

Deep Learning CPU -Benchmarks

Deep Learning GPU -Benchmarks hat die Art und Weise, wie wir komplexe Probleme lösen, von der Bilderkennung bis zur Verarbeitung natürlicher Sprache revolutioniert. Während das Training dieser Modelle häufig auf Hochleistungs-GPUs beruht, stellen sie effektiv in ressourcenbezogenen Umgebungen wie Edge-Geräten oder Systemen mit begrenzten Hardware ein. CPUs, das weit verbreitet und kostengünstig ist, dient häufig als Rückgrat für die Schlussfolgerung in solchen Szenarien. Aber wie stellen wir sicher, dass die auf CPUs bereitgestellten Modelle eine optimale Leistung bieten, ohne die Genauigkeit zu beeinträchtigen?
Dieser Artikel taucht in das Benchmarking von Deep Learning Model -Inferenz auf CPUs ein und konzentriert sich auf drei kritische Metriken: Latenz, CPU -Nutzung und Speicherauslastung. Mit einem Spam -Klassifizierungsbeispiel untersuchen wir, wie beliebte Frameworks wie Pytorch, TensorFlow, JAX und ONNX -Laufzeit -Griff -Inferenz -Workloads. Am Ende haben Sie ein klares Verständnis für die Messung der Leistung, die Optimierung der Bereitstellungen und die Auswahl der richtigen Tools und Frameworks für CPU-basierte Inferenz in ressourcenbeschränkten Umgebungen.
Auswirkung: Eine optimale Ausführung von Inferenz kann einen erheblichen Geldbetrag einsparen und Ressourcen für andere Workloads freilegen.
Lernziele
- Verstehen Sie die Rolle von Deep Learning CPU -Benchmarks bei der Beurteilung der Hardwareleistung für KI -Modelltraining und -inferenz.
- Bewerten Sie Pytorch, TensorFlow, Jax, Onnx Runtime und OpenVino Runtime, um das Beste für Ihre Anforderungen zu wählen.
- Master Tools wie Psutil und Zeit, um genaue Leistungsdaten zu sammeln und die Inferenz zu optimieren.
- Bereiten Sie Modelle vor, führen Sie Inferenz aus und messen Sie die Leistung und wenden Sie Techniken auf verschiedene Aufgaben wie Bildklassifizierung und NLP an.
- Identifizieren Sie Engpässe, optimieren Sie Modelle und verbessern Sie die Leistung, während die Ressourcen effizient verwalten.
Dieser Artikel wurde als Teil des Data Science -Blogathons veröffentlicht.
Inhaltsverzeichnis
- Optimierung der Inferenz mit der Laufzeitbeschleunigung
- Modellinferenzleistung Metriken
- Annahmen und Einschränkungen
- Tools und Frameworks
- Abhängigkeiten installieren
- Problemanweisung und Eingabespezifikation
- Models Architektur und Formate
- Beispiele für zusätzliche Netzwerke für Benchmarking
- Benchmarking Workflow
- Benchmarking -Funktion definiton
- Modellinferenz und Durchführen von Benchmarking für jeden Framework
- Ergebnisse und Diskussion
- Abschluss
- Häufig gestellte Fragen
Optimierung der Inferenz mit der Laufzeitbeschleunigung
Inferenzgeschwindigkeit ist für die Benutzererfahrung und die Betriebseffizienz in maschinellen Lernanwendungen von wesentlicher Bedeutung. Die Laufzeitoptimierung spielt eine Schlüsselrolle bei der Verbesserung dieser Durchführung der Ausführung. Die Verwendung von Bibliotheken mit Hardware-Beschleunigungsbibliotheken wie Onnx-Laufzeit nutzt Optimierungen, die auf bestimmte Architekturen zugeschnitten sind und die Latenz verringern (Zeit pro Inferenz).
Darüber hinaus minimieren leichte Modellformate wie ONNX den Overhead und ermöglichen eine schnellere Belastung und Ausführung. Optimierte Laufzeiten nutzen die parallele Verarbeitung, um die Berechnung über verfügbare CPU -Kerne auf und verbessert das Speichermanagement zu verbessern, um eine bessere Leistung zu gewährleisten, insbesondere bei Systemen mit begrenzten Ressourcen. Dieser Ansatz macht die Modelle schneller und effizienter, während die Genauigkeit aufrechterhalten wird.
Modellinferenzleistung Metriken
Um die Leistung unserer Modelle zu bewerten, konzentrieren wir uns auf drei Schlüsselmetrik:
Latenz
- Definition: Latenz bezieht sich auf die Zeit, die das Modell benötigt, um nach Eingang eine Vorhersage zu machen. Dies wird häufig als die Zeit gemessen, die vom Senden der Eingabedaten an den Empfang der Ausgabe (Vorhersage) benötigt wird (Vorhersage)
- Wichtigkeit : Bei Anwendungen in Echtzeit- oder Nahverkehrszeit führt eine hohe Latenz zu Verzögerungen, was zu langsameren Antworten führen kann.
