

Erkundung von Einbettungsmodellen mit Scheitelpunkt KI

Vektoreinbettungen sind für viele fortschrittliche KI -Anwendungen von grundlegender Bedeutung, einschließlich semantischer Suche und Anomalieerkennung. Dieser Artikel bietet ein grundlegendes Verständnis von Einbettungen und konzentriert sich auf Satzeinbettungen und Vektordarstellungen. Wir werden praktische Techniken wie das mittlere Pooling und die Ähnlichkeit des Cosinus untersuchen, die Architektur von Doppelcodierern unter Verwendung von Bert eintauchen und ihre Anwendung bei der Erkennung von Anomalie mit Scheitelpunkt -AI für Aufgaben wie Betrugserkennung und Inhalts Moderation untersuchen.
Wichtige Lernziele
- Erfassen Sie die Rolle von Vektor -Einbettungen bei der Darstellung von Wörtern, Sätzen und anderen Datentypen innerhalb eines kontinuierlichen Vektorraums.
- Verstehen Sie die Tokenisierung und die Einbettung von token-Einbettungen tragen zu Einbettungen auf Satzebene bei.
- Lernen Sie Schlüsselkonzepte und Best Practices für die Bereitstellung von Einbettungsmodellen mithilfe von Vertex AI, um die realen KI-Herausforderungen zu bewältigen.
- Entdecken Sie, wie Sie Anwendungen mit der Vertex-KI optimieren und skalieren, indem Sie Einbettungsmodelle für verbesserte Analysen und Entscheidungen integrieren.
- Sammeln Sie praktische Erfahrung in der Schulung eines Dual-Encoder-Modells und definieren Sie deren Architektur und Schulungsprozess.
- Implementieren Sie die Erkennung von Anomalie unter Verwendung von Methoden wie Isolation Forest, um Ausreißer auf der Grundlage der Einbettung der Ähnlichkeit zu identifizieren.
*Dieser Artikel ist Teil des *** Data Science Blogathon.
Inhaltsverzeichnis
- Vertex -Einbettungen verstehen
- Satzeinbettungen erklärt
- Cosinus -Ähnlichkeit in Satzbettdings
- Training eines Dual -Encoder -Modells
- Doppelcodierer für Frage-Beantwortung
- Der Dual -Encoder -Trainingsprozess
- Einbettung mit Scheitelpunktki nutzen
- Datensatzerstellung vom Stapelüberlauf
- Erzeugen von Texteinbettungen
- Batch -Einbettungsgenerierung
- Anomalie -Identifizierung
- Isolationswald zur Ausreißererkennung
- Abschluss
- Häufig gestellte Fragen
Vertex -Einbettungen verstehen
Vektoreinbettungen repräsentieren Wörter oder Sätze innerhalb eines definierten Raums. Die Nähe dieser Vektoren bedeutet Ähnlichkeit; Nahe Vektoren weisen auf eine größere semantische Ähnlichkeit hin. Während sie ursprünglich hauptsächlich in NLP verwendet werden, erstreckt sich ihre Anwendung auf Bilder, Videos, Audio und Grafiken. Clip, ein herausragendes multimodales Lernmodell, erzeugt sowohl Bild- als auch Texteinbettungen.
Zu den wichtigsten Anwendungen von Vektoreinbettungen gehören:
- LLMs verwenden sie als Token -Einbettung nach Eingabe -Token -Umwandlung.
- Die semantische Suche setzt sie ein, um die relevantesten Antworten auf Fragen zu finden.
- Bei der Abruf Augmented Generation (LAV) erleichtern Satzeinbettungen das Abrufen relevanter Informationsbrocken.
- Empfehlungssysteme verwenden sie, um Produkte darzustellen und verwandte Elemente zu identifizieren.
Lassen Sie uns die Bedeutung von Satzbettdings in Lag -Pipelines untersuchen.
