

Snowpark: In-Database-maschinelles Lernen mit Schneeflocke
traditionelles maschinelles Lernen beinhaltet häufig das Verschieben von massiven Datensätzen von Datenbanken in Modelltrainingsumgebungen. Dies ist mit den großen Datensätzen von heute zunehmend ineffizienter. Der Snowflake Snowpark spricht dies an, indem es die In-Database-Verarbeitung aktiviert. Snowpark bietet Bibliotheken und Laufzeiten, um Code (Python, Java, Scala) direkt in der Snowflake -Cloud auszuführen, die Datenbewegung zu minimieren und die Sicherheit zu verbessern.
Warum Snowpark wählen?
Snowpark bietet mehrere wichtige Vorteile:
Erste Schritte: Eine Schritt-für-Schritt-Anleitung
Dieses Tutorial zeigt, dass ein hyperparameterstimmiges Modell mit Snowpark erstellt wird.
Virtuelle Umgebung Setup: Erstellen Sie eine Konda -Umgebung und installieren Sie die erforderlichen Bibliotheken (snowflake-snowpark-python, pandas, pyarrow, numpy, matplotlib, seaborn, ipykernel).
Datenaufnahme: im Importieren von Stichprobendaten (z. B. dem Datensatz von Seeborn Diamonds) in eine Schneeflockungstabelle. (Hinweis: In realen Szenarien arbeiten Sie normalerweise mit vorhandenen Schneeflocken-Datenbanken.)
Snowpark -Sitzungs -Session -Erstellung: Stellen Sie eine Verbindung zur Schneeflocke mit Ihren Anmeldeinformationen (Kontoname, Benutzername, Passwort) fest, die sicher in einer -Datei gespeichert sind (hinzugefügt zu config.py). .gitignore
Datenbelastung: Verwenden Sie die Snowpark -Sitzung, um auf die Daten zugreifen und in einen Snowpark -Datenframe zu laden.
verstehen
Snowpark -Datenrahmen arbeiten träge und bauen eine logische Darstellung von Operationen auf, bevor sie in optimierte SQL -Abfragen übertragen werden. Dies steht im Gegensatz zu Pandas 'eifriger Ausführung und bietet erhebliche Leistungssteigerungen, insbesondere bei großen Datensätzen.Wann verwenden Sie Snowpark -Datenrahmen:
Verwenden Sie Snowpark DataFrames für große Datensätze, bei denen das Übertragen von Daten auf Ihre lokale Maschine unpraktisch ist. Für kleinere Datensätze können Pandas ausreichen. Die
-Methode ermöglicht die Umwandlung zwischen Snowpark und Pandas DataFrames. Die to_pandas() -Methode bietet eine Alternative zum Ausführen von SQL -Abfragen direkt. Session.sql()
Snowparks Transformationsfunktionen (importiert als F aus snowflake.snowpark.functions) bieten eine leistungsstarke Schnittstelle für die Datenmanipulation. Diese Funktionen werden mit .select(), .filter() und .with_column() Methoden verwendet.
explorative Datenanalyse (EDA):
EDA kann durch Abtastung von Daten aus dem Snowpark -Datenframe, der Konvertierung in einen PANDAS -Datenframe und Verwendung von Visualisierungsbibliotheken wie Matplotlib und Seeborn durchgeführt werden. Alternativ können SQL -Abfragen Daten für Visualisierungen generieren.
Modell Training für maschinelles Lernen:
Datenreinigung: Stellen Sie sicher
Vorverarbeitung: Snowflake MLs mit Pipeline und OrdinalEncoder zur Vorverarbeitungsdaten verwenden. Speichern Sie die Pipeline mit StandardScaler. joblib
Modelltraining: trainieren Sie ein Xgboost -Modell () mit den vorverarbeiteten Daten. Teilen Sie die Daten in Trainings- und Testsätze mit XGBRegressor. random_split() auf.
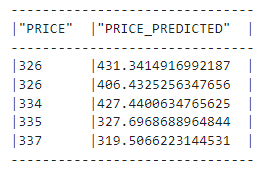
Modellbewertung: Bewerten Sie das Modell mithilfe von Metriken wie RMSE (mean_squared_error von snowflake.ml.modeling.metrics).
Hyperparameter -Tuning: Verwenden Sie RandomizedSearchCV, um Modellhyperparameter zu optimieren.
Modellsparung: Speichern Sie das geschulte Modell und seine Metadaten in der Modellregistrierung von Snowflake mithilfe der Registry -Klasse.
Inferenz: Führen Sie die Schlussfolgerung für neue Daten mit dem gespeicherten Modell aus der Registrierung durch.
Schlussfolgerung:
Snowpark bietet eine leistungsstarke und effiziente Möglichkeit, maschinelles Lernen von Daten zu führen. Die faule Bewertung, die Integration in vertraute Bibliotheken und die Modellregistrierung machen es zu einem wertvollen Instrument für den Umgang mit großen Datensätzen. Denken Sie daran, die Snowpark -API- und ML -Entwicklerführer zu konsultieren, um fortschrittlichere Funktionen und Funktionen zu erhalten.












Hinweis: Bild -URLs werden aus der Eingabe erhalten. Die Formatierung wird für eine bessere Lesbarkeit und einen besseren Fluss angepasst. Die technischen Details werden erhalten, aber die Sprache wird für ein breiteres Publikum prägnanter und zugänglicher.
Das obige ist der detaillierte Inhalt vonSnowflake Snowpark: Eine umfassende Einführung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Verwendung von uniqueResult
Verwendung von uniqueResult
 Die PHPStudy-Datenbank kann die Lösung nicht starten
Die PHPStudy-Datenbank kann die Lösung nicht starten
 So ermitteln Sie den Maximal- und Minimalwert eines Array-Elements in Java
So ermitteln Sie den Maximal- und Minimalwert eines Array-Elements in Java
 Einführung in die Bedeutung von Javascript
Einführung in die Bedeutung von Javascript
 So gehen Sie mit blockierten Dateidownloads in Windows 10 um
So gehen Sie mit blockierten Dateidownloads in Windows 10 um
 Welche Fensterfunktionen gibt es?
Welche Fensterfunktionen gibt es?
 Wie lösche ich den Speicherplatz für WPS-Cloud-Dokumente, wenn er voll ist?
Wie lösche ich den Speicherplatz für WPS-Cloud-Dokumente, wenn er voll ist?
 Der Unterschied zwischen ROM und RAM
Der Unterschied zwischen ROM und RAM








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