- Messung : Die Latenz wird in Millisekunden (MS) oder Sekunden (n) in der Regel gemessen. Kürzere Latenz bedeutet, dass das System für Anwendungen, die sofortige Entscheidungsfindung oder Maßnahmen erfordern, reaktionsschneller und effizienter und entscheidend ist.
CPU -Nutzung
- Definition : Die CPU -Nutzung ist der Prozentsatz der Verarbeitungsleistung der CPU, die bei der Ausführung von Inferenzaufgaben verbraucht wird. Es zeigt Ihnen, wie viel von den Berechnungsressourcen des Systems während der Modellinferenz verwendet wird.
- Bedeutung : Hohe CPU -Verwendung bedeutet, dass die Maschine möglicherweise Schwierigkeiten hat, andere Aufgaben gleichzeitig zu erledigen, was zu Engpässen führt. Die effiziente Verwendung von CPU -Ressourcen stellt sicher, dass die Modellinferenz die Systemressourcen nicht monopolisiert.
- Messemen T: Es wird typischerweise als Prozentsatz (%) der gesamten verfügbaren CPU -Ressourcen gemessen. Eine geringere Auslastung für dieselbe Arbeitsbelastung zeigt im Allgemeinen ein optimierteres Modell an, wobei die CPU -Ressourcen effektiver verwendet werden.
Speicherauslastung
- Definition: Speicherauslastung bezieht sich auf die Menge an RAM, die vom Modell während des Inferenzprozesses verwendet wird. Es verfolgt den Speicherverbrauch durch die Parameter des Modells, die Zwischenberechnungen und die Eingabedaten.
- Wichtigkeit: Die Optimierung des Speicherverbrauchs ist besonders wichtig, wenn Modelle für Edge -Geräte oder Systeme einbezogen werden, wenn ein begrenzter Speicher ist. Ein hoher Speicherverbrauch kann zu Speicherüberfluss, langsamerer Verarbeitung oder Systemabstürzen führen.
- Messung: Die Speicherauslastung wird in Megabyte (MB) oder Gigabyte (GB) gemessen. Durch die Verfolgung des Speicherverbrauchs in unterschiedlichen Inferenzstadien können Speicher -Ineffizienzen oder Speicherlecks identifiziert werden.
Annahmen und Einschränkungen
Um diese Benchmarking -Studie fokussiert und praktisch zu halten, haben wir die folgenden Annahmen getroffen und einige Grenzen festgelegt:
- Hardwarebeschränkungen : Die Tests sind so ausgelegt, dass sie auf einer einzigen Maschine mit begrenzten CPU -Kernen ausgeführt werden. Während moderne Hardware in der Lage ist, parallele Workloads zu bearbeiten, spiegelt dieser Einrichtungseinschränkungen die häufig auf Kantengeräte oder im Bereich kleineren Bereitstellungen angezeigten Einschränkungen wider.
- Keine Multi-System-Parallelisierung : Wir haben keine verteilten Computer-Setups oder Cluster-basierte Lösungen integriert. Die Benchmarks spiegeln Leistungs eigenständige Bedingungen wider, die für Umgebungen mit nur begrenzten CPU-Kernen und Speicher für einzelne Knoten geeignet sind.
- Umfang : Der Hauptaugenmerk liegt nur auf der CPU -Inferenzleistung. Während GPU-basierte Inferenz eine hervorragende Option für ressourcenintensive Aufgaben ist, zielt dieses Benchmarking darauf ab, Einblicke in CPU-Setups zu geben, die bei kostenempfindlichen oder tragbaren Anwendungen häufiger auftreten.
Diese Annahmen stellen sicher, dass die Benchmarks für Entwickler und Teams, die mit ressourcenbeschränkten Hardware arbeiten oder die vorhersehbare Leistung benötigen, ohne die zusätzliche Komplexität der verteilten Systeme relevant bleiben.
Tools und Frameworks
Wir werden die wesentlichen Tools und Frameworks untersuchen, die zum Benchmark und Optimieren von Deep-Learning-Modell-Inferenz für CPUs verwendet werden, und geben Einblicke in ihre Funktionen für eine effiziente Ausführung in ressourcenbezogenen Umgebungen.
Profiling -Werkzeuge
- Python Time (Zeitbibliothek) : Die Zeitbibliothek in Python ist ein leichtes Tool zur Messung der Ausführungszeit von Codeblöcken. Durch die Aufzeichnung der Start- und Endzeitstempel hilft es, die Zeit für Operationen wie Modellinferenz oder Datenverarbeitung zu berechnen.
- PSUTIL (CPU, Speicherprofilerstellung) : PSUTI L ist eine Python -Bibliothek für die Überwachung und Profilierung von Nachhalten. Es enthält Echtzeitdaten zu CPU-Verwendung, Speicherverbrauch, Festplatten-I/O und mehr, was es ideal für die Analyse der Verwendung während des Modelltrainings oder der Inferenz ist.
