

AI-betriebene Argumentationsmodelle ertragen die Welt im Jahr 2025 im Sturm! Mit dem Start von Deepseek-R1 und O3-Mini haben wir bei AI-Chatbots beispiellose Ebenen logischer Argumentationsfunktionen festgestellt. In diesem Artikel werden wir über ihre APIs auf diese Modelle zugreifen und ihre logischen Argumentationsfähigkeiten bewerten, um herauszufinden, ob O3-Mini Deepseek-R1 ersetzen kann. Wir werden ihre Leistung mit Standard-Benchmarks sowie in realen Anwendungen wie das Lösen logischer Rätsel und sogar das Erstellen eines Tetris-Spiels vergleichen! Also mach dich an und schließe dich der Fahrt an.
Deepseek-R1 und O3-Mini bieten einzigartige Ansätze für strukturiertes Denken und Abzug, wodurch sie für verschiedene Arten komplexer Problemlösungsaufgaben geeignet sind. Bevor wir von ihrer Benchmark -Leistung sprechen, werfen wir zunächst einen kleinen Einblick in die Architektur dieser Modelle.
o3-mini ist das fortschrittlichste Argumentationsmodell von OpenAI. Es verwendet eine dichte Transformatorarchitektur und verarbeitet jedes Token mit allen Modellparametern für eine starke Leistung, aber einen hohen Ressourcenverbrauch. Im Gegensatz dazu verwendet das logischste Modell von Deepseek, R1, ein Mischungsmischungsmischung (MEE), das nur eine Teilmenge von Parametern pro Eingabe für eine größere Effizienz aktiviert. Dies macht Deepseek-R1 skalierbarer und recheninternen optimierter, während die solide Leistung aufrechterhalten wird.
Erfahren Sie mehr: Ist OpenAIs O3-Mini besser als Deepseek-R1? Jetzt müssen wir sehen, wie gut diese Modelle in logischen Argumentationsaufgaben abschneiden. Lassen Sie uns zunächst einen Blick auf ihre Leistung in den LiveBench -Benchmark -Tests werfen.
 Quellen: LiveBench.ai
Quellen: LiveBench.ai
Die Benchmark-Ergebnisse zeigen, dass OpenAIs O3-Mini Deepseek-R1 in fast allen Aspekten übertrifft, mit Ausnahme von Mathematik. Mit einem globalen durchschnittlichen Wert von 73,94 im Vergleich zu Deepseeks 71,38 zeigt der O3-Mini eine etwas stärkere Gesamtleistung. Es zeichnet sich besonders aus der Argumentation aus, erreicht 89,58 gegenüber Deepseeks 83.17 und spiegelt überlegene analytische und Problemlösungsfähigkeiten wider.
Lesen Sie auch: Google Gemini 2.0 Pro gegen Deepseek-R1: Wer kodiert besser?
Deepseek-R1 gegen O3-Mini: API-Preisvergleich
| Model | Context length | Input Price | Cached Input Price | Output Price |
| o3-mini | 200k | .10/M tokens | .55/M tokens | .40/M tokens |
| deepseek-chat | 64k | .27/M tokens | .07/M tokens | .10/M tokens |
| deepseek-reasoner | 64k | .55/M tokens | .14/M tokens | .19/M tokens |
Wie in der Tabelle zu sehen, ist OpenAIs O3-Mini in Bezug auf die API-Kosten fast doppelt so teuer wie Deepseek R1. Es berechnet 1,10 USD pro Million Token für Input und 4,40 USD für die Ausgabe, während Deepseek R1 eine kostengünstigere Rate von 0,55 USD pro Million Token für Input und 2,19 USD für die Ausgabe bietet, was es zu einer budgetfreundlicheren Option für große Anwendungen macht.
.Quellen: Deepseek-R1 | o3-mini
auf Deepseek-R1 und O3-Mini zu
zuBevor wir in den praktischen Leistungsvergleich eintreten, erfahren wir, wie Sie mit APIs auf Deepseek-R1 und O3-Mini zugreifen können.
from openai import OpenAI from IPython.display import display, Markdown import time
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()with open("path_of_api_key") as file:
deepseek_api = file.read().strip()Deepseek-R1 gegen O3-Mini: Logischer Argumentationsvergleich
Kosten für die Generierung der Antwort.