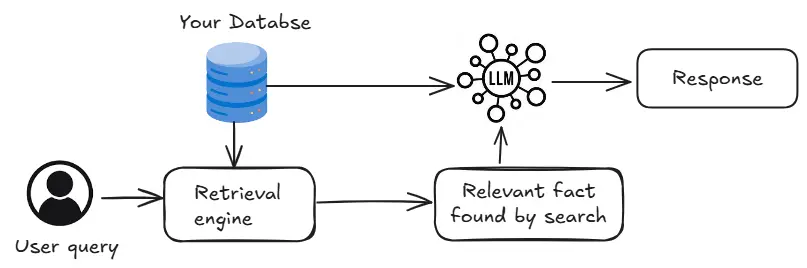
Die Abruf -Engine im obigen Diagramm identifiziert Datenbankinformationen, die für Benutzerabfragen relevant sind. Transformator-basierte Crosscoder können Abfragen mit allen Informationen vergleichen und die Relevanz klassifizieren. Dies ist jedoch langsam. Vektordatenbanken bieten eine schnellere Alternative durch Speichern von Einbetten und Verwendung von Ähnlichkeitssuche, obwohl die Genauigkeit möglicherweise geringfügig niedriger ist.
Satzeinbettungen verstehen
Satzeinbettungen werden erstellt, indem mathematische Operationen auf Token-Einbettungen angewendet werden, die häufig von vorgebauten Modellen wie Bert oder GPT erzeugt werden. Der folgende Code zeigt das mittlere Zusammenhang von Bert-generierten Token-Einbettungen, um Satz Einbettungen zu erstellen:
model_name = "./models/bert-base-uncased"
tokenizer = BertTokenizer.from_Pretraination (model_name)
Modell = Bertmodel.From_Pretrained (model_name)
Def get_sentence_embedding (Satz):
coded_input = Tokenizer (Satz, Padding = true, truncation = true, return_tensors = 'pt'))
Achtung_mask = coded_input ['Achtung_mask']
mit fackel.no_grad ():
output = modell (** coded_input)
token_embeddings = output.last_hidden_state
input_mask_expanded = repualting_mask.unsqueeze (-1) .expand (token_embeddings.size ()). float ())
SUPPLY_EMBEDDING = TORCH.SUM (token_embeddings * input_mask_expanded, 1) / fackel.clamp (input_mask_expanded.sum (1), min = 1e-9)
return SUTE_embedding.flatten (). Tolist ()Dieser Code lädt ein Bert -Modell und definiert eine Funktion zur Berechnung von Satzbetten mithilfe von mittlerem Pooling.
Cosinus -Ähnlichkeit von Satz Einbettungen
Die Ähnlichkeit der Kosinus misst die Ähnlichkeit zwischen zwei Vektoren und ist für den Vergleich von Satzbettendings geeignet. Der folgende Code implementiert die Ähnlichkeit und Visualisierung der Kosinus: Visualisierung:
Def Coine_similarity_matrix (Funktionen):
Normen = np.linalg.norm (Merkmale, Achse = 1, Keepdims = True)
Normalized_Features = Merkmale / Normen
Ähnlichkeit_Matrix = np.innner (Normalized_Features, Normalized_Features)
rundered_similarity_matrix = np.round (yexity_matrix, 4)
Return Rounded_similarity_Matrix
Def Plot_similarity (Beschriftungen, Merkmale, Rotation):
SIM = Coine_similarity_matrix (Funktionen)
snsset_theme (font_scale = 1.2)
g = sns.heatmap (SIM, XtickLabels = Labels, yticklabels = Labels, vmin = 0, vmax = 1, cmap = "ylorrd")
g.set_xticklabels (Etiketten, Rotation = Rotation)
g.set_title ("semantische textuelle Ähnlichkeit")
Rückkehr g
Nachrichten = [
# Technologie
"Ich benutze lieber ein MacBook für die Arbeit.",
"Übernimmt KI menschliche Jobs?",
"Mein Laptop -Akku fließt zu schnell ab."
# Sport
"Hast du letzte Nacht das Finale der Weltmeisterschaft gesehen?",
"LeBron James ist ein unglaublicher Basketballspieler."
"Ich mag es, am Wochenende Marathons zu rennen."
# Reisen
"Paris ist eine schöne Stadt zu besuchen."
"Was sind die besten Orte, um im Sommer zu reisen?",
"Ich liebe es, in den Schweizer Alpen zu wandern."
