
 Technologie-Peripheriegeräte
KI
Beherrschen multimodaler Lappen mit Vertex AI & Gemini für Inhalt
Technologie-Peripheriegeräte
KI
Beherrschen multimodaler Lappen mit Vertex AI & Gemini für Inhalt
Beherrschen multimodaler Lappen mit Vertex AI & Gemini für Inhalt

Multimodal Abruf Augmented Generation (RAG) hat revolutioniert, wie große Sprachmodelle (LLMs) zugreifen und externe Daten verwenden und über die traditionellen Einschränkungen hinweg nur über herkömmliche Textverletzungen hinausgehen. Die zunehmende Prävalenz multimodaler Daten erfordert die Integration von Text und visuellen Informationen für umfassende Analysen, insbesondere in komplexen Bereichen wie Finanzen und wissenschaftlicher Forschung. Der multimodale Lappen erreicht dies, indem es LLMs ermöglicht, sowohl Text als auch Bilder zu verarbeiten, was zu einem verbesserten Wissensabruf und nuancierteren Argumentation führt. In diesem Artikel wird beschrieben
wichtige Lernziele- das Konzept des multimodalen Lappen und seine Bedeutung für die Verbesserung der Datenabnahmefunktionen erfassen.
- Verstehen Sie, wie Gemini textuelle und visuelle Daten integriert und integriert.
- Lernen Sie, die Funktionen von Scheitelpunkten KI für den Aufbau skalierbarer KI-Modelle zu nutzen, die für Echtzeitanwendungen geeignet sind.
- Erforschen Sie Langchains Rolle bei der nahtlosen Integration von LLMs in externe Datenquellen.
- Entwickeln Sie effektive Frameworks, die sowohl textliche als auch visuelle Informationen für präzise, kontextbewusste Antworten verwenden.
- Wenden Sie diese Techniken auf praktische Anwendungsfälle wie die Erzeugung von Inhalten, personalisierte Empfehlungen und AI -Assistenten an.
Dieser Artikel ist Teil des Data Science -Blogathons.
Inhaltsverzeichnis
- Multimodaler Lappen: Ein umfassender Überblick
- Kerntechnologien verwendet
- Systemarchitektur erklärte
- Konstruktion eines multimodalen Lappensystems mit Scheitelpunkt AI, Gemini und Langchain
-
- Schritt 1: Umgebungskonfiguration
- Schritt 2: Google Cloud -Projektdetails
- Schritt 3: Scheitelpunkt AI SDK -Initialisierung
- Schritt 4: Importieren der notwendigen Bibliotheken
- Schritt 5: Modellspezifikationen
- Schritt 6: Datenaufnahme
- Schritt 7: Erstellen und Bereitstellen eines Vertex -AI -Vektor -Suchindex und des Endpunkts
- Schritt 8: Retriever -Erstellung und Dokumentlade
- Schritt 9: Kettenkonstruktion mit Retriever und Gemini LLM
- Schritt 10: Modelltest
reale Anwendungen - Schlussfolgerung
- häufig gestellte Fragen
Multimodaler Lappen: Ein umfassender Überblick