Aufgabe 1: Erstellen eines Tetris -Spiels
Diese Aufgabe erfordert das Modell, um ein voll funktionsfähiges Tetris -Spiel mit Python zu implementieren, das Spiellogik, Stückbewegung, Kollisionserkennung und Rendern effizient verwaltet, ohne sich auf externe Spielmotoren zu verlassen. Eingabeaufforderung:
„Schreiben Sie einen Python -Code für dieses Problem: Generieren Sie einen Python -Code für das Tetris -Spiel“
INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task1_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = messages=[
{
"role": "system",
"content": """You are a professional Programmer with a large experience ."""
},
{
"role": "user",
"content": """write a python code for this problem: generate a python code for Tetris game.
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task1_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: <pre class="brush:php;toolbar:false">INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task2_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = [
{
"role": "system",
"content": """You are an expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """In the following question, assuming the given statements to be true, find which of the conclusions among given conclusions is/are definitely true and then give your answers accordingly.
Statements: H > F ≤ O ≤ L; F ≥ V < D
Conclusions:
I. L ≥ V
II. O > D
The options are:
A. Only I is true
B. Only II is true
C. Both I and II are true
D. Either I or II is true
E. Neither I nor II is true
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task2_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: <pre class="brush:php;toolbar:false">INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task3_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = [
{
"role": "system",
"content": """You are a Expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """
Study the given matrix carefully and select the number from among the given options that can replace the question mark (?) in it.
__________________
| 7 | 13 | 174|
| 9 | 25 | 104|
| 11 | 30 | ? |
|_____|_____|____|
The options are:
A 335
B 129
C 431
D 100
Please mention your approch that you have taken at each step
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task3_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: .005 per 1,000 input tokens
output_cost_per_1k = 0.0044 # Example: .015 per 1,000 output tokens
# Calculate cost
input_cost = (input_tokens / 1000) * input_cost_per_1k
output_cost = (output_tokens / 1000) * output_cost_per_1k
total_cost = input_cost + output_cost
# Print results
print(completion.choices[0].message)
print("----------------=Total Time Taken for task 3:----------------- ", task3_end_time - task3_start_time)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(completion.choices[0].message.content))
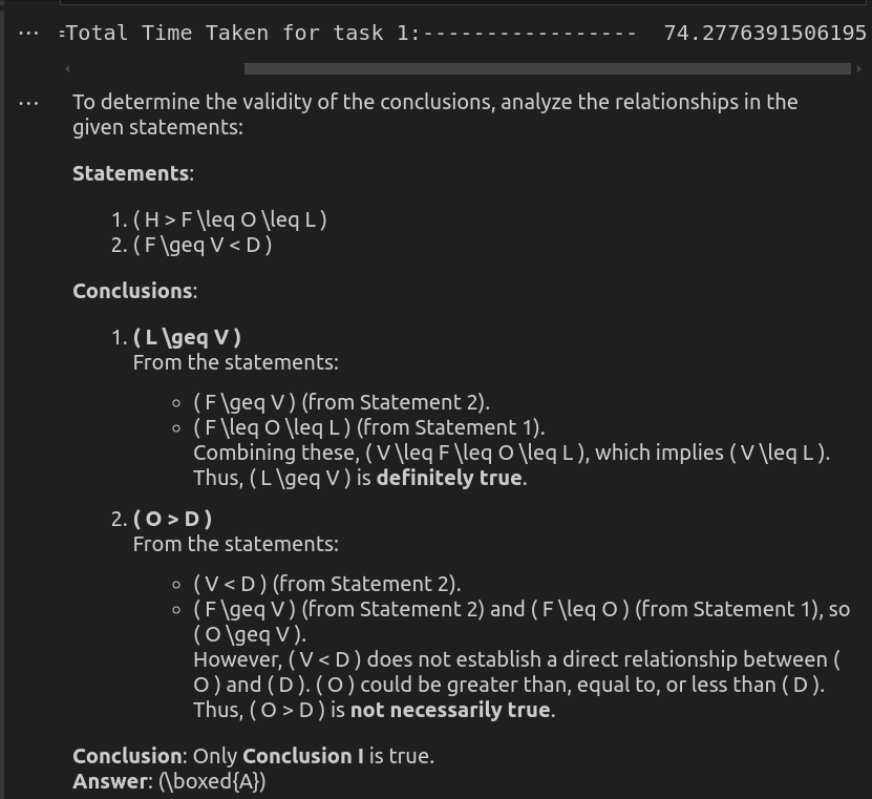
Antwort von Deepseek-R1 
finden Sie die vollständige Antwort von Deepseek-R1 hier.
