

Enthüllen Sie die Magie hinter Großsprachemodellen (LLMs): eine zweiteilige Erkundung
große Sprachmodelle (LLMs) erscheinen oft magisch, aber ihre inneren Arbeiten sind überraschend systematisch. Diese zweiteilige Serie Demystifies LLMs erklärt ihre Konstruktion, Ausbildung und Verfeinerung in die KI-Systeme, die wir heute verwenden. Inspiriert von Andrej Karpathys aufschlussreichem (und langwierigem!) YouTube -Video bietet diese kondensierte Version die Kernkonzepte in einem zugänglicheren Format. Während das Video von Karpathy dringend empfohlen wird (800.000 Aufrufe in nur 10 Tagen!) Destilliert diese 10-minütige Lektüre die wichtigsten Imbissbuden aus den ersten 1,5 Stunden.
Teil 1: Von Rohdaten zum Basismodell
LLM-Entwicklung beinhaltet zwei wichtige Phasen: Vorausbildung und Nachtraining.
1. Vorabbildung: Die Sprache unterrichten
Vor dem Erstellen von Text muss ein LLM die Sprachstruktur lernen. Dieser rechnerisch intensive Vorbildungsprozess umfasst mehrere Schritte:
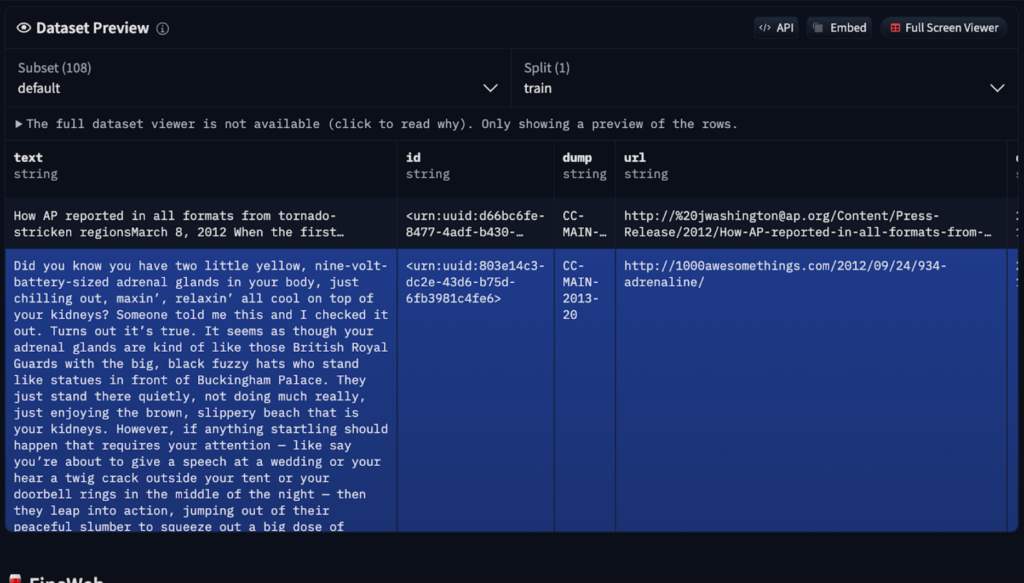
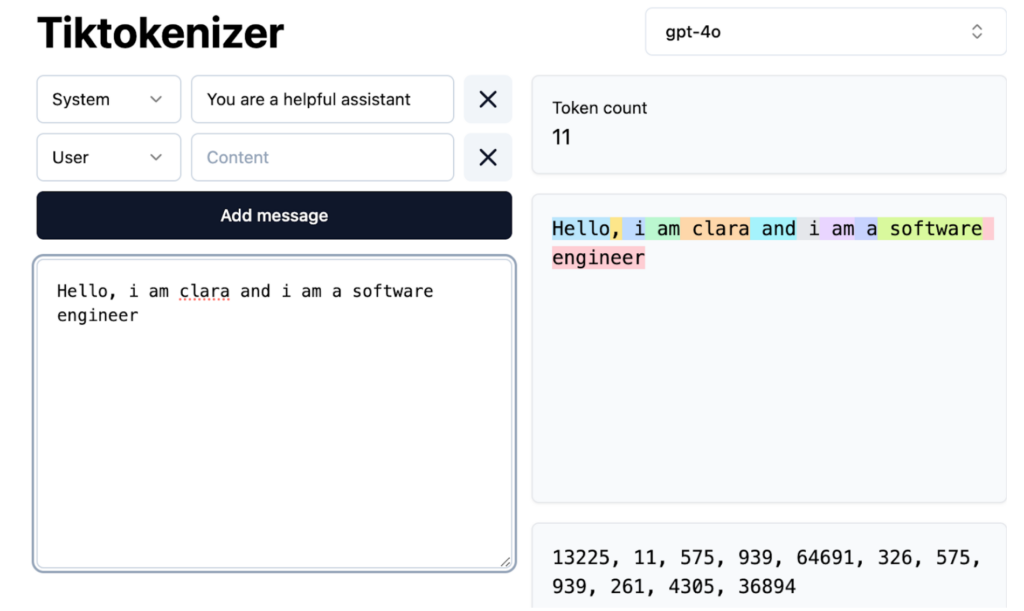
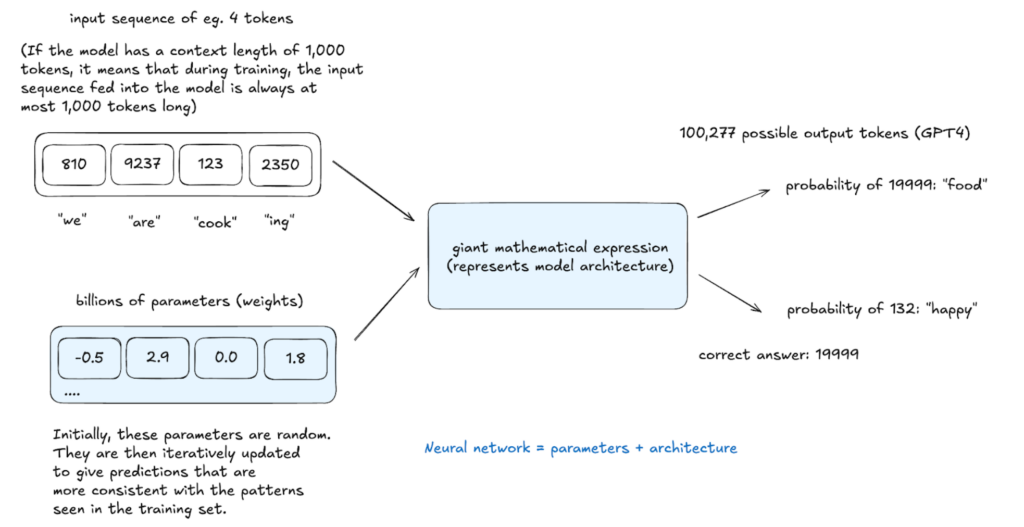
Das resultierende Basismodell versteht Wortbeziehungen und statistische Muster, fehlt jedoch die optimale reale Aufgabenoptimierung. Es funktioniert wie eine fortgeschrittene Autocomplete, die aufgrund der Wahrscheinlichkeit, jedoch mit begrenzten Funktionen für Anweisungen, vorhersagt. In-Kontext-Lernen, bei denen Beispiele innerhalb der Eingabeaufforderungen verwendet werden, können verwendet werden, aber weitere Schulungen sind erforderlich.
2. Nach der Schulung: Verfeinerung der praktischen Verwendung
Basismodelle werden durch Nachtraining mit kleineren, spezialisierten Datensätzen verfeinert. Dies ist keine explizite Programmierung, sondern implizite Anweisungen durch strukturierte Beispiele.
nach dem Training gehören:
spezielle Token werden eingeführt, um Benutzereingaben und AI -Antworten abzugrenzen.
Inferenz: Erzeugen von Text