Frameworks für Inferenz
- TensorFlow : Ein robustes Rahmen für tiefes Lernen, das sowohl für Trainings- als auch für Inferenzaufgaben häufig verwendet wird. Es bietet eine starke Unterstützung für verschiedene Modelle und Bereitstellungsstrategien.
- Pytorch: Pytorch ist für seine Benutzerfreundlichkeit und dynamische Berechnungsdiagramme bekannt und ist eine beliebte Wahl für Forschung und Produktionsbereitstellung.
- ONNX-Laufzeit : Eine open-Source-plattformübergreifende Engine für die laufenden ONXX-Modelle (Open Neural Network Exchange), die eine effiziente Inferenz in verschiedenen Hardware und Frameworks liefert.
- JAX : Ein funktionales Framework, das sich auf numerische Computing und maschinelles Lernen von Hochleistungen konzentriert und automatische Differenzierung und GPU/TPU-Beschleunigung bietet.
- OpenVino: OpenVino optimiert für Intel Hardware bietet Tools für die Modelloptimierung und Bereitstellung von Intel CPUs, GPUs und VPUs.
Hardwarespezifikation und Umgebung
Wir verwenden Github -Codesspace (virtuelle Maschine) mit der folgenden Konfiguration:
- Spezifikation der virtuellen Maschine: 2 Kerne, 8 GB RAM und 32 GB Speicherplatz
- Python -Version: 3.12.1
Abhängigkeiten installieren
Die Versionen der verwendeten Pakete sind wie folgt und in dieser Primärin gehören fünf Deep Learning Inference -Bibliotheken: TensorFlow, Pytorch, Onnx -Laufzeit, Jax und OpenVino:
! PIP Installieren Sie Numpy == 1.26.4 ! PIP Installieren Sie Taschenlampe == 2.2.2 ! PIP Installieren Sie TensorFlow == 2.16.2 ! PIP Installation Onnx == 1.17.0 ! PIP Installieren Sie OnnxRuntime == 1.17.0! ! PIP Installieren Sie JAXLIB == 0.4.30 ! PIP Installieren Sie OpenVino == 2024.6.0 ! PIP Installieren Sie Matplotlib == 3.9.3 ! PIP Installieren Sie Matplotlib: 3.4.3 ! Pip -Kissen installieren: 8.3.2 ! PIP Installieren Sie PSUTIL: 5.8.0
Problemanweisung und Eingabespezifikation
Da Modellinferenz darin besteht, einige Matrixoperationen zwischen Netzwerkgewichten und Eingabedaten auszuführen, erfordert kein Modelltraining oder Datensätze. Für unser Beispiel als Benchmarking -Prozess simuliert wir einen Standard -Klassifizierungs -Anwendungsfall. Dies simuliert gemeinsame Binärklassifizierungsaufgaben wie Spam -Erkennung und Darlehensantragsentscheidungen (Genehmigung oder Ablehnung). Die binäre Natur dieser Probleme macht sie ideal, um die Modellleistung über verschiedene Frameworks hinweg zu vergleichen. Dieses Setup spiegelt reale Systeme wider, ermöglicht es uns jedoch, uns auf die Inferenzleistung über Frameworks hinweg zu konzentrieren, ohne große Datensätze oder vorgebrachte Modelle zu benötigen.
Problemanweisung
Die Stichprobenaufgabe umfasst die Vorhersage, ob eine bestimmte Stichprobe Spam ist oder nicht (Kreditgenehmigung oder Ablehnung), basierend auf einer Reihe von Eingabefunktionen. Dieses Binärklassifizierungsproblem ist rechnerisch effizient und ermöglicht eine fokussierte Analyse der Inferenzleistung ohne die Komplexität von Klassifizierungsaufgaben mit mehreren Klassen.
Eingabespezifikation
Um reale E-Mail-Daten zu simulieren, haben wir zufällig Eingaben generiert. Diese Einbettungen imitieren die Art der Daten, die möglicherweise von Spam -Filtern verarbeitet werden könnten, aber die Notwendigkeit externer Datensätze vermeiden. Diese simulierten Eingabedaten ermöglichen das Benchmarking, ohne sich auf bestimmte externe Datensätze zu verlassen, sodass es ideal zum Testen von Modellinferenzzeiten, Speicherverbrauch und CPU -Leistung. Alternativ können Sie Bildklassifizierung, NLP -Aufgabe oder andere Deep -Lern -Aufgaben verwenden, um diesen Benchmarking -Prozess auszuführen.
Models Architektur und Formate
Die Modellauswahl ist ein kritischer Schritt beim Benchmarking, da sie die Inferenzleistung und die Erkenntnisse, die aus dem Profilerstellungsprozess gewonnen wurden, direkt beeinflusst. Wie im vorherigen Abschnitt erwähnt, haben wir für diese Benchmarking -Studie einen Standard -Klassifizierungs -Anwendungsfall ausgewählt, der feststellt, ob eine bestimmte E -Mail Spam ist oder nicht. Diese Aufgabe ist ein unkompliziertes Problem der Zweiklasse-Klassifizierung, das rechnerisch effizient ist und dennoch aussagekräftige Ergebnisse für den Vergleich über Rahmenbedingungen liefert.
