Problem, dass der DNS-Server nicht reagiert
 So kündigen Sie ein Douyin-Konto bei Douyin
So kündigen Sie ein Douyin-Konto bei Douyin
 Was passiert, wenn die IP-Adresse nicht verfügbar ist?
Was passiert, wenn die IP-Adresse nicht verfügbar ist?
 Was bedeutet Taobao b2c?
Was bedeutet Taobao b2c?
 Bitcoin-Handelsplattform
Bitcoin-Handelsplattform
 Die drahtlose Netzwerkkarte kann keine Verbindung herstellen
Die drahtlose Netzwerkkarte kann keine Verbindung herstellen
 Was ist Systemsoftware?
Was ist Systemsoftware?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



