

qwen2.5-max: ein kostengünstiges, menschliches Argumentieren großer Sprachmodell
Die KI-Landschaft summt mit leistungsstarken, kostengünstigen Modellen wie Deepseek, Mistral Small 3 und Qwen2.5 Max. Insbesondere qwen2.5-max macht Wellen als motiviertes Modell der Experten (MOE), das Deepseek V3 in einigen Benchmarks sogar übertrifft. Die fortschrittliche Architektur und der massive Trainingsdatensatz (bis zu 18 Billionen Token) setzen neue Standards für die Leistung fest. In diesem Artikel werden die Architektur von Qwen2.5-max, seine Wettbewerbsvorteile und sein Potenzial für die Konkurrenz von Deepseek V3 untersucht. Wir werden Sie auch durch das Ausführen von QWEN2.5 -Modellen lokal ausführen.
Schlüssel QWEN2.5 Modellfunktionen:
Inhaltsverzeichnis:
qwen2.5 lokal mit Ollama ausführen:
Installieren Sie zunächst Ollama: Ollama Download Link
Linux/Ubuntu -Benutzer: curl -fsSL https://ollama.com/install.sh | sh
verfügbar QWEN2.5 Ollama -Modelle:
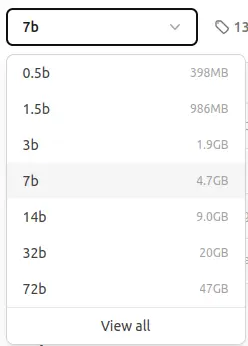
Wir verwenden das 7B -Parametermodell (ca. 4,7 GB). Für Benutzer mit begrenzten Ressourcen stehen kleinere Modelle zur Verfügung.
qwen2.5: 7b Inferenz:
ollama pull qwen2.5:7b
Der Befehl pull lädt das Modell herunter. Sie werden eine ähnliche Ausgabe sehen:
<code>pulling manifest pulling 2bada8a74506... 100% ▕████████████████▏ 4.7 GB ... (rest of the output) ... success</code>
Dann führen Sie das Modell aus:
ollama run qwen2.5:7b
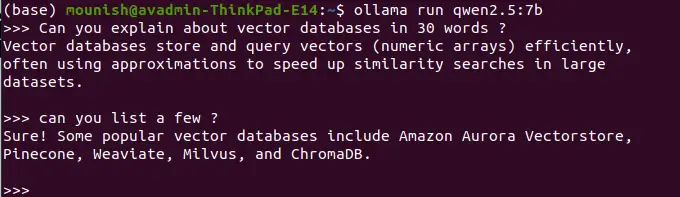
Beispielabfragen:
Eingabeaufforderung: Vektordatenbanken in 30 Wörtern definieren.
<code>Vector databases efficiently store and query numerical arrays (vectors), often using approximations for fast similarity searches in large datasets.</code>
Eingabeaufforderung: Auflisten Sie einige Beispiele auf.
<code>Popular vector databases include Pinecone, Weaviate, Milvus, ChromaDB, and Amazon Aurora Vectorstore.</code>
(drücken Sie Strg D, um zu beenden)
Hinweis: Lokal geführte Modelle haben keine Echtzeit-Zugriffs- und Web-Suchfunktionen. Zum Beispiel:
Eingabeaufforderung: Was ist das heutige Datum?
<code>Today's date is unavailable. My knowledge is not updated in real-time.</code>