Ausgangs -Token Kosten:
Eingangs -Token: 28 | Ausgangs -Token: 3323 | Geschätzte Kosten: $ 0,0073
Eingabe in O3-Mini-API
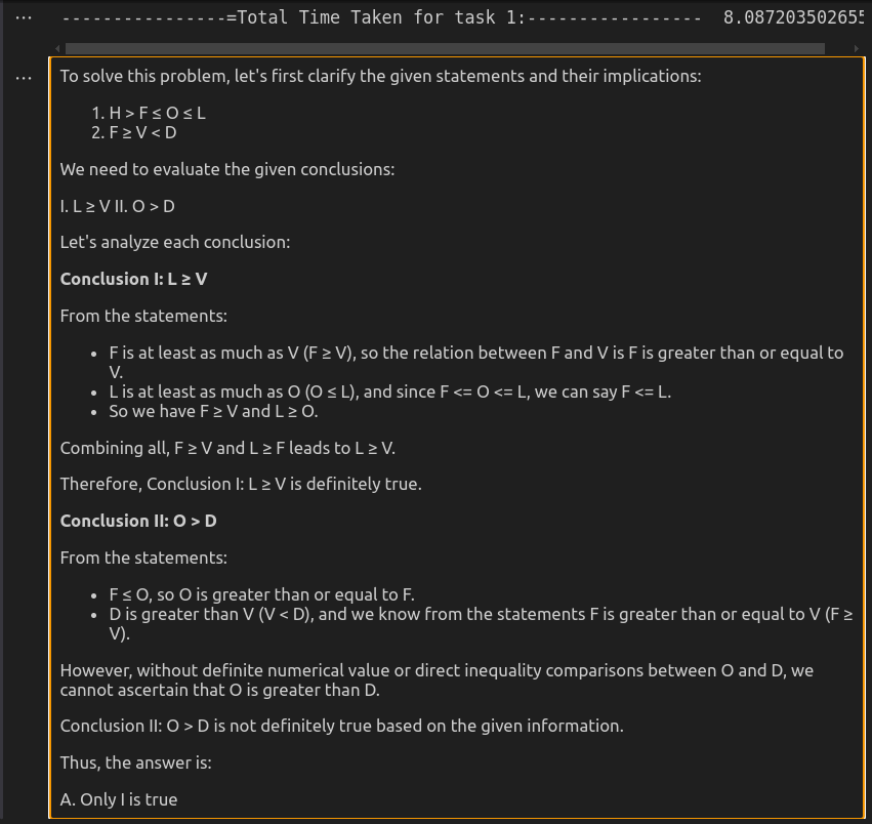
Antwort durch o3-mini 
finden Sie hier die vollständige Antwort von O3-Mini.
Ausgangs -Token Kosten:
Eingangs -Token: 28 | Ausgangs -Token: 3235 | Geschätzte Kosten: $ 0,014265
CodeausgabeVergleichende Analyse
In dieser Aufgabe mussten die Modelle funktionaler Tetris -Code generieren, der das tatsächliche Gameplay ermöglicht. Deepseek-R1 hat erfolgreich eine voll funktionsfähige Implementierung erstellt, wie im Code-Ausgaberoto gezeigt. Während der Code von O3-Mini gut strukturiert erschien, traten er während der Ausführung auf Fehler auf. Infolgedessen übertrifft Deepseek-R1 O3-Mini in diesem Szenario und liefert eine zuverlässigere und spielbarere Lösung.
Punktzahl: Deepseek-R1: 1 | o3-mini: 0
Diese Aufgabe erfordert das Modell, um relationale Ungleichungen effizient zu analysieren, anstatt sich auf grundlegende Sortiermethoden zu verlassen.