Models Architektur zum Benchmarking
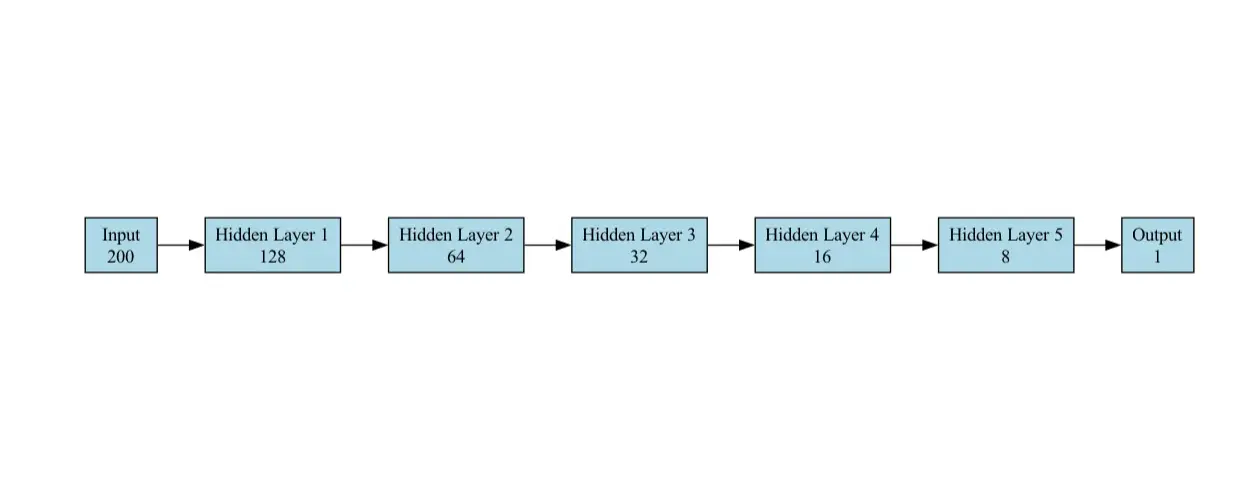
Das Modell für die Klassifizierungsaufgabe ist ein Feedforward Neural Network (FNN) für binäre Klassifizierung (Spam vs. nicht Spam). Es besteht aus den folgenden Schichten:
- Eingangsschicht : Akzeptiert einen Vektor von Größe 200 (Einbettungsmerkmale). Wir haben ein Beispiel für Pytorch geliefert, andere Frameworks folgen genau der gleichen Netzwerkkonfiguration
self.fc1 = fackel.nn.linear (200,128)
- Versteckte Schichten : Das Netzwerk verfügt über 5 versteckte Schichten, wobei jede aufeinanderfolgende Ebene weniger Einheiten als die vorherige enthält.
self.fc2 = fackel.nn.linear (128, 64) self.fc3 = fackel.nn.linear (64, 32) self.fc4 = fackel.nn.linear (32, 16) self.fc5 = fackel.nn.linear (16, 8) self.fc6 = fackel.nn.linear (8, 1)
- Ausgangsschichten : Ein einzelnes Neuron mit einer Sigmoidaktivierungsfunktion, um eine Wahrscheinlichkeit auszugeben (0 für nicht Spam, 1 für Spam). Wir haben die Sigmoidschicht als endgültige Ausgabe für die binäre Klassifizierung verwendet.
self.sigmoid = t Torch.nn.Sigmoid ())
Das Modell ist einfach und dennoch effektiv für die Klassifizierungsaufgabe.
Das für das Benchmarking in unserem Anwendungsfall verwendete Modellarchitekturdiagramm ist unten dargestellt:
Beispiele für zusätzliche Netzwerke für Benchmarking
- Bildklassifizierung: Modelle wie ResNet-50 (mittlere Komplexität) und Mobilenet (leichtes Gewicht) können der Benchmark-Suite für Aufgaben mit Bilderkennung hinzugefügt werden. RESNET-50 bietet ein Gleichgewicht zwischen rechnerischer Komplexität und Genauigkeit, während Mobilenet für Umgebungen mit niedriger Ressourcen optimiert ist.
- NLP -Aufgaben: Distilbert : Eine kleinere, schnellere Variante des Bert -Modells, die für Aufgaben des natürlichen Sprachverständnisses geeignet ist.
Modellformate
- Native Formate: Jedes Framework unterstützt seine nativen Modellformate wie .PT für Pytorch und .H5 für Tensorflow.
