

Die Mischung von Experten (MOE) -Modellen revolutionieren große Sprachmodelle (LLMs), indem sie die Effizienz und Skalierbarkeit verbessern. Diese innovative Architektur unterteilt das Modell in spezielle Unter-Networks oder "Experten", die jeweils für bestimmte Datentypen oder Aufgaben geschult sind. Durch die Aktivierung einer relevanten Untergruppe von Experten basierend auf der Eingabe steigern MOE -Modelle die Kapazität erheblich, ohne die Rechenkosten proportional zu erhöhen. Diese selektive Aktivierung optimiert die Verwendung von Ressourcen und ermöglicht es, komplexe Aufgaben in verschiedenen Bereichen wie Verarbeitung natürlicher Sprache, Computer Vision und Empfehlungssysteme zu ermöglichen. In diesem Artikel werden MOE -Modelle, ihre Funktionalität, beliebte Beispiele und Python -Implementierung untersucht.
Dieser Artikel ist Teil des Datenwissenschaftsblogathons.
Inhaltsverzeichnis:
Was sind die Mischung von Experten (MOEs)?
MOE -Modelle verbessern das maschinelles Lernen, indem sie mehrere kleinere, spezialisierte Modelle anstelle eines einzigen großen verwenden. Jedes kleinere Modell zeichnet sich bei einem bestimmten Problemtyp aus. Ein "Entscheidungsträger" (Gating-Mechanismus) wählt das geeignete Modell für jede Aufgabe aus und verbessert die Gesamtleistung. Moderne Deep -Learning -Modelle, einschließlich Transformatoren, verwenden geschichtete miteinander verbundene Einheiten ("Neuronen"), die Daten verarbeiten und Ergebnisse an nachfolgende Schichten übergeben. MOE spiegelt dies wider, indem komplexe Probleme in spezialisierte Komponenten ("Experten") aufgeteilt werden, die jeweils einen bestimmten Aspekt angehen.
Wichtige Vorteile von MOE -Modellen:
Ein MOE -Modell umfasst zwei Hauptteile: Experten (spezialisierte kleinere neuronale Netzwerke) und einen Router (der relevante Experten basierend auf der Input aktiviert). Diese selektive Aktivierung steigert die Effizienz.
Moes im tiefen Lernen
In Deep Learning verbessert MOE die Leistung des neuronalen Netzwerks, indem sie komplexe Probleme abbaut. Anstelle eines einzelnen großen Modells verwendet es mehrere kleinere "Experten" -Modelle, die sich auf verschiedene Eingabedatenaspekte spezialisiert haben. Ein Gating -Netzwerk bestimmt, welche Experten für jede Eingabe verwendet werden sollen und die Effizienz und Effektivität verbessert.
Wie funktionieren MOE -Modelle?
MOE -Modelle arbeiten wie folgt:
Prominente MOE-basierte Modelle
MOE -Modelle werden in der KI aufgrund ihrer effizienten Skalierung von LLMs bei der Aufrechterhaltung der Leistung immer wichtiger. Mixtral 8x7b, ein bemerkenswertes Beispiel, verwendet eine spärliche MOE -Architektur, die nur eine Untergruppe von Experten für jeden Input aktiviert, was zu erheblichen Effizienzgewinnen führt.
Mixtral 8x7b ist nur Decoder-Transformator. Eingangs -Token werden in Vektoren eingebettet und über Decoderschichten verarbeitet. Die Ausgabe ist die Wahrscheinlichkeit, dass jeder Ort von einem Wort besetzt wird, wodurch der Text und die Vorhersage ermöglicht wird. Jede Decoder -Schicht verfügt über einen Aufmerksamkeitsmechanismus (für Kontextinformationen) und eine spärliche Mischung aus Experten (Smoe) (Smoe) (individuell jeden Wortvektor). Smoe Layers verwenden mehrere Ebenen ("Experten"), und für jeden Eingang wird eine gewichtete Summe der relevanten Expertenausgaben entnommen.