Eingabeaufforderung: „ In der folgenden Frage unter der Annahme, dass die angegebenen Aussagen wahr sind, finden Sie, welche der Schlussfolgerungen unter den gegebenen Schlussfolgerungen definitiv wahr sind/sind und geben Sie Ihre Antworten entsprechend an.
.Aussagen:
h & gt; F ≤ o ≤ l; F ≥ v & lt; D
Schlussfolgerungen: I. L ≥ V II. O & gt; D
Die Optionen sind:
a. Nur ich ist wahr
b. Nur II ist wahr
c. Sowohl I als auch II sind wahr
d. Entweder I oder II ist wahr
e. Weder ich noch ii ist wahr. "
Eingabe in Deepseek-R1 API
from openai import OpenAI from IPython.display import display, Markdown import time
Ausgangs -Token Kosten:
Eingangs -Token: 136 | Ausgangs -Token: 352 | Geschätzte Kosten: $ 0,000004
Antwort von Deepseek-R1
Eingabe in O3-Mini-API
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()Ausgangs -Token Kosten:
Eingangs -Token: 135 | Ausgangs -Token: 423 | Geschätzte Kosten: $ 0,002010
Antwort durch o3-mini
Vergleichende Analyse
o3-mini liefert die effizienteste Lösung und sorgt für eine präzise, aber genaue Reaktion in deutlich weniger Zeit. Es behält die Klarheit bei und gewährleistet und sorgt für logische Solidität und macht es ideal für schnelle Argumentationsaufgaben. Deepseek-R1 ist zwar ebenso korrekt, aber viel langsamer und ausführlicher. Die detaillierte Aufschlüsselung der logischen Beziehungen verbessert die Erklärung, kann sich jedoch für einfache Bewertungen übermäßig anfühlen. Obwohl beide Modelle zu dem gleichen Schluss kommen, machen die Geschwindigkeit und den direkten Ansatz von O3-Mini die bessere Wahl für den praktischen Gebrauch.
Punktzahl: Deepseek-R1: 0 | O3-Mini: 1
Diese Aufgabe fordert das Modell heraus, numerische Muster zu erkennen, die arithmetische Operationen, Multiplikation oder eine Kombination mathematischer Regeln beinhalten können. Anstelle einer Brute-Force-Suche muss das Modell einen strukturierten Ansatz verfolgen, um die versteckte Logik effizient abzuleiten.
Eingabeaufforderung: “ studieren Sie die angegebene Matrix sorgfältig und wählen Sie die Nummer unter den angegebenen Optionen aus, die das Fragezeichen (?) Darin ersetzen können.
____________
| 7 | 13 | 174 |
| 9 | 25 | 104 |
| 11 | 30 | ? |
| _____ | ____ | ___ |
Die Optionen sind:
a 335
B 129
c 431
d 100
Bitte erwähnen Sie Ihren Ansatz, den Sie bei jedem Schritt unternommen haben. “
Eingabe in Deepseek-R1 API
from openai import OpenAI from IPython.display import display, Markdown import time
Ausgangs -Token Kosten:
Eingangs -Token: 134 | Ausgangs -Token: 274 | Geschätzte Kosten: $ 0,000003
Antwort von Deepseek-R1

Eingabe in O3-Mini-API
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()Ausgangs -Token Kosten:
Eingangs -Token: 134 | Ausgangs -Token: 736 | Geschätzte Kosten: $ 0,003386
Ausgabe durch O3-mini




Vergleichende Analyse
Hier folgt das in jeder Zeile folgende Muster:
(1. Zahl)^3 - (2. Zahl)^2 = 3rd -Nummer
dieses Muster anwenden:
Die richtige Antwort lautet also 431.