- Unified Format (ONNX) : Um die Kompatibilität für Frameworks zu gewährleisten, haben wir das Pytorch -Modell in das ONNX -Format (Modell.ONNX) exportiert. ONNX (Open Neural Network Exchange) fungiert als Brücke und ermöglicht es, Modelle in anderen Frameworks wie Pytorch, TensorFlow, Jax oder OpenVino ohne signifikante Modifikationen zu verwenden. Dies ist besonders nützlich für Multi-Framework-Tests und Bereitstellungsszenarien in der realen Welt, in denen die Interoperabilität von entscheidender Bedeutung ist.
- Diese Formate sind für ihre jeweiligen Frameworks optimiert, wodurch sie in diesen Ökosystemen einfach zu speichern, laden und bereitgestellt werden können.
Benchmarking Workflow
Dieser Workflow zielt darauf ab, die Inferenzleistung mehrerer Deep -Learning -Frameworks (Tensorflow, Pytorch, ONNX, JAX und OpenVino) mit der Klassifizierungsaufgabe zu vergleichen. Die Aufgabe umfasst die Verwendung von zufällig generierten Eingabedaten und das Benchmarking jedes Frameworks, um die durchschnittliche Zeit für eine Vorhersage zu messen.
- Python -Pakete importieren
- Deaktivieren
- Eingabedatenvorbereitung
- Modellimplementierungen für jeden Framework
- Benchmarking -Funktionsdefinition
- Modellinferenz und Benchmarking -Ausführung für jeden Framework
- Visualisierung und Export von Benchmarking -Ergebnissen
Importieren Sie notwendige Python -Pakete
Um mit Benchmarking Deep Learning -Modellen zu beginnen, müssen wir zunächst die essentiellen Python -Pakete importieren, die eine nahtlose Integration und Leistungsbewertung ermöglichen.
Importzeit OS importieren Numph als NP importieren Taschenlampe importieren Tensorflow als TF importieren Aus TensorFlow.keras Import -Eingabe onnxruntime als ORT importieren matplotlib.pyplot als pLT importieren vom PIL -Importbild psutil importieren Jax importieren Importieren Sie Jax.numpy als JNP vom OpenVino.Runtime Import Core CSV importieren
Deaktivieren
OS.Environ ["CUDA_VISIBLE_DEVICES"] = "-1" # GPU deaktivieren OS.Environ ["tf_cpp_min_log_level"] = "3" #Suppress TensorFlow -Protokoll
Eingabedatenvorbereitung
In diesem Schritt generieren wir zufällig Eingabedaten für die SPAM -Klassifizierung:
- Dimensionalität einer Stichprobe (200-zeitnionale Merkmale)
- Die Anzahl der Klassen (2: Spam oder nicht Spam)
Wir generieren Randome -Daten mithilfe von Numpy, um als Eingabefunktionen für die Modelle zu dienen.
#Generieren Dummy -Daten input_data = np.random.rand (1000, 200) .Astype (np.float32)
Modelldefinition
In diesem Schritt definieren wir die Netwrok -Architektur oder richten das Modell aus jedem Deep Learning -Framework (Tensorflow, Pytorch, ONNX, JAX und OpenVino) ein. Jedes Framework erfordert spezielle Methoden zum Laden von Modellen und zum Einrichten von Inferenz.
- Pytorch -Modell : In Pytorch definieren wir eine einfache Architektur für neuronale neuronale Netzwerke mit fünf vollständig verbundenen Schichten.
- TensorFlow -Modell: Das TensorFlow -Modell wird mit der Keras -API definiert und besteht aus einem einfachen neuronalen Feedforward -Netzwerk für die Klassifizierungsaufgabe.
- JAX-Modell: Das Modell wird mit Parametern initialisiert, und die Vorhersagefunktion wird mit der JAX-Zusammenstellung von JAX für eine effiziente Ausführung zusammengestellt.
- ONNX -Modell: Für ONNX exportieren wir ein Modell aus Pytorch. Nach dem Exportieren in das ONNX -Format laden wir das Modell mit der OnnxRuntime. InferenceSession API. Auf diese Weise können wir die Inferenz auf dem Modell über verschiedene Hardware -Spezifikationen hinweg ausführen.
- OpenVino -Modell : OpenVino wird zum Ausführen optimierter und bereitgestellter Modelle verwendet, insbesondere diejenigen, die mit anderen Frameworks trainiert sind (wie Pytorch oder TensorFlow). Wir laden das ONNX -Modell und kompilieren es mit OpenVinos Laufzeit.