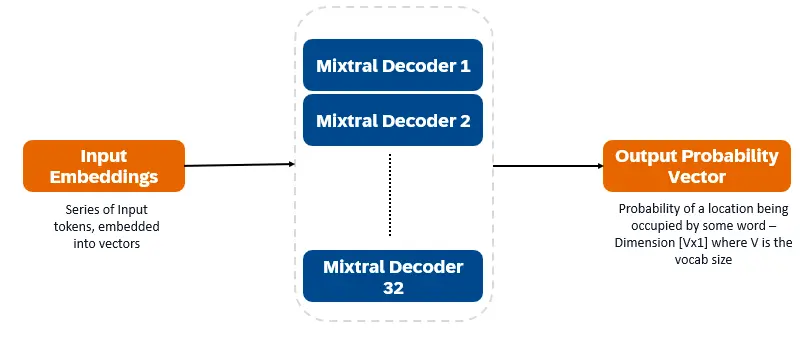
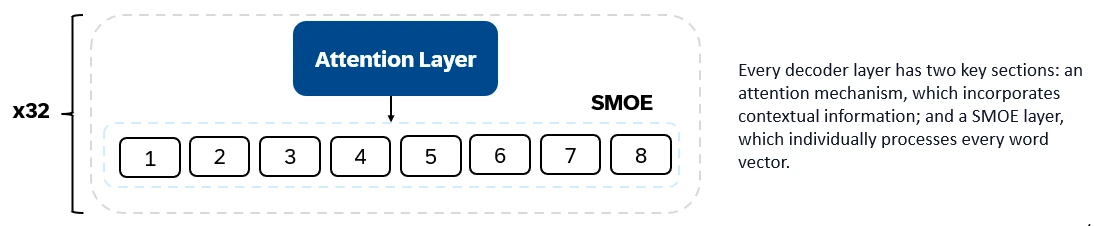
Schlüsselmerkmale von Mixtral 8x7b:
Mixtral 8x7b zeichnet sich in Textgenerierung, Verständnis, Übersetzung, Zusammenfassung und mehr aus.
DBRX (Databricks) ist ein transformatorbasiertes Decoder-LLM, das mit der nächstgefeilten Vorhersage trainiert wird. Es verwendet eine feinkörnige MOE-Architektur (132B Gesamtparameter, 36B aktiv). Es wurde auf 12-t-Token von Text- und Codedaten vorgebracht. DBRX ist feinkörnig und verwendet viele kleinere Experten (16 Experten, 4 pro Input ausgewählt).
Wichtige architektonische Merkmale von DBRX:
Schlüsselmerkmale von DBRX:
DBRX zeichnet sich in Codegenerierung, komplexes Sprachverständnis und mathematisches Denken aus.
Deepseek-V2 verwendet feinkörnige Experten und gemeinsame Experten (immer aktiv), um universelles Wissen zu integrieren.
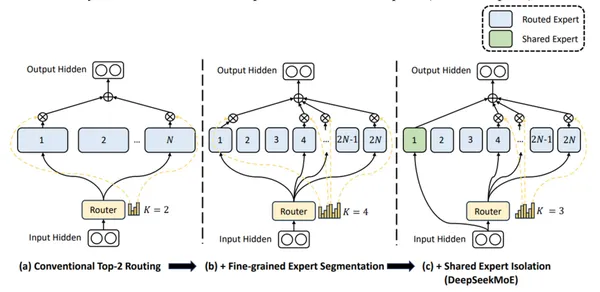
Schlüsselmerkmale von Deepseek-V2:
Deepseek-V2 ist geschickt in Gesprächen, Erstellung von Inhalten und Codegenerierung.
(Python -Implementierungs- und Ausgangsvergleichsabschnitte, die für die Kürze entfernt wurden, da es sich um lange Codebeispiele und detaillierte Analysen handelt.)
Häufig gestellte Fragen
Q1. Welche Mischung aus Experten (MOE) Modellen (MOE)? A. MOE -Modelle verwenden eine spärliche Architektur, die nur die relevantesten Experten für jede Aufgabe aktiviert, was zu einer verringerten Verwendung von Rechenressourcen führt.
Q2. Was ist der Kompromiss mit MOE-Modellen? A. MOE -Modelle erfordern ein erhebliches VRAM, um alle Experten im Gedächtnis zu speichern und Rechenleistung und Speicheranforderungen auszugleichen.
Q3. Was ist die aktive Parameterzahl für Mixtral 8x7b? A. Mixtral 8x7b hat 12,8 Milliarden aktiven Parameter.
Q4. Wie unterscheidet sich DBRX von anderen MOE -Modellen? A. DBRX verwendet einen feinkörnigen MOE-Ansatz mit kleineren Experten.
Q5. Was unterscheidet Deepseek-V2? A. Deepseek-V2 kombiniert feinkörnige und gemeinsame Experten sowie eine große Parameter-Set und eine lange Kontextlänge.
Abschluss
MOE -Modelle bieten einen hocheffizienten Ansatz für tiefes Lernen. Ihre selektive Aktivierung von Experten erfordert zwar ein erhebliches VRAM, macht sie leistungsstarke Werkzeuge zum Umgang mit komplexen Aufgaben über verschiedene Bereiche hinweg. Mixtral 8x7b, DBRX und Deekseek-V2 stellen signifikante Fortschritte in diesem Bereich mit jeweils eigene Stärken und Anwendungen dar.
Das obige ist der detaillierte Inhalt vonWas ist die Mischung von Experten?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