multimodale Lappensysteme kombinieren visuelle und textuelle Informationen, um reichhaltigere und kontextbezogenere Ausgänge zu liefern. Im Gegensatz zu herkömmlichen textbasierten LLMs sind multimodale Lappensysteme so konzipiert, dass sie visuelle Inhalte wie Diagramme, Diagramme und Bilder aufnehmen und verarbeiten. Diese doppelte Verarbeitungsfunktion ist besonders vorteilhaft für die Analyse komplexer Datensätze, bei denen visuelle Elemente so informativ sind wie der Text, z. B. Finanzberichte, wissenschaftliche Veröffentlichungen oder technische Handbücher. 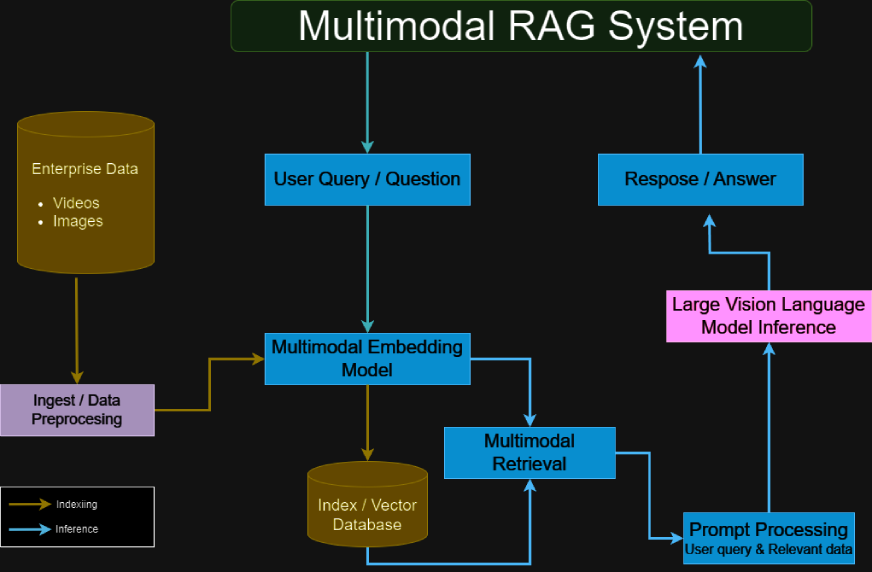
Durch Verarbeitung von Text und Bildern gewinnt das Modell ein tieferes Verständnis der Daten, was zu genaueren und aufschlussreicheren Antworten führt. Diese Integration mindert das Risiko, irreführende oder sachlich falsche Informationen (ein gemeinsames Problem im maschinellen Lernen) zu erzeugen, was zu zuverlässigeren Ausgaben für die Entscheidungsfindung und -analyse führt.
Kerntechnologien verwendet
Dieser Abschnitt fasst die verwendeten Schlüsseltechnologien zusammen:
- Google DeepMinds Gemini: Eine leistungsstarke generative AI -Suite für multimodale Aufgaben, die in der Lage ist, Text und Bilder nahtlos zu verarbeiten und zu generieren.
- Vertex AI: Eine umfassende Plattform für die Entwicklung, Bereitstellung und Skalierung von maschinellen Lernmodellen mit einer robusten Vektorsuchfunktion für effizientes multimodales Datenabruf.
- Langchain: Ein Framework, das die Integration von LLMs in verschiedene Tools und Datenquellen vereinfacht und die Verbindung zwischen Modellen, Einbettungen und externen Ressourcen erleichtert.
- RAGE (ARRAMAL-AUFGENTEGENDE (RAGMENTED ERGANGENT): Ein Framework, das retrievalbasierte und erzeugungsbasierte Modelle kombiniert, um die Reaktionsgenauigkeit zu verbessern, indem relevanten Kontext aus externen Quellen vor dem Generieren von Ausgaben ideal für den Umgang mit multimodalem Inhalt abgerufen werden. ideal.
- OpenAIs Dall · e: (optional) Ein Bildgenerierungsmodell, das Textaufforderungen in visuellen Inhalt umwandelt und multimodale Lappenausgänge mit kontextbezogenen Bildern verbessert.
- Transformatoren für die multimodale Verarbeitung: Die zugrunde liegende Architektur für die Umgang mit gemischten Eingabetypen, die eine effiziente Verarbeitung und Antwortgenerierung mit Text- und visuellen Daten ermöglichen.
Systemarchitektur wurde
erklärt
Ein multimodales Lappensystem umfasst typischerweise:- Gemini für die multimodale Verarbeitung: Griff sowohl Text- als auch Bildeingaben und extrahiert detaillierte Informationen aus jeder Modalität.
- Vertex AI -Vektorsuche: bietet eine Vektordatenbank für ein effizientes Einbettungsmanagement und Datenabruf.
