

chinesische KI macht erhebliche Fortschritte und forderte führende Modelle wie GPT-4, Claude und Grok mit kostengünstigen Open-Source-Alternativen wie Deepseek-V3 und Qwen 2.5. Diese Modelle zeichnen sich aufgrund ihrer Effizienz, Zugänglichkeit und starker Leistung aus. Viele arbeiten unter zulässigen kommerziellen Lizenzen und erweitern ihre Berufung auf Entwickler und Unternehmen.
Minimax-Text-01, die neueste Ergänzung dieser Gruppe, setzt einen neuen Standard mit seiner beispiellosen 4-Millionen-Token-Kontextlänge und übertrifft die typische 128K-256-K-Token-Grenze. Diese erweiterte Kontextfähigkeit in Kombination mit einer hybriden Aufmerksamkeitsarchitektur für Effizienz und einer Open-Source-Lizenz fördert Innovation ohne hohe Kosten.
Lassen Sie uns in die Funktionen von Minimax-Text-01 eintauchen:
minimax-text-01 gleicht Effizienz und Leistung geschickt aus, indem sie die Aufmerksamkeit der Blitze, die Aufmerksamkeit von Softmax und die Expertenmischung (MOE) integrieren.
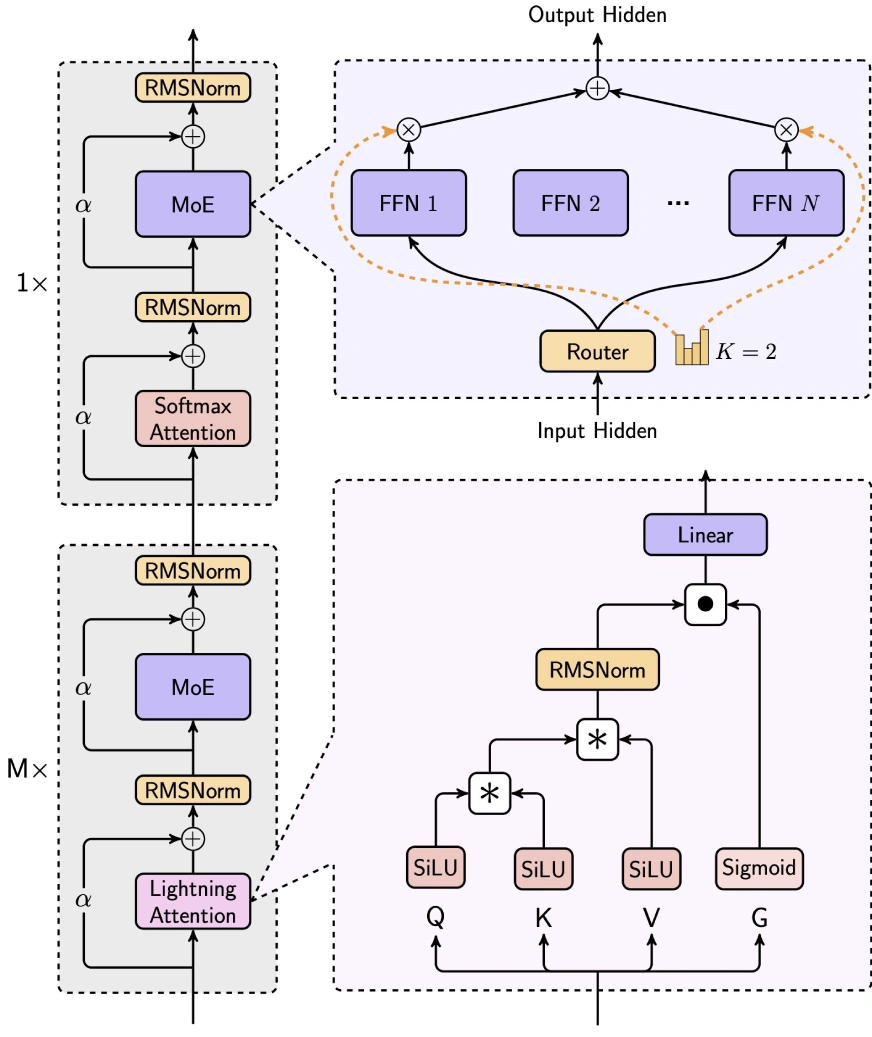
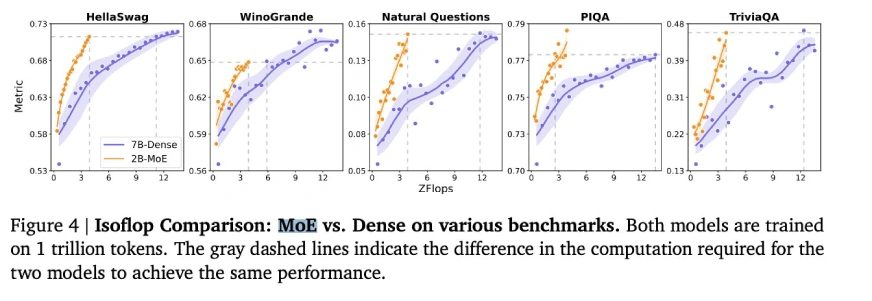
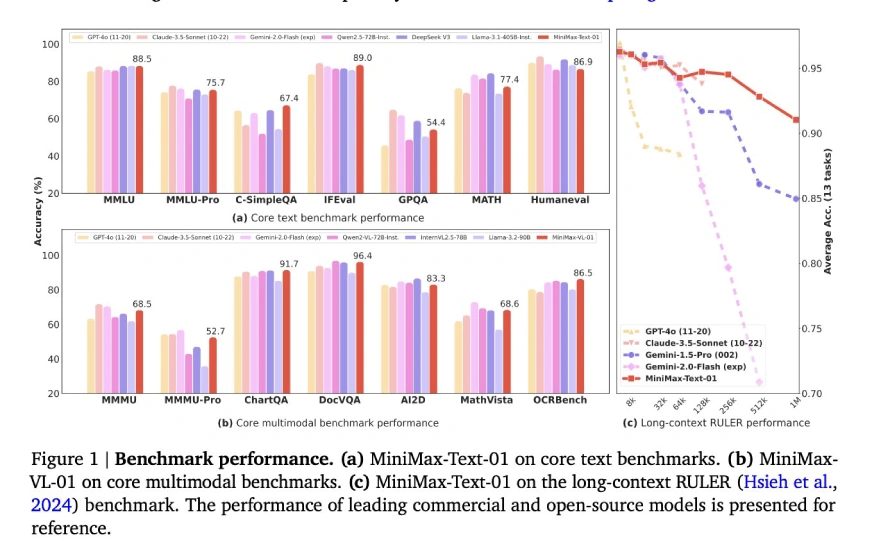
(Tabellen, die Benchmark -Ergebnisse für allgemeine Aufgaben, Argumentationsaufgaben und Mathematik- und Codierungsaufgaben enthalten, sind hier enthalten, die die Tabellen der ursprünglichen Eingabe spiegeln.)

