

Batch -Normalisierung: Theorie und Tensorflow -Implementierung

Tiefes neuronales Netzwerktraining steht häufig vor Hürden wie Verschwinden/explodierender Gradienten und interner kovariater Verschiebung, Verlangsamung von Training und Behinderung des Lernens. Normalisierungstechniken bieten eine Lösung, wobei die Batch -Normalisierung (BN) besonders prominent ist. BN beschleunigt die Konvergenz, verbessert die Stabilität und verbessert die Verallgemeinerung in vielen Architekturen für tiefe Lernen. Dieses Tutorial erklärt die Mechanik von BN, seine mathematischen Grundlagen und Tensorflow/Keras -Implementierung.
Normalisierung im maschinellen Lernen standardisiert Eingabedaten mit Methoden wie Min-Max-Skalierung, Z-Score-Normalisierung und logarithmischen Transformationen zu den Umschlüssen. Dies mindert Ausreißereffekte, verbessert die Konvergenz und sorgt für einen fairen Merkmalsvergleich. Normalisierte Daten sorgen für einen gleichen Merkmalsbeitrag zum Lernprozess, wodurch verhindern, dass größere Merkmale dominieren und zu einer suboptimalen Modellleistung führen. Es ermöglicht das Modell, sinnvolle Muster effektiver zu identifizieren.
Herausforderungen bei Deep Learning Training gehören:
- interne kovariate Verschiebung: Verteilungsänderungen für Aktivierungen während des Trainings, die Behinderung der Anpassung und des Lernens. . .
- Verschwinden/explodierende Gradienten: Gradienten werden während der Rückpropagation zu klein oder zu groß und behindern effektive Gewichtsaktualisierungen.
- Initialisierungsempfindlichkeit: Anfangsgewichte beeinflussen das Training stark; Eine schlechte Initialisierung kann zu langsamer oder fehlgeschlagener Konvergenz führen.
Die Batch-Normalisierung befasst sich durch die Normalisierung von Aktivierungen in jedem Mini-Batch, Stabilisierung der Schulung und Verbesserung der Modellleistung.
Stapel-Normalisierung normalisiert die Aktivierungen einer Schicht innerhalb eines Mini-Batch während des Trainings. Es berechnet den Mittelwert und die Varianz von Aktivierungen für jedes Merkmal und normalisiert dann mit diesen Statistiken. Lernbare Parameter (γ und β) Skala und verschieben die normalisierten Aktivierungen, sodass das Modell die optimale Aktivierungsverteilung lernen kann.

Quelle: Yintai Ma und Diego Klabjan.
bn wird typischerweise nach der linearen Transformation einer Schicht (z. B. Matrixmultiplikation in vollständig verbundenen Schichten oder Faltung in Faltungsschichten) und vor der nichtlinearen Aktivierungsfunktion (z. B. Relu) angewendet. Schlüsselkomponenten sind Mini-Batch-Statistiken (Mittelwert und Varianz), Normalisierung und Skalierung/Verschiebung mit lernbaren Parametern.
bn adressiert die interne kovariate Verschiebung durch Normalisierung von Aktivierungen in jedem Mini-Batch, wodurch Eingaben zu nachfolgenden Schichten stabiler werden. Dies ermöglicht eine schnellere Konvergenz mit höheren Lernraten und reduziert die Initialisierungsempfindlichkeit. Es wird auch reguliert, wodurch Überanpassung durch Verringerung der Abhängigkeit von spezifischen Aktivierungsmustern verhindert wird.
Mathematik der Stapelnormalisierung:
bn funktioniert während des Trainings und der Inferenz unterschiedlich.
Training:
- Normalisierung: Mittelwert (μ b ) und Varianz (σ b 2 ) werden für jedes Merkmal in einem Mini-Batch berechnet:
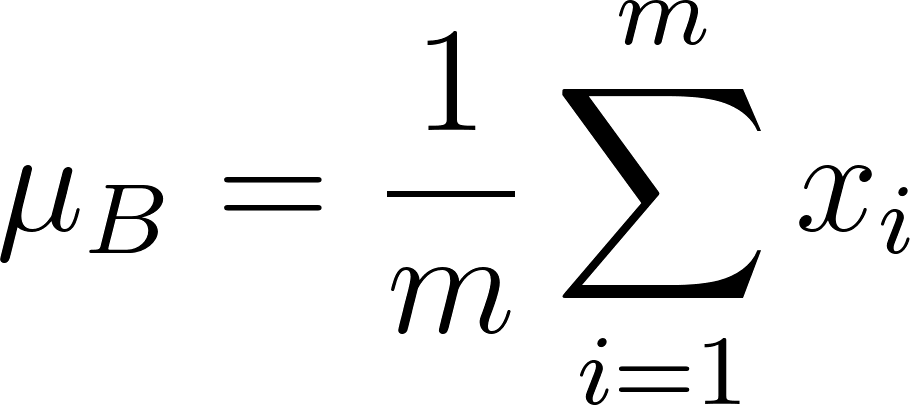

Aktivierungen (x i ) werden normalisiert:
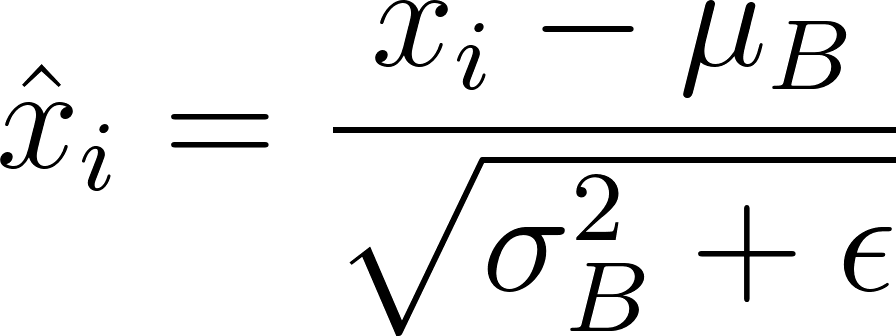
(ε ist eine kleine Konstante für die numerische Stabilität).
- Skalierung und Verschiebung: Lernbare Parameter γ und β -Skala und Verschiebung:

