

natürliche Sprachverarbeitung (NLP) ist die automatische oder halbautomatische Verarbeitung der menschlichen Sprache. NLP ist eng mit der Linguistik verwandt und hat Verbindungen zur Forschung in kognitiven Wissenschaft, Psychologie, Physiologie und Mathematik. Insbesondere im Bereich der Informatik betrifft NLP mit Compiler-Techniken, formalen Sprachtheorie, Interaktion zwischen Mensch und Komputer, maschinellem Lernen und Theoreme. Diese Quora -Frage zeigt die unterschiedlichen Vorteile von NLP. Bevor wir sehen, wie man mit dieser Plattform arbeitet, möchte ich Ihnen zunächst sagen, was NLTK ist.
Was ist NLTK? Die Plattform wurde ursprünglich von Steven Bird und Edward Loper in Verbindung mit einem Computer -Linguistikkurs an der Universität von Pennsylvania im Jahr 2001 veröffentlicht. Es gibt ein begleitendes Buch für die Plattform namens Natural Language Processing mit Python. Es wird Spaß machen!
Betrachten Sie den folgenden Text. Ausgabe:
Wie Sie aus der Ausgabe sehen können, werden auch Wörter ausgestrahlt. Sie werden zunächst einige Stop -Wörter mit dem folgenden Skript verwendet:
In diesem Fall werden Sie die folgende Ausgabe ergeben: folgt:
Wie können wir die Stoppwörter aus unserem eigenen Text entfernen? Das folgende Beispiel zeigt, wie wir diese Aufgabe ausführen können:
"Python is a very high-level programming language. Python is interpreted."<br>
Die Ausgabe des obigen Skripts lautet: word_tokenize()
from nltk.tokenize import word_tokenize
text = "Python is a very high-level programming language. Python is interpreted."<br>print(word_tokenize(text))
word_tokenize () <p> hat: </p>
<blockquote> tokenisieren Sie eine Zeichenfolge, um die Interpunktion außer Perioden zu teilen </blockquote> <h3> Suchen </h3> <p> Nehmen wir an, wir haben die folgende Textdatei (laden Sie die Textdatei von Dropbox herunter). Wir möchten nach dem Wort <code>language suchen (suchen). Wir können dies einfach mit der NLTK -Plattform wie folgt tun: "Python is a very high-level programming language. Python is interpreted."<br>
In diesem Fall erhalten Sie die folgende Ausgabe:
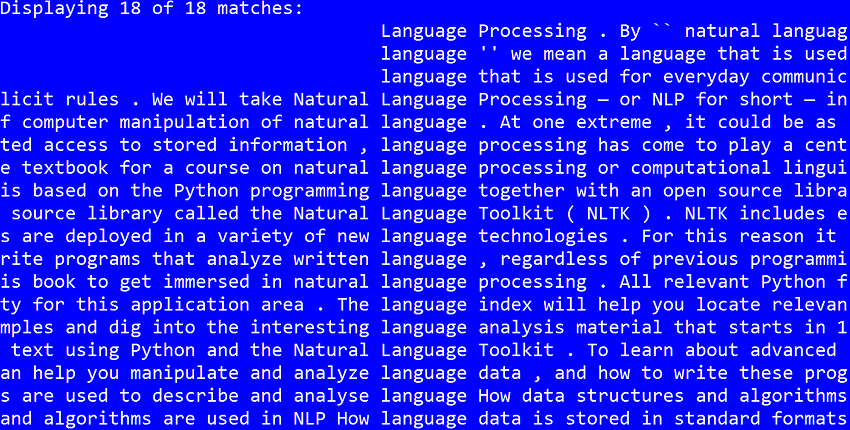
Beachten Sie, dass concordance() zusätzlich zu einem Kontext jedes Vorkommen des Wortes language zurückgibt. Vorher, wie im obigen Skript gezeigt, tokenisieren wir die Lesedatei und konvertieren sie dann in ein nltk.Text Objekt.
Der Gutenberg Corpus
from nltk.tokenize import word_tokenize
text = "Python is a very high-level programming language. Python is interpreted."<br>print(word_tokenize(text))
Wie in Wikipedia erwähnt: chcp 65001
Die Ausgabe des obigen Skripts ist wie folgt:
Wenn wir die Anzahl der Wörter für die Textdatei finden möchten, können wir die folgenden Wörter zurückgeben:
.
['Python', 'is', 'a', 'very', 'high-level', 'programming', 'language', '.', 'Python', 'is', 'interpreted', '.']<br>
Wie wir in diesem Tutorial gesehen haben, bietet uns die NLTK -Plattform ein leistungsstarkes Werkzeug für die Arbeit mit natürlicher Sprachverarbeitung (NLP). Ich habe in diesem Tutorial nur die Oberfläche zerkratzt. Wenn Sie die Verwendung von NLTK für verschiedene NLP -Aufgaben tiefer verwenden möchten, können Sie sich auf das begleitende Buch von NLTK beziehen: natürliche Sprachverarbeitung mit Python. Esther ist ein Softwareentwickler und Autor für Envato -Tuts.

Das obige ist der detaillierte Inhalt vonEinführung des natürlichen Sprach -Toolkits (NLTK). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie Bereichsberechtigungen
So öffnen Sie Bereichsberechtigungen
 Hauptzweck des Dateisystems
Hauptzweck des Dateisystems
 Lösung für die Blockierung von Google Mail
Lösung für die Blockierung von Google Mail
 So lösen Sie das Problem, dass diese Windows-Kopie nicht echt ist
So lösen Sie das Problem, dass diese Windows-Kopie nicht echt ist
 Was ist der Baidu-Index?
Was ist der Baidu-Index?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Löschen Sie redundante Tabellen in der Tabelle
Löschen Sie redundante Tabellen in der Tabelle
 vscode Chinesische Einstellungsmethode
vscode Chinesische Einstellungsmethode








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