(zusätzliche Bewertungsparameter verbleiben)
(Code-Beispiel für die Verwendung von Minimax-Text-01 mit umarmenden Gesichtstransformatoren bleibt gleich.)
minimax-text-01 zeigt beeindruckende Fähigkeiten und erzielte eine modernste Leistung bei langen Kontext- und allgemeinen Aufgaben. Während Verbesserungsbereiche existieren, machen seine Open-Source-Natur, die Kosteneffizienz und die innovative Architektur es zu einem bedeutenden Akteur im KI-Bereich. Es ist besonders für speicherintensive und komplexe Argumentationsanwendungen geeignet, obwohl eine weitere Verfeinerung der Codierungsaufgaben von Vorteil sein kann.
Das obige ist der detaillierte Inhalt von4m Token? Minimax-text-01 übertrifft Deepseek v3. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verwenden Sie Left Join
So verwenden Sie Left Join
 So überprüfen Sie den Portstatus mit netstat
So überprüfen Sie den Portstatus mit netstat
 Die Speicherlösung kann nicht geschrieben werden
Die Speicherlösung kann nicht geschrieben werden
 was bedeutet PM
was bedeutet PM
 So erhöhen Sie die Download-Geschwindigkeit
So erhöhen Sie die Download-Geschwindigkeit
 vscode Chinesische Einstellungsmethode
vscode Chinesische Einstellungsmethode
 Alle Verwendungen von Cloud-Servern
Alle Verwendungen von Cloud-Servern
 So lösen Sie das Problem, dass Tomcat die Seite nicht anzeigen kann
So lösen Sie das Problem, dass Tomcat die Seite nicht anzeigen kann








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