Pytorch
Klasse Pytorchmodel (Torch.nn.Module):
def __init __ (selbst):
Super (Pytorchmodel, Selbst) .__ init __ ()
self.fc1 = fackel.nn.linear (200, 128)
self.fc2 = fackel.nn.linear (128, 64)
self.fc3 = fackel.nn.linear (64, 32)
self.fc4 = fackel.nn.linear (32, 16)
self.fc5 = fackel.nn.linear (16, 8)
self.fc6 = fackel.nn.linear (8, 1)
self.sigmoid = t Torch.nn.Sigmoid ())
Def Forward (Selbst, x):
x = fackel.relu (self.fc1 (x))
x = fackel.relu (self.fc2 (x))
x = fackel.relu (self.fc3 (x))
x = fackel.relu (self.fc4 (x))
x = fackel.relu (self.fc5 (x))
x = self.sigmoid (self.fc6 (x))
Rückkehr x
# Pytorch -Modell erstellen
pytorch_model = pytorchmodel ()Tensorflow
TensorFlow_Model = tf.keras.sequential ([[
Eingabe (Form = (200,)),
tf.keras.layers.dense (128, activation = 'relu'),
tf.keras.layers.dense (64, activation = 'relu'),
tf.keras.layers.dense (32, activation = 'relu'),
tf.keras.layers.dense (16, activation = 'relu'),
tf.keras.layers.dense (8, activation = 'relu'),
tf.keras.layers.dense (1, activation = 'sigmoid')
]))
TensorFlow_Model.comPile ())Jax
Def jax_model (x):
x = jax.nn.relu (jnp.dot (x, jnp.ones ((200, 128))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((128, 64))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((64, 32))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((32, 16))))
x = jax.nn.relu (jnp.dot (x, jnp.ones ((16, 8))))
x = jax.nn.sigmaid (jnp.dot (x, jnp.ones ((8, 1))))
Rückkehr xOnnx
# Konvertieren Sie das Pytorch -Modell in ONNX
Dummy_input = Torch.randn (1, 200)
onnx_model_path = "model.onnx"
fackler.onnx.export (
pytorch_model,
dummy_input,
onnx_model_path,
export_params = true,
Opset_version = 11,
input_names = ['Eingabe'],
output_names = ['output'],
Dynamic_axes = {'Eingabe': {0: 'batch_size'}, 'Ausgabe': {0: 'batch_size'}}
)
onnx_session = ort.inferenceSession (onnx_model_path)OpenVino
# OpenVino -Modelldefinition core = core () openvino_model = core.read_model (model = "model.onnx") compiled_model = core.compile_model (OpenVino_Model, Device_name = "CPU"))
Benchmarking -Funktion definiton
Diese Funktion führt Benchmarking -Tests in verschiedenen Frameworks durch, indem Sie drei Argumente vornehmen: Predict_function, input_data und num_runs. Standardmäßig wird es 1.000 Mal ausgeführt, kann jedoch gemäß den Anforderungen erhöht werden.
Def Benchmark_Model (Predict_function, input_data, num_runs = 1000):
start_time = time.time ()
process = psutil.process (os.getPid ())
cpu_usage = []
memory_usage = []
für _ in Bereich (num_runs):
predict_function (input_data)
cpu_usage.append (process.cpu_percent ())
memory_usage.append (process.memory_info (). RSS)
end_time = time.time ()
AVG_LATENCY = (end_time - start_time) / num_runs
avg_cpu = np.mean (cpu_usage)
AVG_MEMORY = NP.MEAN (MEMALY_USAGE) / (1024 * 1024) # in MB konvertieren
RECHTEN SIE AVG_LATENCY, AVG_CPU, AVG_MEMORYModellinferenz und Durchführen von Benchmarking für jeden Framework
Nachdem wir die Modelle geladen haben, ist es an der Zeit, die Leistung jedes Frameworks zu bewerten. Der Benchmarking -Prozess führt zu Inferenz in den generierten Eingabedaten.
Pytorch
# Benchmark Pytorch -Modell
Def Pytorch_Predict (input_data):
pytorch_model (fackel.tensor (input_data))
pytorch_latency, pytorch_cpu, pytorch_memory = benchmark_model (lambda x: pytorch_prredict (x), input_data)Tensorflow
# Benchmark TensorFlow -Modell
Def TensorFlow_Predict (input_data):
TensorFlow_Model (input_data)
TensorFlow_Latency, TensorFlow_CPU, TensorFlow_Memory = Benchmark_Model (Lambda X: TensorFlow_Predict (x), input_data)Jax
# Benchmark JAX -Modell
Def Jax_Predict (input_data):
jax_model (jnp.Array (input_data))
jax_latency, jax_cpu, jax_memory = benchmark_model (lambda x: jax_prredict (x), input_data)Onnx
# Benchmark Onnx -Modell
Def Onnx_Predict (input_data):
# Prozesseingaben in Chargen
für i im Bereich (input_data.shape [0]):
Single_input = input_data [i: i 1] # einzelne Eingabe extrahieren
onnx_session.run (none, {onnx_Session.get_inputs () [0] .Name: Single_input})
onnx_latency, onnx_cpu, onnx_memory = benchmark_model (lambda x: onnx_prredict (x), input_data)OpenVino
# Benchmark OpenVino -Modell
Def OpenVino_Predict (input_data):
# Prozesseingaben in Chargen
für i im Bereich (input_data.shape [0]):
Single_input = input_data [i: i 1] # einzelne Eingabe extrahieren
compiled_model.infer_new_request ({0: Single_input})
OpenVino_Latency, OpenVino_CPU, OpenVino_Memory = Benchmark_Model (Lambda X: OpenVino_Predict (x), input_data)
Ergebnisse und Diskussion
Hier diskutieren wir die Ergebnisse des Leistungsbenchmarkings zuvor erwähnter Deep Learning -Frameworks. Wir vergleichen sie auf - Latenz, CPU -Nutzung und Speicherverbrauch. Wir haben tabellarische Daten und Diagramme zum schnellen Vergleich aufgenommen.
