

Dieses Tutorial untersucht DeepChecks für Datenvalidierung und maschinelles Lernmodelltest und nutzt Github -Aktionen für automatisierte Tests und Artefakterstellung. Wir werden maschinelles Lernentestsprinzipien, DeepChecks -Funktionalität und einen vollständigen automatisierten Workflow behandeln.

Bild vom Autor
Verständnis für maschinelles Lernen
Effektives maschinelles Lernen erfordert strenge Tests, die über einfache Genauigkeitsmetriken hinausgehen. Wir müssen Fairness, Robustheit und ethische Überlegungen beurteilen, einschließlich der Erkennung von Voreingenommenheit, falsch positiven Aspekten/Negativen, Leistungsmetriken, Durchsatz und Ausrichtung auf die AI -Ethik. Dies beinhaltet Techniken wie Datenvalidierung, Kreuzvalidation, F1-Score-Berechnung, Verwirrungsmatrixanalyse und Drifterkennung (Daten und Vorhersage). Die Datenaufteilung (Zug/Test/Validierung) ist für eine zuverlässige Modellbewertung von entscheidender Bedeutung. Die Automatisierung dieses Vorgangs ist der Schlüssel zum Erstellen von zuverlässigen KI -Systemen.
Für Anfänger bietet die Grundlagen für maschinelles Lernen mit Python Skill Track eine solide Grundlage.
DeepChecks, eine Open-Source-Python-Bibliothek, vereinfacht umfassende Tests für maschinelles Lernen. Es bietet integrierte Überprüfungen für Modellleistung, Datenintegrität und -verteilung und unterstützt die kontinuierliche Validierung für eine zuverlässige Modellbereitstellung.
Erste Schritte mit DeepChecks
DeepChecks mit PIP installieren:
pip install deepchecks --upgrade -q
Datenlast und Vorbereitung (Darlehensdatensatz)
Wir werden den Kreditdatensatz aus DataCamp verwenden.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head() 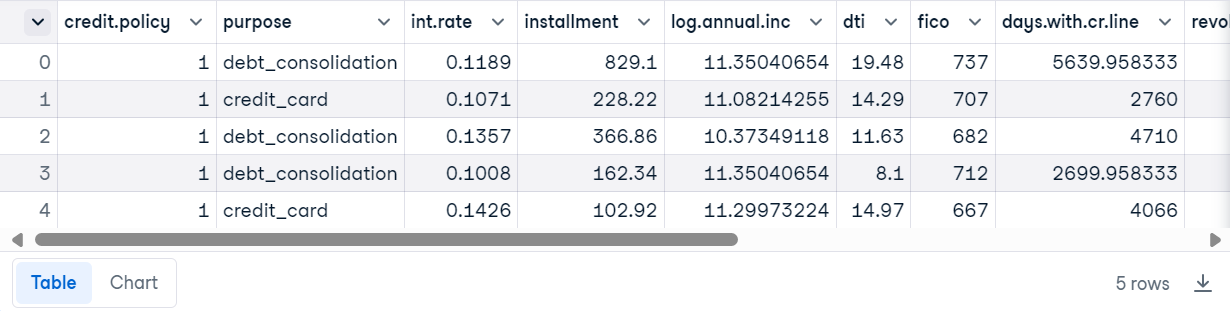
Erstellen Sie einen DeepChecks -Datensatz:
from sklearn.model_selection import train_test_split from deepchecks.tabular import Dataset label_col = 'not.fully.paid' deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
Datenintegritätstest
DeepChecks 'Datenintegritätssuite führt automatisierte Überprüfungen durch.
from deepchecks.tabular.suites import data_integrity integ_suite = data_integrity() suite_result = integ_suite.run(deep_loan_data) suite_result.show_in_iframe() # Use show_in_iframe for DataLab compatibility
Dies erzeugt eine Berichtsabdeckung: Korrelation für Merkmalsmarke, Korrelation mit Merkmalsfunktionen, Einzelwertüberprüfungen, spezielle Zeichenkennung, Nullwertanalyse, Konsistenz des Datentyps, String-Fehlpaarungen, doppelte Erkennung, Stringlängenvalidierung, widersprüchliche Bezeichnungen und Ausflüssigkeitserkennung.