Inferenz, die in jeder Phase durchgeführt wird, bewertet das Modelllernen. Das Modell weist potenziellen Next -Token und Proben aus dieser Verteilung Wahrscheinlichkeiten zu und erstellt Text nicht explizit in den Trainingsdaten, sondern statistisch mit ihm überein. Dieser stochastische Prozess ermöglicht unterschiedliche Ausgänge aus demselben Eingang.
Halluzinationen: falsche Informationen adressieren
Halluzinationen, in denen LLMs falsche Informationen erzeugen, entstehen aus ihrer probabilistischen Natur. Sie "kennen" Fakten nicht, prognostizieren wahrscheinlich wahrscheinlich Wortsequenzen. Minderungsstrategien umfassen:
llms greifen auf Wissen über vage Erinnerungen (Muster aus der Voraussetzung) und den Arbeitsspeicher (Informationen im Kontextfenster) zu. Systemaufforderungen können eine konsistente Modellidentität festlegen.
Schlussfolgerung (Teil 1)
In diesem Teil wurde die grundlegenden Aspekte der LLM -Entwicklung untersucht. Teil 2 wird sich mit Verstärkungslernen befassen und modernste Modelle untersuchen. Ihre Fragen und Vorschläge sind willkommen!
Das obige ist der detaillierte Inhalt vonWie LLMs funktionieren: Vorausbildung zu Nachtraining, neuronalen Netzwerken, Halluzinationen und Inferenz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verlangsamen Sie Videos auf Douyin
So verlangsamen Sie Videos auf Douyin
 So erstellen Sie einen neuen Ordner in Pycharm
So erstellen Sie einen neuen Ordner in Pycharm
 Welche Office-Software gibt es?
Welche Office-Software gibt es?
 So ändern Sie die Größe von Bildern in PS
So ändern Sie die Größe von Bildern in PS
 So lösen Sie das Problem, dass der Zugriff beim Starten von Windows 10 verweigert wird
So lösen Sie das Problem, dass der Zugriff beim Starten von Windows 10 verweigert wird
 Die Leistung von Mikrocomputern hängt hauptsächlich davon ab
Die Leistung von Mikrocomputern hängt hauptsächlich davon ab
 Der Unterschied zwischen a++ und ++a
Der Unterschied zwischen a++ und ++a
 So verwenden Sie die datediff-Funktion
So verwenden Sie die datediff-Funktion








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



