

Die Szenetexterkennung (STR) ist aufgrund der Vielzahl von Textauftritten in realen Einstellungen eine bedeutende Herausforderung für Forscher. Das Erkennen von Text in einem Dokument unterscheidet sich beispielsweise von der Identifizierung von Text in einem T-Shirt. Das MGP-STR-Modell (Multi-Granularity-Vorhersage für die Szene Texterkennung), das bei ECCV 2022 eingeführt wurde, bietet einen bahnbrechenden Ansatz. MGP-STR kombiniert die Robustheit von Visionstransformatoren (VIT) mit innovativen Sprachvorhersagen mit mehreren Granularität und verbessert die Fähigkeit, komplexe STR-Aufgaben zu bewältigen. Dies führt zu einer höheren Genauigkeit und einer besseren Benutzerfreundlichkeit in verschiedenen, herausfordernden realen Szenarien und bietet eine einfache, aber leistungsstarke Lösung.
*Dieser Artikel ist Teil des *** Data Science Blogathon.
MGP-STR ist ein sehbasiertes STR-Modell, ohne ein separates Sprachmodell zu benötigen. Es integriert sprachliche Informationen direkt in seine Architektur mit der MGP-Strategie (Multi-Granularity Prediction). Dieser implizite Ansatz ermöglicht es MGP-STR, sowohl rein visuelle Modelle als auch sprachverhinderte Methoden zu übertreffen, wodurch hochmoderne STR-Ergebnisse erzielt werden.
Die Architektur besteht aus zwei Schlüsselkomponenten:
Die Verschmelzung von Vorhersagen in Charakter-, Subword- und Wortniveaus durch eine einfache, aber effektive Strategie sorgt dafür, dass MGP-STR sowohl visuelle als auch sprachliche Details erfasst.
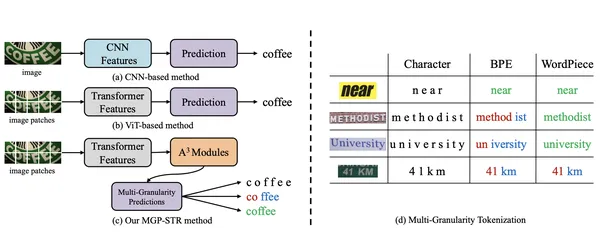
MGP-STR dient hauptsächlich für OCR-Aufgaben auf Textbildern. Seine einzigartige Fähigkeit, sprachliches Wissen implizit einzubeziehen, macht es in realen Szenarien mit abwechslungsreichem und verzerrten Text besonders nützlich. Beispiele sind:
In diesem Abschnitt wird angezeigt, wie MGP-STR für die Erkennung von Szenetext auf einem Beispielbild verwendet wird. Sie benötigen Pytorch, die Transformers Library und Abhängigkeiten (PIL, Anfragen).
Importieren Sie die erforderlichen Bibliotheken: Transformatoren für die Modellhandhabung, PIL für Bildmanipulation und Anfragen zum Abrufen von Online -Bildern.
<code>from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition import requests import base64 from io import BytesIO from PIL import Image from IPython.display import display, Image as IPImage</code>
Laden Sie das MGP-STR-Basismodell und seinen Prozessor von der Umarmung von Gesichtstransformatoren.
<code>processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base') model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')</code>Erstellen Sie eine Funktion, um Bild-URLs einzugeben, sie mit MGP-STR zu verarbeiten und Textvorhersagen zurückzugeben. Dies behandelt Bildumwandlung, Basis64 -Codierung und Textdecodierung.
<code>def predict(url): image = Image.open(requests.get(url, stream=True).raw).convert("RGB") pixel_values = processor(images=image, return_tensors="pt").pixel_values outputs = model(pixel_values) generated_text = processor.batch_decode(outputs.logits)['generated_text'] buffered = BytesIO() image.save(buffered, format="PNG") image_base64 = base64.b64encode(buffered.getvalue()).decode("utf-8") display(IPImage(data=base64.b64decode(image_base64))) print("\n\n") return generated_text</code> Die Beispiele mit Bild -URLs und Vorhersagen werden hier weggelassen, um Platz zu sparen. Sie verfolgen jedoch dieselbe Struktur wie im Originaltext und rufen die predict mit unterschiedlichen Bild -URLs auf.
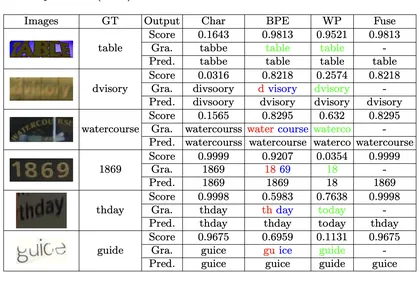
Die Genauigkeit des Modells zeigt sich aus den Bildbeispielen. Seine Effizienz ist bemerkenswert und läuft auf einer CPU mit geringem RAM -Gebrauch. Dies macht es leicht für die Feinabstimmung von domänenspezifischen Aufgaben anpassen.

MGP-STR kombiniert effektiv Seh- und Sprachverständnis. Seine innovativen Vorhersagen mit mehreren Granularität bieten einen umfassenden Ansatz für STR und verbessern die Genauigkeit und Anpassungsfähigkeit ohne externe Sprachmodelle. Die einfache, aber genaue Architektur macht es zu einem wertvollen Instrument für Forscher und Entwickler in OCR und STR. Seine Open-Source-Natur fördert weitere Fortschritte im Bereich.
F1: Was ist MGP-STR und wie unterscheidet es sich von herkömmlichen STR-Modellen? A1: MGP-STR integriert sprachliche Vorhersagen direkt in sein sehbasiertes Framework unter Verwendung von MGP und beseitigt die Notwendigkeit separater Sprachmodelle, die in herkömmlichen Methoden zu finden sind.
F2: Mit welchen Datensätzen wurden MGP-STR geschult? A2: Das Basismodell wurde auf MJSynth und SynthText trainiert.
F3: Kann MGP-STR-Griff verzerrte oder minderwertige Textbilder? A3: Ja, sein Multi-Granularity-Vorhersagemechanismus ermöglicht es ihm, solche Herausforderungen zu bewältigen.
F4: Ist MGP-STR für andere Sprachen als Englisch geeignet? A4: Obwohl es für Englisch optimiert ist, kann es mit geeigneten Trainingsdaten an andere Sprachen angepasst werden.
F5: Wie trägt das A³-Modul zur Leistung von MGP-STR bei? A5: Das A³-Modul verfeinert VIT-Ausgänge, ermöglicht Vorhersagen auf Unterwortebene und eingebettet sprachliche Informationen.
HINWEIS: Die Bildplatzhalter bleiben die gleichen wie in der ursprünglichen Eingabe. Denken Sie daran, die klammernden Links durch tatsächliche Links zu ersetzen.
Das obige ist der detaillierte Inhalt vonSzenetexterkennung unter Verwendung der Vision-basierten Texterkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