# Unterhaltung
"Der neueste Marvel -Film war fantastisch!",
"Hörst du Taylor Swifts Songs?",
"Ich habe eine ganze Staffel meiner Lieblingsserie angesehen."
]
Einbettungen = []
Für T in Nachrichten:
emb = get_sentce_embedding (t)
Einbettungen.Append (emb)
Plot_similarity (Nachrichten, Einbettungen, 90)Dieser Code definiert Sätze, generiert Einbettungen und plant eine Heatmap, die ihre Kosinusähnlichkeit zeigt. Die Ergebnisse könnten unerwartet hohe Ähnlichkeit aufweisen und die Erforschung genauerer Methoden wie Dual -Encoder motivieren.
(Die verbleibenden Abschnitte werden in ähnlicher Weise fortgesetzt, um den ursprünglichen Text zu paraphrasieren und umstrukturieren, während die Kerninformationen beibehalten und die Bildstandorte und Formate erhalten bleiben.)
Das obige ist der detaillierte Inhalt vonErkundung von Einbettungsmodellen mit Scheitelpunkt KI. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Der Artikel überprüft Top -KI -Kunstgeneratoren, diskutiert ihre Funktionen, Eignung für kreative Projekte und Wert. Es zeigt MidJourney als den besten Wert für Fachkräfte und empfiehlt Dall-E 2 für hochwertige, anpassbare Kunst.
 Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Metas Lama 3.2: Ein Sprung nach vorne in der multimodalen und mobilen KI Meta hat kürzlich Lama 3.2 vorgestellt, ein bedeutender Fortschritt in der KI mit leistungsstarken Sichtfunktionen und leichten Textmodellen, die für mobile Geräte optimiert sind. Aufbau auf dem Erfolg o
 Beste AI -Chatbots verglichen (Chatgpt, Gemini, Claude & amp; mehr)
Apr 02, 2025 pm 06:09 PM
Beste AI -Chatbots verglichen (Chatgpt, Gemini, Claude & amp; mehr)
Apr 02, 2025 pm 06:09 PM
Der Artikel vergleicht Top -KI -Chatbots wie Chatgpt, Gemini und Claude und konzentriert sich auf ihre einzigartigen Funktionen, Anpassungsoptionen und Leistung in der Verarbeitung und Zuverlässigkeit natürlicher Sprache.
 Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
In dem Artikel werden Top -KI -Schreibassistenten wie Grammarly, Jasper, Copy.ai, Writesonic und RYTR erläutert und sich auf ihre einzigartigen Funktionen für die Erstellung von Inhalten konzentrieren. Es wird argumentiert, dass Jasper in der SEO -Optimierung auszeichnet, während KI -Tools dazu beitragen, den Ton zu erhalten
 Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Das jüngste Memo von Shopify -CEO Tobi Lütke erklärt kühn für jeden Mitarbeiter eine grundlegende Erwartung und kennzeichnet eine bedeutende kulturelle Veränderung innerhalb des Unternehmens. Dies ist kein flüchtiger Trend; Es ist ein neues operatives Paradigma, das in P integriert ist
 AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
Die KI -Landschaft dieser Woche: Ein Wirbelsturm von Fortschritten, ethischen Überlegungen und regulatorischen Debatten. Hauptakteure wie OpenAI, Google, Meta und Microsoft haben einen Strom von Updates veröffentlicht, von bahnbrechenden neuen Modellen bis hin zu entscheidenden Verschiebungen in LE
 10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
Hey da, codieren Ninja! Welche Codierungsaufgaben haben Sie für den Tag geplant? Bevor Sie weiter in diesen Blog eintauchen, möchte ich, dass Sie über all Ihre Coding-Leiden nachdenken-die Auflistung auflisten diese auf. Erledigt? - Lassen Sie ’
 Auswahl des besten KI -Sprachgenerators: Top -Optionen überprüft
Apr 02, 2025 pm 06:12 PM
Auswahl des besten KI -Sprachgenerators: Top -Optionen überprüft
Apr 02, 2025 pm 06:12 PM
Der Artikel überprüft Top -KI -Sprachgeneratoren wie Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson und Descript, wobei sie sich auf ihre Funktionen, die Sprachqualität und die Eignung für verschiedene Anforderungen konzentrieren.