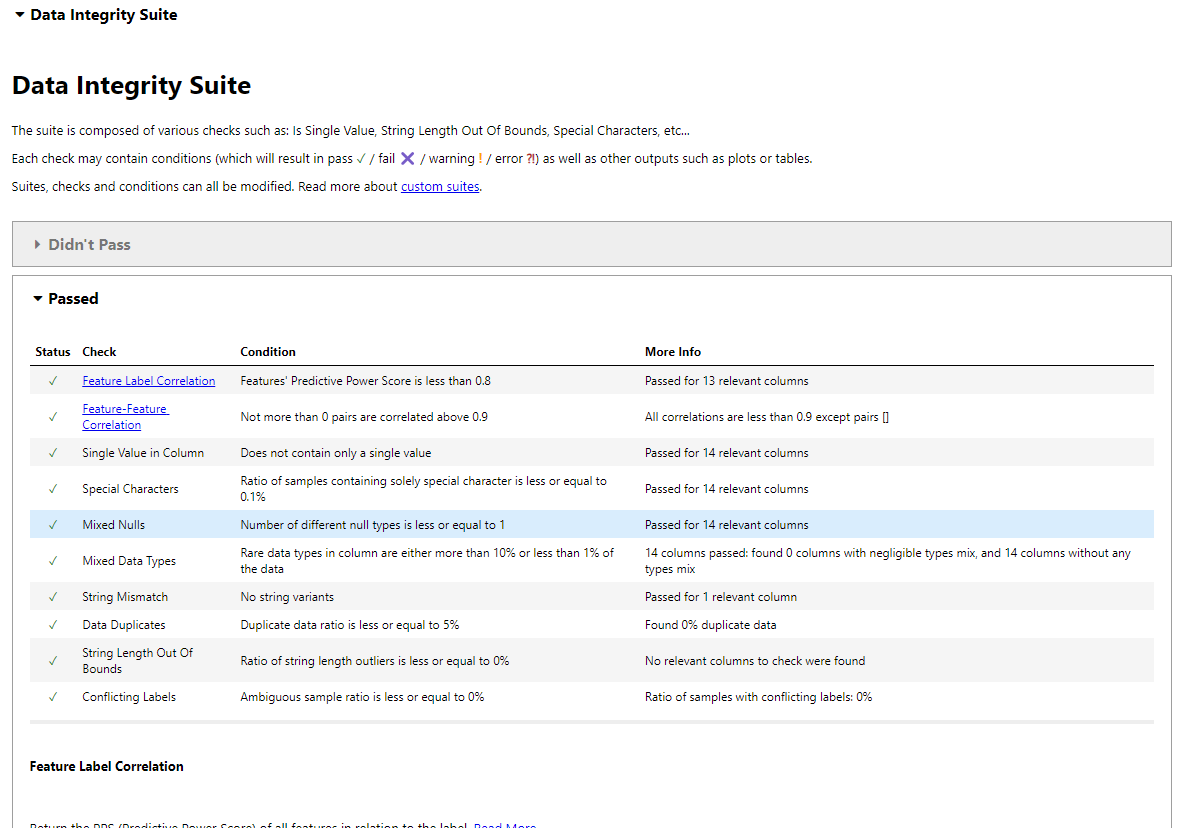
Speichern Sie den Bericht:
suite_result.save_as_html()
individuelle Testausführung
Führen Sie für Effizienz einzelne Tests aus:
from deepchecks.tabular.checks import IsSingleValue, DataDuplicates result = IsSingleValue().run(deep_loan_data) print(result.value) # Unique value counts per column result = DataDuplicates().run(deep_loan_data) print(result.value) # Duplicate sample count
Modellbewertung mit DeepCecks
Wir schulen ein Ensemble -Modell (logistische Regression, zufällige Wald, Gaußsche naive Bayes) und bewerten es mit DeepChecks.
pip install deepchecks --upgrade -q
Der Modellbewertungsbericht umfasst: ROC-Kurven, schwache Segmentleistung, unbenutzte Merkmalserkennung, Zugtestvergleich, Vorhersagedriftanalyse, einfache Modellvergleiche, Modellinferenzzeit, Verwirrungsmatrizen und mehr.