Latenzvergleich
| Rahmen | Latenz (MS) | Relative Latenz (gegen Pytorch) |
| Pytorch | 1.26 | 1.0 (Grundlinie) |
| Tensorflow | 6.61 | ~ 5,25 × |
| Jax | 3.15 | ~ 2,50 × |
| Onnx | 14.75 | ~ 11,72 × |
| OpenVino | 144.84 | ~ 115 × |
Einsichten:
- Pytorch leitet das schnellste Rahmen mit einer Latenz von ~ 1,26 ms .
- TensorFlow hat eine Latenz von ~ 6,61 ms , etwa 5,25 × Pytorch -Zeit.
- Jax sitzt in absoluter Latenz zwischen Pytorch und Tensorflow.
- Onnx ist ebenfalls relativ langsam, bei ~ 14,75 ms .
- OpenVino ist das langsamste in diesem Experiment bei ~ 145 ms (115 × langsamer als Pytorch).
CPU -Verwendung
| Rahmen | CPU -Nutzung (%) | Relative CPU -Verwendung 1 |
| Pytorch | 99.79 | ~ 1,00 |
| Tensorflow | 112.26 | ~ 1.13 |
| Jax | 130.03 | ~ 1,31 |
| Onnx | 99,58 | ~ 1,00 |
| OpenVino | 99.32 | 1.00 (Grundlinie) |
Einsichten:
- Jax verwendet die meisten CPU ( ~ 130 % ), ~ 31 % höher als OpenVino.
- TensorFlow liegt bei ~ 112 % , mehr als Pytorch/ONNX/OpenVino, aber immer noch niedriger als Jax.
- Pytorch, Onnx und OpenVino haben alle ähnliche, ~ 99-100% CPU-Nutzung.
Speicherverbrauch
| Rahmen | Speicher (MB) | Relative Speicherverwendung (gegen Pytorch) |
| Pytorch | ~ 959.69 | 1.0 (Grundlinie) |
| Tensorflow | ~ 969.72 | ~ 1,01 × |
| Jax | ~ 1033.63 | ~ 1,08 × |
| Onnx | ~ 1033.82 | ~ 1,08 × |
| OpenVino | ~ 1040.80 | ~ 1,08–1,09 × |
Einsichten:
- Pytorch und TensorFlow haben einen ähnlichen Speicherverbrauch um ~ 960-970 MB
- JAX, ONNX und OpenVino verwenden ungefähr ~ 1.030–1.040 MB Speicher, ungefähr 8–9% mehr als Pytorch.
Hier ist die Handlung, in der die Leistung von Deep -Learning -Frameworks verglichen wird:

Abschluss
In diesem Artikel haben wir einen umfassenden Benchmarking -Workflow vorgestellt, um die Inferenzleistung von prominenten Deep -Learning -Frameworks - Tensorflow, Pytorch, Onnx, Jax und OpenVino - als Referenz zu einer Spam -Klassifizierungsaufgabe zu bewerten. Durch die Analyse von Schlüsselmetriken wie Latenz, CPU-Nutzung und Speicherverbrauch haben die Ergebnisse die Kompromisse zwischen Frameworks und ihrer Eignung für verschiedene Bereitstellungsszenarien hervorgehoben.
Pytorch zeigte die ausgewogenste Leistung, zeichnen sich bei geringer Latenz und effizienter Speicherverwendung und machte sie ideal für latenzempfindliche Anwendungen wie Echtzeitvorhersagen und Empfehlungssysteme. TensorFlow bot eine mittlere Lösung mit mäßig höherem Ressourcenverbrauch. JAX zeigte einen hohen Rechendurchsatz, aber auf Kosten einer verstärkten CPU-Nutzung, die ein begrenzender Faktor für ressourcenbezogene Umgebungen darstellt. In der Zwischenzeit blieb Onnx und OpenVino in der Latenz zurück, wobei OpenVinos Leistung besonders durch das Fehlen einer Hardwarebeschleunigung behindert wurde.
Diese Ergebnisse unterstreichen die Bedeutung der Auswahl der Framework mit den Bereitstellungsbedürfnissen. Unabhängig davon, ob die Optimierung von Geschwindigkeit, Ressourceneffizienz oder spezifischer Hardware das Verständnis der Kompromisse für die effektive Modellbereitstellung in realen Umgebungen ist.