Deepseek-R1 identifiziert und wendet dieses Muster korrekt an und wendet sie zur richtigen Antwort an. Sein strukturierter Ansatz sorgt für die Genauigkeit, obwohl es deutlich länger dauert, um das Ergebnis zu berechnen. O3-mini hingegen legt kein konsistentes Muster fest. Es versucht mehrere Operationen wie Multiplikation, Addition und Exponentiation, kommt jedoch nicht zu einer endgültigen Antwort. Dies führt zu einer unklaren und falschen Antwort. Insgesamt übertrifft Deepseek-R1 O3-Mini in logischem Denken und Genauigkeit, während O3-mini aufgrund seines inkonsistenten und ineffektiven Ansatzes kämpft.
Punktzahl: Deepseek-R1: 1 | o3-mini: 0
| Task No. | Task Type | Model | Performance | Time Taken (seconds) | Cost |
| 1 | Code Generation | DeepSeek-R1 | ✅ Working Code | 606.45 | .0073 |
| o3-mini | ❌ Non-working Code | 99.73 | .014265 | ||
| 2 | Alphabetical Reasoning | DeepSeek-R1 | ✅ Correct | 74.28 | .000004 |
| o3-mini | ✅ Correct | 8.08 | .002010 | ||
| 3 | Mathematical Reasoning | DeepSeek-R1 | ✅ Correct | 450.53 | .000003 |
| o3-mini | ❌ Wrong Answer | 12.37 | .003386 |
Wie wir in diesem Vergleich gesehen haben, zeigen sowohl Deepseek-R1 als auch O3-Mini einzigartige Stärken, die unterschiedliche Bedürfnisse erfüllen. Deepseek-R1 zeichnet sich in genau im mathematischen Denken und komplexen Codegenerierung aus, was es zu einem starken Kandidaten für Anwendungen macht, die logische Tiefe und Korrektheit erfordern. Ein wesentlicher Nachteil sind jedoch die langsameren Reaktionszeiten, teilweise aufgrund laufender Serverwartungsprobleme, die sich auf die Zugänglichkeit ausgewirkt haben. Andererseits bietet O3-Mini deutlich schnellere Reaktionszeiten, aber seine Tendenz, falsche Ergebnisse zu erzielen
Diese Analyse unterstreicht die Kompromisse zwischen Geschwindigkeit und Genauigkeit in Sprachmodellen. Während O3-Mini für schnelle Anwendungen mit geringem Risiko nützlich sein kann, ist Deepseek-R1 als überlegene Wahl für argumentationsintensive Aufgaben, vorausgesetzt, die Latenzprobleme werden angegangen. Wenn sich die KI-Modelle weiterentwickeln, ist es der Schlüssel zur Optimierung von AI-gesteuerten Workflows in verschiedenen Bereichen, ein Gleichgewicht zwischen Leistungseffizienz und Richtigkeit zu erreichen.
Lesen Sie auch: Kann Openais O3-Mini-Beat-Claude-Sonnet 3.5 in Codierung geöffnet?
häufig gestellte FragenQ2. Ist Deepseek-R1 besser als O3-Mini für die Codierungsaufgaben? a. Deepseek-R1 ist die bessere Wahl für codierende und argumentationsintensive Aufgaben aufgrund seiner überlegenen Genauigkeit und Fähigkeit, komplexe Logik zu bewältigen. O3-mini liefert zwar schnellere Antworten, kann jedoch Fehler erzeugen, was es für Programmieraufgaben mit hohen Einsätzen weniger zuverlässig macht.
Q3. Ist O3-mini für reale Anwendungen geeignet? a. O3-mini eignet sich am besten für risikoarme, geschwindigkeitsabhängige Anwendungen wie Chatbots, Casual Text-Generation und interaktive KI-Erlebnisse. Bei Aufgaben, die eine hohe Genauigkeit erfordern, ist Deepseek-R1 jedoch die bevorzugte Option.
Q4. Welches Modell ist besser zum Denken und zur Problemlösung-Deepseek-R1 oder O3-Mini? a. Deepseek-R1 verfügt über überlegene logische Argumentations- und Problemlösungsfunktionen und macht es zu einer starken Wahl für mathematische Berechnungen, Programmierhilfe und wissenschaftliche Abfragen. O3-mini bietet schnelle, aber manchmal inkonsistente Reaktionen in komplexen Problemlösungsszenarien.
Das obige ist der detaillierte Inhalt vonKann O3-Mini Deepseek-R1 für logisches Denken ersetzen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