Inferenz: Stapelstatistiken werden durch laufende Statistiken (laufender Mittel und Varianz) ersetzt, berechnet während des Trainings mit einem gleitenden Durchschnitt (Impulsfaktor α):


Diese laufenden Statistiken und die gelernten γ und β werden zur Normalisierung während der Inferenz verwendet.
TensorFlow -Implementierung:
import tensorflow as tf
from tensorflow import keras
# Load and preprocess MNIST data (as described in the original text)
# ...
# Define the model architecture
model = keras.Sequential([
keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(64, (3, 3), activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dense(10, activation='softmax')
])
# Compile and train the model (as described in the original text)
# ...Implementierungsüberlegungen:
- Platzierung: Nach linearen Transformationen und vor Aktivierungsfunktionen.
- Stapelgröße: Größere Chargengrößen bieten genauere Stapelstatistiken.
- Regularisierung: bn führt einen Regularisierungseffekt ein.
Einschränkungen und Herausforderungen:
- Nicht-konvolutionelle Architekturen: Die Wirksamkeit von BN wird in RNNs und Transformatoren verringert.
- Kleine Stapelgrößen: Weniger zuverlässige Stapelstatistik.
- Rechenaufwand: Erhöhte Speicher- und Trainingszeit.
mildernde Einschränkungen: Adaptive Stapel -Normalisierung, virtuelle Stapel -Normalisierung und Hybridnormalisierungstechniken können einige Einschränkungen angehen.
Varianten und Erweiterungen: Schichtnormalisierung, Gruppennormalisierung, Instanznormalisierung, Stapel -Renormierung und Gewichtnormalisierung bieten Abhängigkeiten von den spezifischen Bedürfnissen.
Alternativen oder Verbesserungen.Schlussfolgerung: Die Stapelnormalisierung ist eine leistungsstarke Technik, die das tiefe Training für neuronale Netzwerke verbessert. Denken Sie an seine Vorteile, Implementierungsdetails und Einschränkungen und berücksichtigen Sie seine Varianten für eine optimale Leistung in Ihren Projekten.
Das obige ist der detaillierte Inhalt vonBatch -Normalisierung: Theorie und Tensorflow -Implementierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Der Artikel überprüft Top -KI -Kunstgeneratoren, diskutiert ihre Funktionen, Eignung für kreative Projekte und Wert. Es zeigt MidJourney als den besten Wert für Fachkräfte und empfiehlt Dall-E 2 für hochwertige, anpassbare Kunst.
 Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Metas Lama 3.2: Ein Sprung nach vorne in der multimodalen und mobilen KI Meta hat kürzlich Lama 3.2 vorgestellt, ein bedeutender Fortschritt in der KI mit leistungsstarken Sichtfunktionen und leichten Textmodellen, die für mobile Geräte optimiert sind. Aufbau auf dem Erfolg o
 Beste AI -Chatbots verglichen (Chatgpt, Gemini, Claude & amp; mehr)
Apr 02, 2025 pm 06:09 PM
Beste AI -Chatbots verglichen (Chatgpt, Gemini, Claude & amp; mehr)
Apr 02, 2025 pm 06:09 PM
Der Artikel vergleicht Top -KI -Chatbots wie Chatgpt, Gemini und Claude und konzentriert sich auf ihre einzigartigen Funktionen, Anpassungsoptionen und Leistung in der Verarbeitung und Zuverlässigkeit natürlicher Sprache.
 Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
In dem Artikel werden Top -KI -Schreibassistenten wie Grammarly, Jasper, Copy.ai, Writesonic und RYTR erläutert und sich auf ihre einzigartigen Funktionen für die Erstellung von Inhalten konzentrieren. Es wird argumentiert, dass Jasper in der SEO -Optimierung auszeichnet, während KI -Tools dazu beitragen, den Ton zu erhalten
 10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
Hey da, codieren Ninja! Welche Codierungsaufgaben haben Sie für den Tag geplant? Bevor Sie weiter in diesen Blog eintauchen, möchte ich, dass Sie über all Ihre Coding-Leiden nachdenken-die Auflistung auflisten diese auf. Erledigt? - Lassen Sie ’
 AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
Die KI -Landschaft dieser Woche: Ein Wirbelsturm von Fortschritten, ethischen Überlegungen und regulatorischen Debatten. Hauptakteure wie OpenAI, Google, Meta und Microsoft haben einen Strom von Updates veröffentlicht, von bahnbrechenden neuen Modellen bis hin zu entscheidenden Verschiebungen in LE
 Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Das jüngste Memo von Shopify -CEO Tobi Lütke erklärt kühn für jeden Mitarbeiter eine grundlegende Erwartung und kennzeichnet eine bedeutende kulturelle Veränderung innerhalb des Unternehmens. Dies ist kein flüchtiger Trend; Es ist ein neues operatives Paradigma, das in P integriert ist
 Auswahl des besten KI -Sprachgenerators: Top -Optionen überprüft
Apr 02, 2025 pm 06:12 PM
Auswahl des besten KI -Sprachgenerators: Top -Optionen überprüft
Apr 02, 2025 pm 06:12 PM
Der Artikel überprüft Top -KI -Sprachgeneratoren wie Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson und Descript, wobei sie sich auf ihre Funktionen, die Sprachqualität und die Eignung für verschiedene Anforderungen konzentrieren.
