

Die schnellen Fortschritte von
Ai überschreiten die Grenzen der maschinellen Fähigkeiten und übertreffen die Erwartungen von vor wenigen Jahren. Große Argumentationsmodelle (LRMs, beispielhaft durch OpenAI-O1) sind ausgefeilte Systeme, die sich durch einen schrittweisen Ansatz mit komplexen Problemen befassen. Diese Modelle lösen nicht nur Probleme. Sie begründen methodisch und verwenden Verstärkungslernen, um ihre Logik zu verfeinern und detaillierte, kohärente Lösungen zu erzeugen. Dieser absichtliche Prozess, der oft als "langsames Denken" bezeichnet wird, verbessert die logische Klarheit. Eine signifikante Einschränkung bleibt jedoch bestehen: Wissenslücken. LRMs können auf Unsicherheiten stoßen, die Fehler ausbreiten und die endgültige Genauigkeit beeinträchtigen. Traditionelle Lösungen wie die Erhöhung der Modellgröße und das Erweitern von Datensätzen, obwohl sie hilfreich sind, haben Einschränkungen und sogar die Methoden zur Erlangung von Abruf-Augmented-Generationen (Abrufen-Augmented Generation) mit hochkomplexem Denken.
Search-O1, ein von Forschern an der Universität von Renmin an der Universität China und der Tsinghua-Universität entwickeltes Rahmen, befasst sich mit diesen Einschränkungen. Es integriert nahtlos Aufgabenanweisungen, Fragen und dynamisches Wissen in eine zusammenhängende Argumentationskette, was logische Lösungen erleichtert. Search-O1 erweitert LRMs mit einem agierenden Lappenmechanismus und einem Modul im Dokumente, um abgerufene Informationen zu verfeinern.
Im Gegensatz zu herkömmlichen Modellen, die mit unvollständigem Wissen oder grundlegenden RAG-Methoden zu kämpfen haben, die häufig übermäßige, irrelevante Informationen abrufen, führt Search-O1 ein entscheidendes -Modul aus dem Grund in den Dokumenten ein . Dieses Modul destilliert umfangreiche Daten in präzise, logische Schritte und sorgt für Genauigkeit und Kohärenz.
Das Framework arbeitet iterativ und sucht dynamisch nach relevanten Dokumenten und extrahiert, verwandelt sie in genaue Argumentationsschritte und verfeinert den Prozess, bis eine vollständige Lösung erhalten wird. Es übertrifft traditionelle Argumentation (durch Wissenslücken behindert) und grundlegende Lag -Methoden (die den Argumentationsfluss stören). Durch einen agentenmechanismus für die Wissensintegration und die Aufrechterhaltung der Kohärenz gewährleistet Such-O1 zuverlässige und genaue Argumentation, wobei ein neuer Standard für eine komplexe Problemlösung in AI.
festgelegt wird.
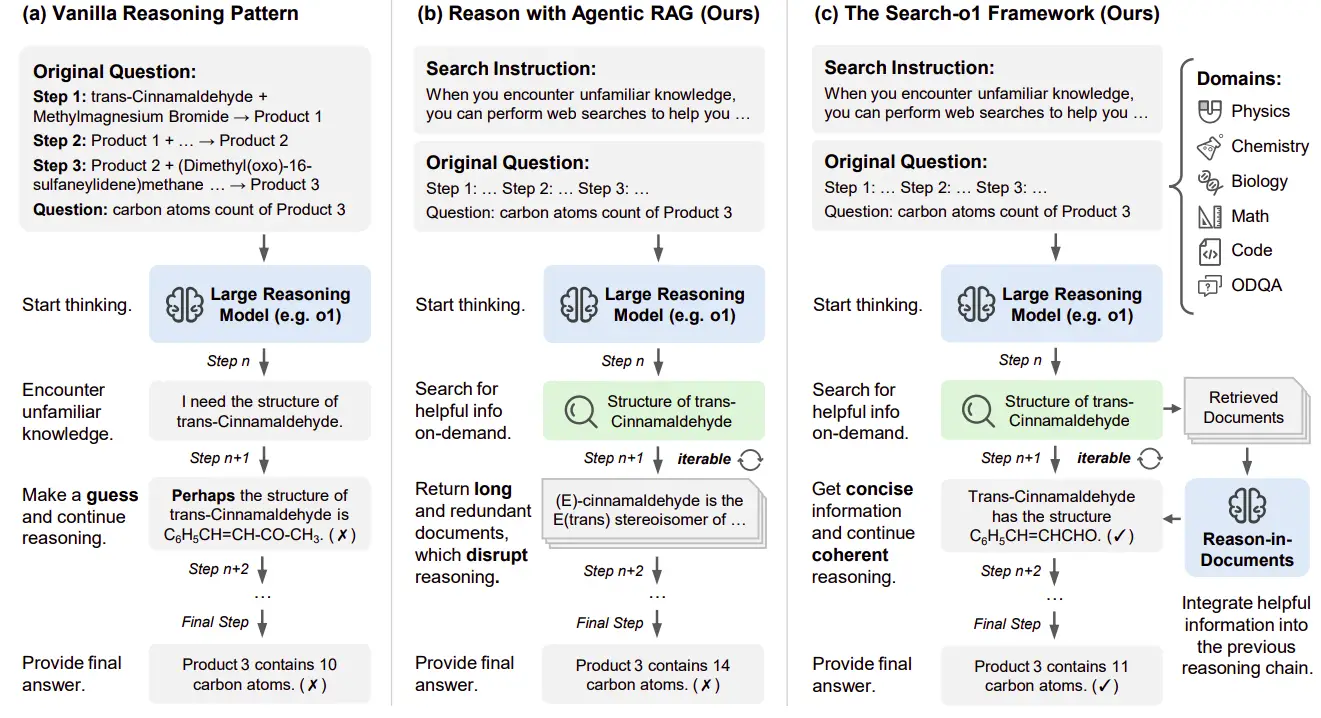
Search-O1 befasst sich mit Wissenslücken in LRMs, indem es nahtlos externe Wissensabrufe integriert, ohne den logischen Fluss zu stören. Die Forschung verglichen drei Ansätze: traditionelle Argumentation, Agentenlappen und das Such-O1-Framework.