Key Takeaways
- Deep Learning CPU -Benchmarks bieten kritische Einblicke in die CPU -Leistung und helfen bei der Auswahl optimaler Hardware für KI -Aufgaben.
- Durch die Nutzung von CPU-Benchmarks von Deep Learning sorgt ein effizientes Modelltraining und die Inferenz durch Identifizierung leistungsstarker CPUs.
- Erreichte die beste Latenz (1,26 ms) und behielten eine effiziente Speicherverwendung bei, ideal für Echtzeit- und Ressourcenbegrenzungsanwendungen.
- Ausgewogene Latenz (6,61 ms) mit etwas höherer CPU -Verwendung, geeignet für Aufgaben, die eine mäßige Leistungskompromisse erfordern.
- Lieferte die Wettbewerbslatenz (3,15 ms), jedoch auf Kosten einer übermäßigen CPU -Nutzung ( 130% ), wodurch der Nutzen in eingeschränkten Setups eingeschränkt wurde.
- Zeigten eine höhere Latenz (14,75 ms), aber seine plattformübergreifende Unterstützung macht es für Multi-Ramework-Bereitstellungen flexibel.
Häufig gestellte Fragen
Q1. Warum wird Pytorch für Echtzeitanwendungen bevorzugt?A. Pytorchs dynamischer Berechnungsgrafik und effiziente Ausführungspipeline ermöglichen eine schlechte Inferenz (1,26 ms), was sie für Anwendungen wie Empfehlungssysteme und Echtzeitvorhersagen gut geeignet ist.
Q2. Was hat OpenVinos Leistung in dieser Studie beeinflusst?A. OpenVinos Optimierungen sind für Intel -Hardware ausgelegt. Ohne diese Beschleunigung waren seine Latenz (144,84 ms) und die Speicherverwendung (1040,8 MB) im Vergleich zu anderen Rahmenbedingungen weniger wettbewerbsfähig.
Q3. Wie wähle ich einen Rahmen für ressourcenbezogene Umgebungen aus?A. Für CPU-Setups ist Pytorch am effizientesten. TensorFlow ist eine starke Alternative für moderate Workloads. Vermeiden Sie Frameworks wie JAX, es sei denn, eine höhere CPU -Nutzung ist akzeptabel.
Q4. Welche Rolle spielt Hardware in der Framework -Leistung?A. Die Rahmenleistung hängt stark von der Hardwarekompatibilität ab. Zum Beispiel zeichnet sich OpenVino auf Intel-CPUs mit hardwarespezifischen Optimierungen aus, während Pytorch und Tensorflow konsistent über unterschiedliche Setups abschneiden.
Q5. Können sich die Ergebnisse der Benchmarking mit komplexen Modellen oder Aufgaben unterscheiden?A. Ja, diese Ergebnisse spiegeln eine einfache Binärklassifizierungsaufgabe wider. Die Leistung kann mit komplexen Architekturen wie Resnet oder Aufgaben wie NLP oder anderen variieren, bei denen diese Frameworks möglicherweise spezielle Optimierungen nutzen.
Die in diesem Artikel gezeigten Medien sind nicht im Besitz von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Das obige ist der detaillierte Inhalt vonDeep Learning CPU -Benchmarks. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Die Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Februar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Yolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
 Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Der Artikel überprüft Top -KI -Kunstgeneratoren, diskutiert ihre Funktionen, Eignung für kreative Projekte und Wert. Es zeigt MidJourney als den besten Wert für Fachkräfte und empfiehlt Dall-E 2 für hochwertige, anpassbare Kunst.
 Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 ist derzeit verfügbar und weit verbreitet, wodurch im Vergleich zu seinen Vorgängern wie ChatGPT 3.5 signifikante Verbesserungen beim Verständnis des Kontextes und des Generierens kohärenter Antworten zeigt. Zukünftige Entwicklungen können mehr personalisierte Inters umfassen
 Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Der Artikel erörtert KI -Modelle, die Chatgpt wie Lamda, Lama und Grok übertreffen und ihre Vorteile in Bezug auf Genauigkeit, Verständnis und Branchenauswirkungen hervorheben. (159 Charaktere)
 So verwenden Sie Mistral OCR für Ihr nächstes Lappenmodell
Mar 21, 2025 am 11:11 AM
So verwenden Sie Mistral OCR für Ihr nächstes Lappenmodell
Mar 21, 2025 am 11:11 AM
Mistral OCR: revolutionäre retrieval-ausgereifte Generation mit multimodalem Dokumentverständnis RAG-Systeme (Abrufen-Augment-Augmented Generation) haben erheblich fortschrittliche KI
 Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
In dem Artikel werden Top -KI -Schreibassistenten wie Grammarly, Jasper, Copy.ai, Writesonic und RYTR erläutert und sich auf ihre einzigartigen Funktionen für die Erstellung von Inhalten konzentrieren. Es wird argumentiert, dass Jasper in der SEO -Optimierung auszeichnet, während KI -Tools dazu beitragen, den Ton zu erhalten