QWEN2.5-CODER: 3B Inferenz:
Folgen Sie dem gleichen Prozess und ersetzen Sie qwen2.5-coder:3b für qwen2.5:7b in den Befehlen pull und run.
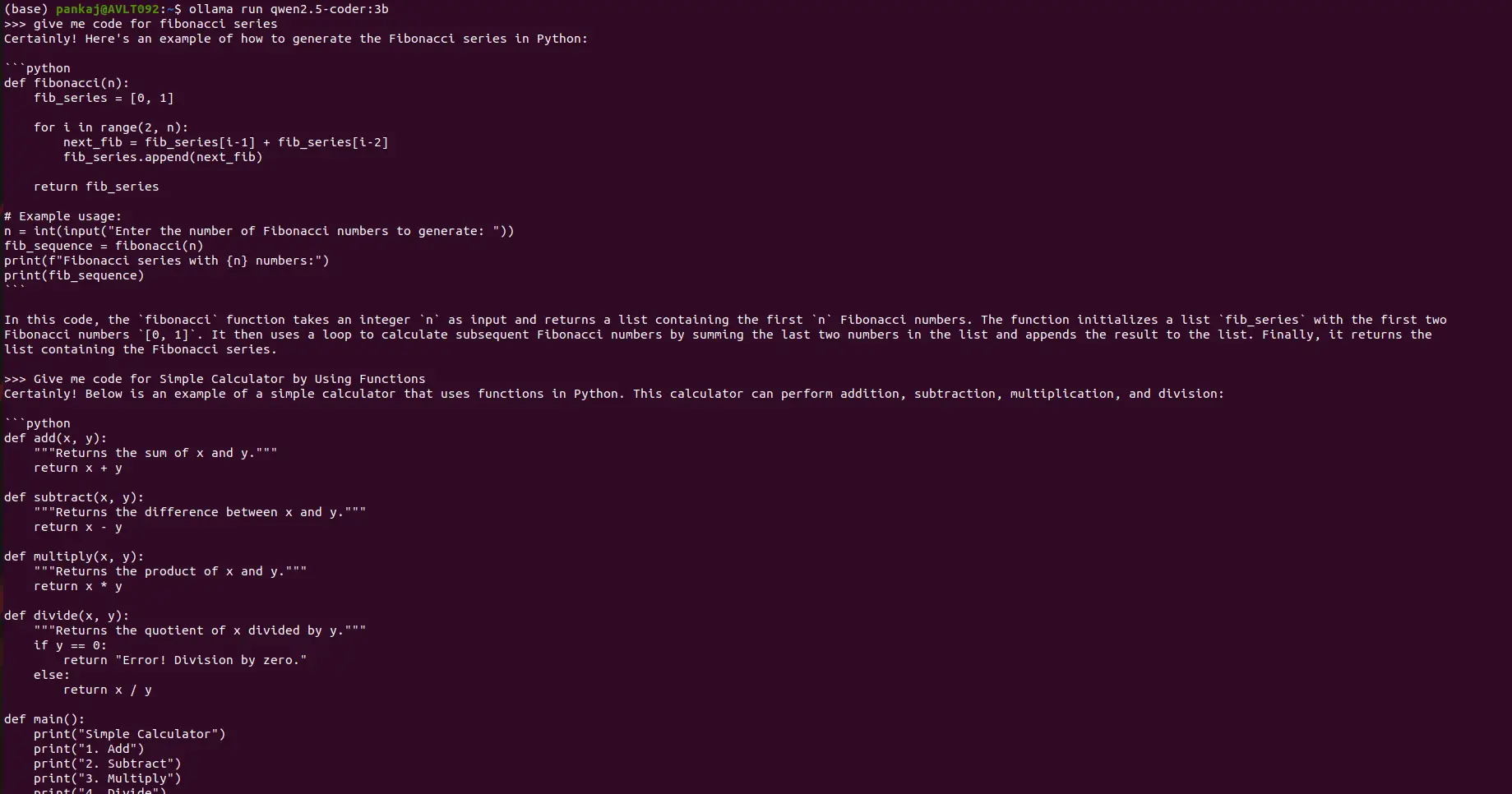
Beispielcodierungsaufforderungen:
Eingabeaufforderung: Geben Sie Python -Code für die Fibonacci -Sequenz an.
(Ausgabe: Python -Code für die Fibonacci -Sequenz wird hier angezeigt)
Eingabeaufforderung: Erstellen Sie einen einfachen Taschenrechner mit Python -Funktionen.
(Ausgabe: Python -Code für einen einfachen Taschenrechner wird hier angezeigt)
Schlussfolgerung:
Dieser Leitfaden zeigt, wie QWEN2.5-Modelle lokal mit OLLAMA ausführen und die Stärken von Qwen2.5-Max hervorheben: 128K-Kontextlänge, mehrsprachige Unterstützung und verbesserte Funktionen. Während die lokale Ausführung die Sicherheit verbessert, opfert sie den Zugriff auf den Echtzeitinformationen. QWEN2.5 bietet ein überzeugendes Gleichgewicht zwischen Effizienz, Sicherheit und Leistung und macht es zu einer starken Alternative zu Deepseek V3 für verschiedene KI -Anwendungen. Weitere Informationen zum Zugriff auf QWEN2.5-max über Google Colab finden Sie in einer separaten Ressource.
Das obige ist der detaillierte Inhalt vonWie fahre ich QWEN2.5 -Modelle lokal in 3 Minuten aus?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Verwendung von uniqueResult
Verwendung von uniqueResult
 Die PHPStudy-Datenbank kann die Lösung nicht starten
Die PHPStudy-Datenbank kann die Lösung nicht starten
 So ermitteln Sie den Maximal- und Minimalwert eines Array-Elements in Java
So ermitteln Sie den Maximal- und Minimalwert eines Array-Elements in Java
 Einführung in die Bedeutung von Javascript
Einführung in die Bedeutung von Javascript
 So gehen Sie mit blockierten Dateidownloads in Windows 10 um
So gehen Sie mit blockierten Dateidownloads in Windows 10 um
 Welche Fensterfunktionen gibt es?
Welche Fensterfunktionen gibt es?
 Wie lösche ich den Speicherplatz für WPS-Cloud-Dokumente, wenn er voll ist?
Wie lösche ich den Speicherplatz für WPS-Cloud-Dokumente, wenn er voll ist?
 Der Unterschied zwischen ROM und RAM
Der Unterschied zwischen ROM und RAM








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



