

Dieses Tutorial für die DataCamp-Community, die für Klarheit und Genauigkeit bearbeitet wurde, untersucht die Modelle der Bild-Text-Grundlage und konzentriert sich auf das innovative Contrastive Captioner (CoCA) -Modell. Coca kombiniert kontrastive und generative Lernziele einzigartig und integrieren die Stärken von Modellen wie Clip und Simvlm in eine einzelne Architektur.

Fundamentmodelle: Ein tiefes Tauchgang
Fundamentmodelle, die auf massiven Datensätzen vorgebracht sind, sind für verschiedene nachgeschaltete Aufgaben anpassbar. Während NLP einen Anstieg der Fundamentmodelle (GPT, Bert) verzeichnet hat, entwickeln sich auch immer noch die Modelle für Visionen und Visionsprachen. Untersuchungen haben drei primäre Ansätze untersucht: Einzel-Encoder-Modelle, Image-Text-Dual-Coder mit kontrastivem Verlust und Encoder-Decoder-Modellen mit generativen Zielen. Jeder Ansatz hat Einschränkungen.
Schlüsselbegriffe:
Modellvergleiche:
Coca: Überbrückung der Lücke
coca zielt darauf ab, die Stärken kontrastiver und generativer Ansätze zu vereinen. Es verwendet einen kontrastiven Verlust, um Bild- und Textdarstellungen und ein generatives Ziel (Bildunterschriftenverlust) auszurichten, um eine gemeinsame Darstellung zu erzeugen.
Coca -Architektur:
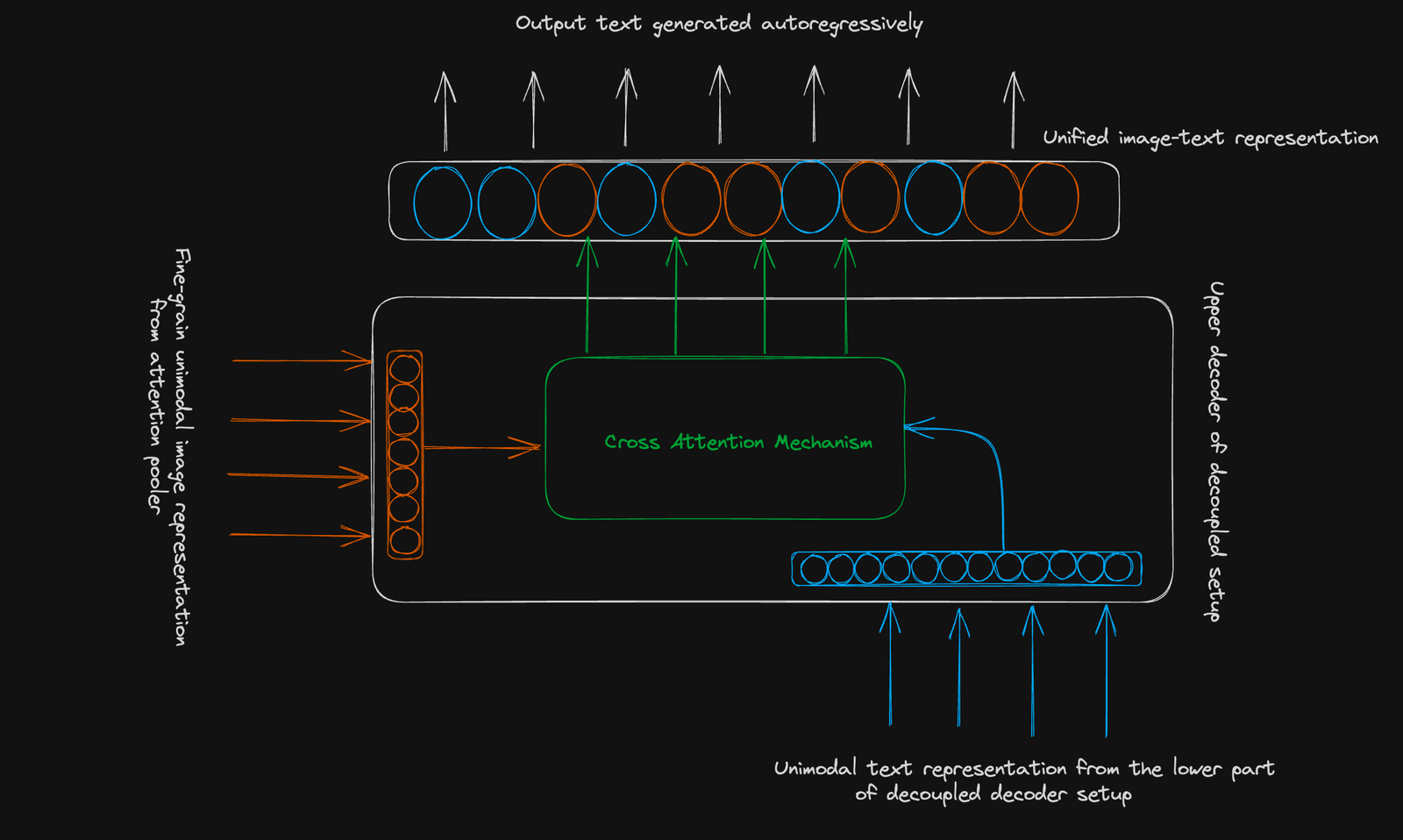
Coca verwendet eine Standard-Encoder-Decoder-Struktur. Seine Innovation liegt in einem entkoppelten Decoder :
Kontrastes Ziel: lernt, im Zusammenhang mit Bildtextpaaren zu clusterbezogenen und nicht verwandten, in einem gemeinsam genutzten Vektorraum getrennt. Eine einzelne gepoolte Bildeinbettung wird verwendet.
generatives Ziel: verwendet eine feinkörnige Bilddarstellung (256-dimensionale Sequenz) und die modale Aufmerksamkeit, um Text autoregressiv vorherzusagen.

Schlussfolgerung:
coca stellt einen signifikanten Fortschritt in den Modellen der Bild-Text-Grundlage dar. Der kombinierte Ansatz verbessert die Leistung in verschiedenen Aufgaben und bietet ein vielseitiges Tool für nachgeschaltete Anwendungen. Um Ihr Verständnis für fortgeschrittene Deep -Learning -Konzepte zu fördern, betrachten Sie DataCamps fortgeschrittenes Deep Learning mit Keras -Kurs.
Weitere Lesen:
Das obige ist der detaillierte Inhalt vonKoka: Kontrastive Bildunterschriften sind Bild-Text-Fundamentmodelle visuell erklärt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