Die Anzahl der Kohlenstoffatome in einem Endprodukt einer dreistufigen chemischen Reaktion dient als Beispiel. Traditionelle Methoden kämpfen bei der Begegnung mit Wissenslücken, beispielsweise ohne die Struktur von trans-cinnamaldehyd . Ohne genaue Informationen stützt sich das Modell auf Annahmen, die möglicherweise zu Fehlern führen.
Agentic Rag ermöglicht das Abrufen des autonomen Wissens. Wenn sie sich über die Struktur einer Verbindung nicht sicher sind, erzeugt sie spezifische Abfragen (z. B. "Struktur von trans-cinnamaldehyd "). Durch direkte Einbeziehung von langwierigen, oft irrelevanten abgerufenen Dokumenten stört jedoch den Argumentationsprozess und verringert die Kohärenz aufgrund von ausführlichen und tangentialen Informationen.
such-o1 verbessert den Agentenlappen mit dem Modul im Dokumenten im Dokumenten. Dieses Modul verfeinert abgerufene Dokumente in präzise Argumentationsschritte, wodurch externes Wissen nahtlos integriert wird und gleichzeitig den logischen Fluss erhalten bleibt. In Anbetracht der aktuellen Abfrage, der abgerufenen Dokumente und der sich entwickelnden Argumentationskette erzeugt sie iterativ kohärente, miteinander verbundene Schritte, bis eine schlüssige Antwort erreicht ist.
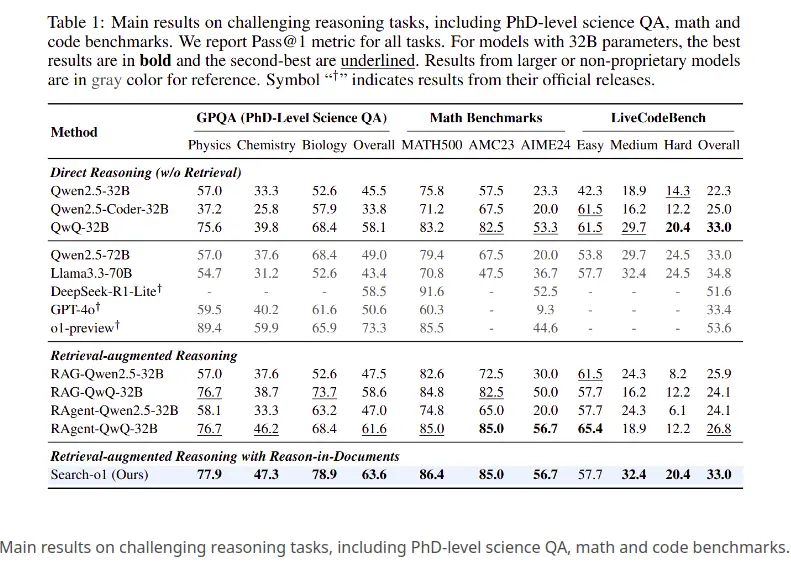
drei herausfordernde Argumentationsaufgaben wurden bewertet:
Schlüsselergebnisse :
Such-O1 erwies sich für alle Aufgaben als die effektivste Methode und setzte einen neuen Standard durch Kombination von Abruf und strukturiertem Denken. Der Framework befasst sich mit der Wissensinsuffizienz durch Integration von Lappen mit dem Modul im Dokumenten im Dokumenten und ermöglicht eine effektivere Verwendung von externem Wissen. Dies bildet eine starke Grundlage für zukünftige Forschungsergebnisse in Abrufsystemen, Dokumentenanalysen und intelligenter Problemlösung.
Diese Fallstudie zeigt, wie Search-O1 eine Chemie-Frage aus dem GPQA-Datensatz unter Verwendung von Abruf-ausgelöster Argumentation beantwortet.
Bestimmen Sie die Anzahl der Kohlenstoffatome im Endprodukt einer mehrstufigen Reaktion mit Trans-Cinnamaldehyd.
Das Modell kam zu dem Schluss, dass das Endprodukt 11 Kohlenstoffatome enthält (beginnend mit 9, eine aus der Grignard -Reaktion und im letzten Schritt eine andere hinzugefügt). Die Antwort ist 11.
such-o1 stellt einen signifikanten Fortschritt bei LRMs dar, wobei die Wissensinsuffizienz angesprochen wird. Durch die Integration von Agentenlappen und dem Dokumentenmodul ermöglicht es ein nahtloses iteratives Denken, das externes Wissen beinhaltet und gleichzeitig die logische Kohärenz aufrechterhält. Die überlegene Leistung in verschiedenen Domänen setzt einen neuen Standard für eine komplexe Problemlösung in der KI. Diese Innovation verbessert die Genauigkeit der Argumentation und eröffnet Wege für die Forschung in Abrufsystemen, Dokumentenanalysen und intelligenter Problemlösung, wodurch die Lücke zwischen dem Abrufen von Wissen und logischen Argumentation geschlossen wird. Search-O1 legt eine robuste Grundlage für die Zukunft der KI her, die effektivere Lösungen für komplexe Herausforderungen ermöglicht.
Das obige ist der detaillierte Inhalt vonWie verbessert Such-O1 den logischen Fluss im KI-Argumentation?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