JSON Ausgabe:
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()Individuelle Testbeispiel (Label Drift):
from sklearn.model_selection import train_test_split from deepchecks.tabular import Dataset label_col = 'not.fully.paid' deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
automatisieren mit Github -Aktionen
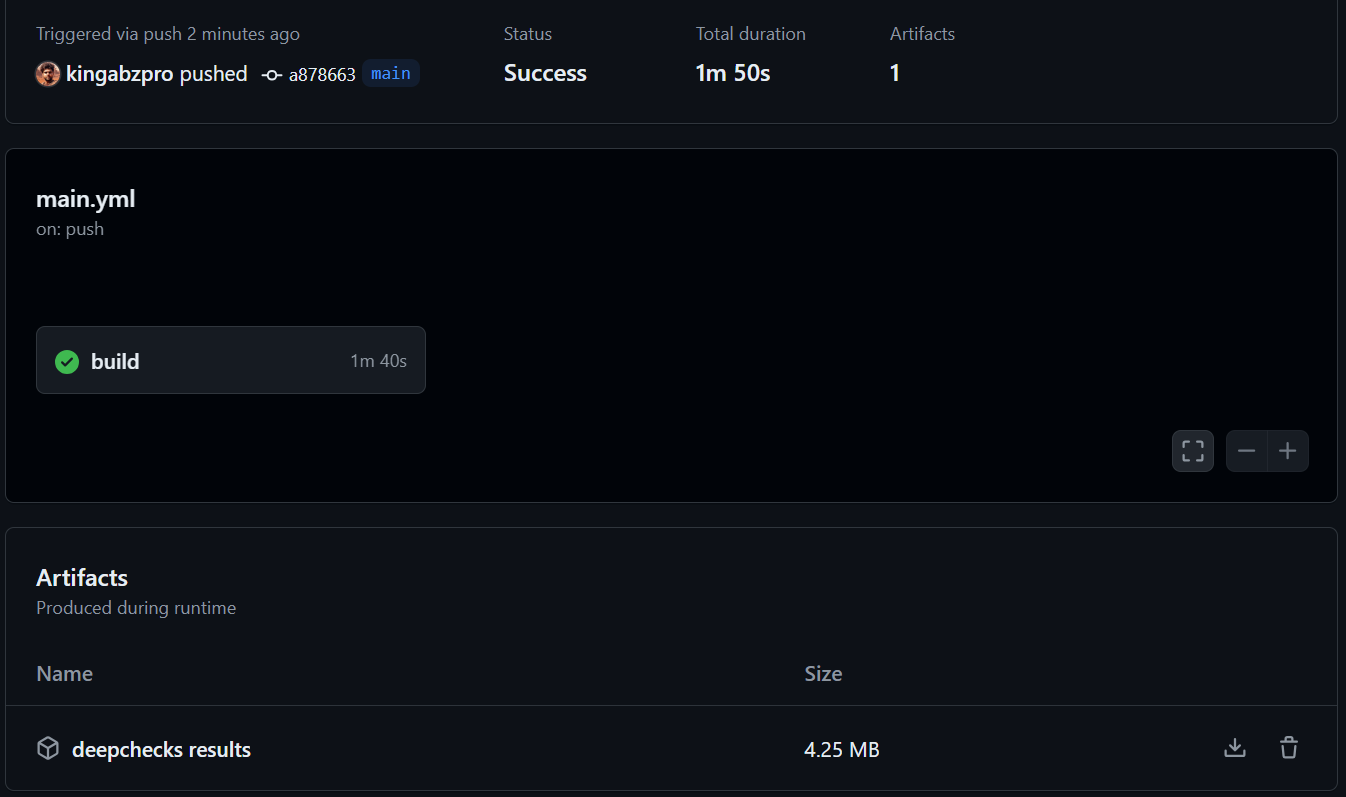
In diesem Abschnitt werden ein Workflow für GitHub -Aktionen zur Automatisierung der Datenvalidierung und des Modelltests angezeigt. Der Prozess beinhaltet das Erstellen eines Repositorys, das Hinzufügen von Daten- und Python -Skripten (data_validation.py, train_validation.py) und das Konfigurieren eines Workflows (main.yml) für GitHub -Aktionen, um diese Skripte auszuführen und die Ergebnisse als Artefakte zu speichern. Detaillierte Schritte und Codeausschnitte finden Sie in der ursprünglichen Eingabe. Ein vollständiges Beispiel finden Sie im Repository kingabzpro/Automating-Machine-Learning-Testing Repository. Der Workflow verwendet die Aktionen actions/checkout, actions/setup-python und actions/upload-artifact.
Schlussfolgerung
Das automatische Automatisieren von maschinellem Lernen mit DeepChecks und GitHub -Aktionen verbessert die Effizienz und Zuverlässigkeit erheblich. Die frühzeitige Erkennung von Problemen verbessert die Modellgenauigkeit und Fairness. Dieses Tutorial bietet einen praktischen Leitfaden zur Implementierung dieses Workflows, mit dem Entwickler robustere und vertrauenswürdigere KI -Systeme aufbauen können. Betrachten Sie den Wissenschaftler für maschinelles Lernen mit Python Career Track für die Weiterentwicklung in diesem Bereich.
Das obige ist der detaillierte Inhalt vonDeepChecks Tutorial: Automatisierung des maschinellen Lerntests. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Verwendung von uniqueResult
Verwendung von uniqueResult
 Die PHPStudy-Datenbank kann die Lösung nicht starten
Die PHPStudy-Datenbank kann die Lösung nicht starten
 So ermitteln Sie den Maximal- und Minimalwert eines Array-Elements in Java
So ermitteln Sie den Maximal- und Minimalwert eines Array-Elements in Java
 Einführung in die Bedeutung von Javascript
Einführung in die Bedeutung von Javascript
 So gehen Sie mit blockierten Dateidownloads in Windows 10 um
So gehen Sie mit blockierten Dateidownloads in Windows 10 um
 Welche Fensterfunktionen gibt es?
Welche Fensterfunktionen gibt es?
 Wie lösche ich den Speicherplatz für WPS-Cloud-Dokumente, wenn er voll ist?
Wie lösche ich den Speicherplatz für WPS-Cloud-Dokumente, wenn er voll ist?
 Der Unterschied zwischen ROM und RAM
Der Unterschied zwischen ROM und RAM








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