- Langchain Multivectorretriever: fungiert als Vermittler und ruft relevante Daten aus der Vektor -Datenbank basierend auf Benutzeranfragen ab.
- RAG-Framework-Integration: kombiniert abgerufene Daten mit den generativen Funktionen des LLM, um genaue, kontextreiche Antworten zu erstellen.
- Multimodal Encoder-Decoder: Prozesse und verschützt textuellen und visuellen Inhalt, um sicherzustellen, dass beide Datentypen effektiv zur Ausgabe beitragen.
- Transformatoren für die Hybriddatenhandhabung: Verwendet Aufmerksamkeitsmechanismen, um Informationen aus verschiedenen Modalitäten auszurichten und zu integrieren.
- Feinabstimmungsleitungen: (optional) Customisierte Schulungsverfahren, die die Modellleistung basierend auf spezifischen multimodalen Datensätzen für eine verbesserte Genauigkeit und kontextbezogenes Verständnis optimieren.
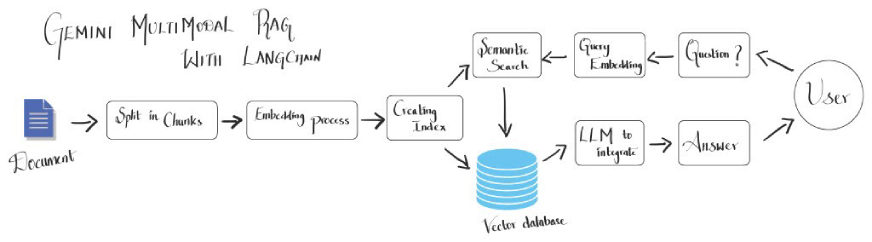
(Die verbleibenden Abschnitte, Schritte 1-10, praktische Anwendungen, Schlussfolgerungen und FAQs würden ein ähnliches Muster der Umformung und Umstrukturierung folgen, um die ursprüngliche Bedeutung aufrechtzuerhalten und gleichzeitig die wörtliche Wiederholung zu vermeiden.
Das obige ist der detaillierte Inhalt vonBeherrschen multimodaler Lappen mit Vertex AI & Gemini für Inhalt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Die Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Februar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Yolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
 Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Der Artikel überprüft Top -KI -Kunstgeneratoren, diskutiert ihre Funktionen, Eignung für kreative Projekte und Wert. Es zeigt MidJourney als den besten Wert für Fachkräfte und empfiehlt Dall-E 2 für hochwertige, anpassbare Kunst.
 Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 ist derzeit verfügbar und weit verbreitet, wodurch im Vergleich zu seinen Vorgängern wie ChatGPT 3.5 signifikante Verbesserungen beim Verständnis des Kontextes und des Generierens kohärenter Antworten zeigt. Zukünftige Entwicklungen können mehr personalisierte Inters umfassen
 Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Der Artikel erörtert KI -Modelle, die Chatgpt wie Lamda, Lama und Grok übertreffen und ihre Vorteile in Bezug auf Genauigkeit, Verständnis und Branchenauswirkungen hervorheben. (159 Charaktere)
 So verwenden Sie Mistral OCR für Ihr nächstes Lappenmodell
Mar 21, 2025 am 11:11 AM
So verwenden Sie Mistral OCR für Ihr nächstes Lappenmodell
Mar 21, 2025 am 11:11 AM
Mistral OCR: revolutionäre retrieval-ausgereifte Generation mit multimodalem Dokumentverständnis RAG-Systeme (Abrufen-Augment-Augmented Generation) haben erheblich fortschrittliche KI
 Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
In dem Artikel werden Top -KI -Schreibassistenten wie Grammarly, Jasper, Copy.ai, Writesonic und RYTR erläutert und sich auf ihre einzigartigen Funktionen für die Erstellung von Inhalten konzentrieren. Es wird argumentiert, dass Jasper in der SEO -Optimierung auszeichnet, während KI -Tools dazu beitragen, den Ton zu erhalten
