

yolov11: Ein tiefes Eintauchen in die Architektur und Implementierung eines modernen Objekterkennungsmodells
yolo (Sie sehen nur einmal aus) Modelle sind für ihre Effizienz und Genauigkeit bei Computer -Vision -Aufgaben bekannt, einschließlich Objekterkennung, Segmentierung, Posenschätzung und mehr. Dieser Artikel konzentriert sich auf die Architektur und Implementierung der neuesten Iteration Yolov11 mit Pytorch. Während Ultralytics, die Schöpfer, die praktische Anwendung vor formalen Forschungsarbeiten priorisieren, werden wir das Design analysieren und ein funktionales Modell erstellen.
Verständnis der Architektur von YOLOV11
yolov11 verwendet wie seine Vorgänger eine dreiteilige Architektur: Rückgrat, Hals und Kopf.
Rückgrat: extrahiert Merkmale mit effizienten Engpassblöcken (C3K2, eine Verfeinerung des C2F von YOLOV8). Dieses Rückgrat nutzt Darknet und DarkFPN, erzeugt drei Feature -Karten (P3, P4, P5), die verschiedene Detailebenen darstellen.
Hals: verarbeitet die Ausgabe des Rückgraters und vereint Merkmale über Skalen mit upsampling und Verkettung. Eine entscheidende Komponente ist der C2PSA-Block, der partielle räumliche Aufmerksamkeitsmodule (PSA) enthält, um die Fokussierung auf relevante räumliche Informationen in Merkmalen auf niedriger Ebene zu verbessern.
Kopf: verarbeitet aufgabenspezifische Vorhersagen. Für die Objekterkennung enthält es:
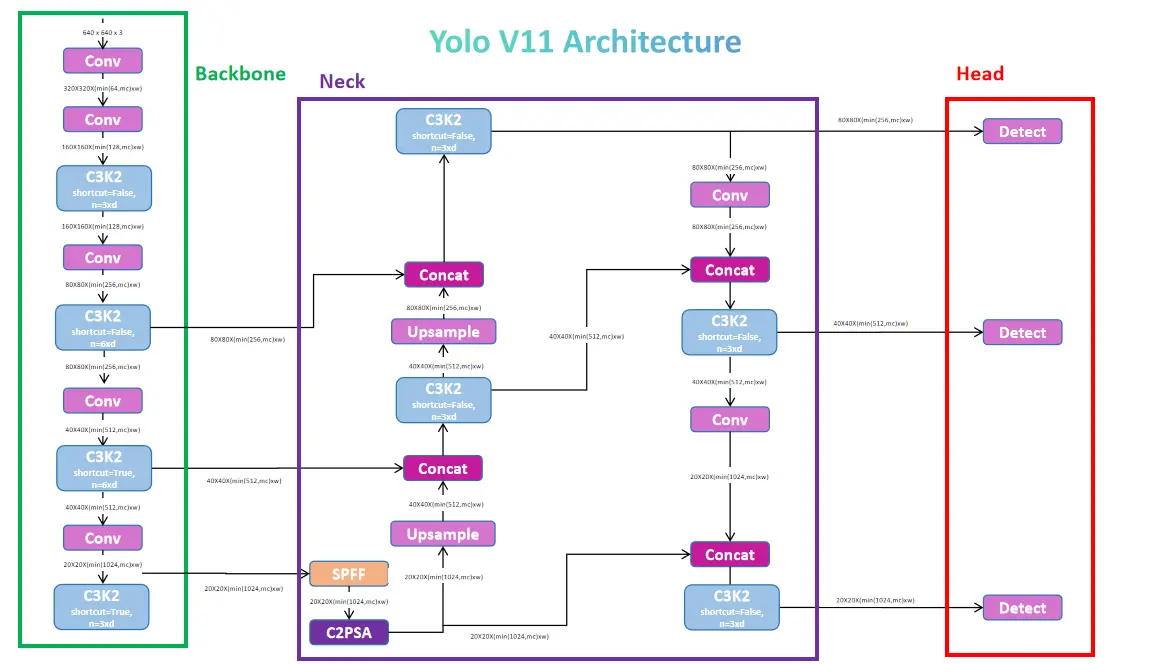
Kernbausteine: Faltungs- und Engpassschichten
Das Modell stützt sich stark auf:


Die folgenden Code -Snippets veranschaulichen Schlüsselkomponenten:
(simifified for the Tumity; siehe Originalartikel für vollständigen Code.)
# Simplified Conv Block
class Conv(nn.Module):
def __init__(self, in_ch, out_ch, activation, ...):
# ... (Initialization code) ...
def forward(self, x):
return activation(self.norm(self.conv(x)))
# Simplified Bottleneck Block (Residual)
class Residual(nn.Module):
def __init__(self, ch, e=0.5):
# ... (Initialization code) ...
def forward(self, x):
return x + self.conv2(self.conv1(x))
# Simplified SPPF
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
# ... (Initialization code) ...
def forward(self, x):
# ... (MaxPooling and concatenation) ...
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
# ... (Other key blocks: C3K, C3K2, PSA, Attention, PSABlock, DFL) ...Modellkonstruktion und Test
Das komplette Yolov11 -Modell wird durch Kombinieren des Rückgrats, des Hals und des Kopfes konstruiert. Verschiedene Modellgrößen (Nano, klein, mittel, groß, Xlarge) werden durch Anpassen von Parametern wie Tiefe und Breite erreicht. Der bereitgestellte Code enthält eine YOLOv11 Klasse, um dies zu erleichtern.
Modelltests mit einem zufälligen Eingangspfehlungszensor demonstriert die Ausgangsstruktur (Merkmalskarten im Trainingsmodus, verkettete Vorhersagen im Bewertungsmodus). Eine weitere Verarbeitung (Nicht-Maximum-Unterdrückung) ist erforderlich, um endgültige Objekterkennung zu erhalten.
Schlussfolgerung
yolov11 stellt einen signifikanten Fortschritt bei der Objekterkennung dar und bietet eine leistungsstarke und effiziente Architektur. Sein Design priorisiert praktische Anwendungen und macht es zu einem wertvollen Instrument für reale KI-Projekte. Die detaillierten Architektur- und Code -Snippets bieten eine solide Grundlage für Verständnis und Weiterentwicklung. Denken Sie daran, den ursprünglichen Artikel für den vollständigen, runnablen Code zu konsultieren.
Das obige ist der detaillierte Inhalt vonLeitfaden zum YOLOV11 -Modellgebäude von Grund auf neu von Grund auf mit Pytorch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So flashen Sie ein Xiaomi-Telefon
So flashen Sie ein Xiaomi-Telefon
 So zentrieren Sie ein Div in CSS
So zentrieren Sie ein Div in CSS
 So öffnen Sie eine RAR-Datei
So öffnen Sie eine RAR-Datei
 Methoden zum Lesen und Schreiben von Java-DBF-Dateien
Methoden zum Lesen und Schreiben von Java-DBF-Dateien
 So lösen Sie das Problem, dass die Datei msxml6.dll fehlt
So lösen Sie das Problem, dass die Datei msxml6.dll fehlt
 Häufig verwendete Permutations- und Kombinationsformeln
Häufig verwendete Permutations- und Kombinationsformeln
 Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten
Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten
 dynamisches Fotoalbum
dynamisches Fotoalbum








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



