

Die Handhabung fehlender Daten ist ein entscheidender Schritt in der Datenanalyse und in der maschinellen Lernen. Fehlende Werte, die sich aus verschiedenen Quellen wie Dateneingabefehlern oder inhärenten Datenbeschränkungen stammen, können die Genauigkeit und die Modellzuverlässigkeit stark beeinflussen. Pandas, eine leistungsstarke Python -Bibliothek, bietet die fillna() -Methode - ein vielseitiges Tool für eine effektive fehlende Datenreputation. Diese Methode ermöglicht das Ersetzen fehlender Werte durch verschiedene Strategien und gewährleistet die Vollständigkeit der Daten für die Analyse.

Inhaltsverzeichnis
fillna()fillna() syntaxfillna()Was ist Daten Imputation?
Die Datenimputation ist die Technik, um fehlende Datenpunkte in einem Datensatz auszufüllen. Fehlende Daten stellen erhebliche Herausforderungen für viele analytische Methoden und Algorithmen für maschinelles Lernen dar, die vollständige Datensätze erfordern. Die Imputation befasst sich mit der Schätzung und Ersetzung fehlender Werte durch plausible Ersatzstoffe auf der Grundlage der verfügbaren Daten.
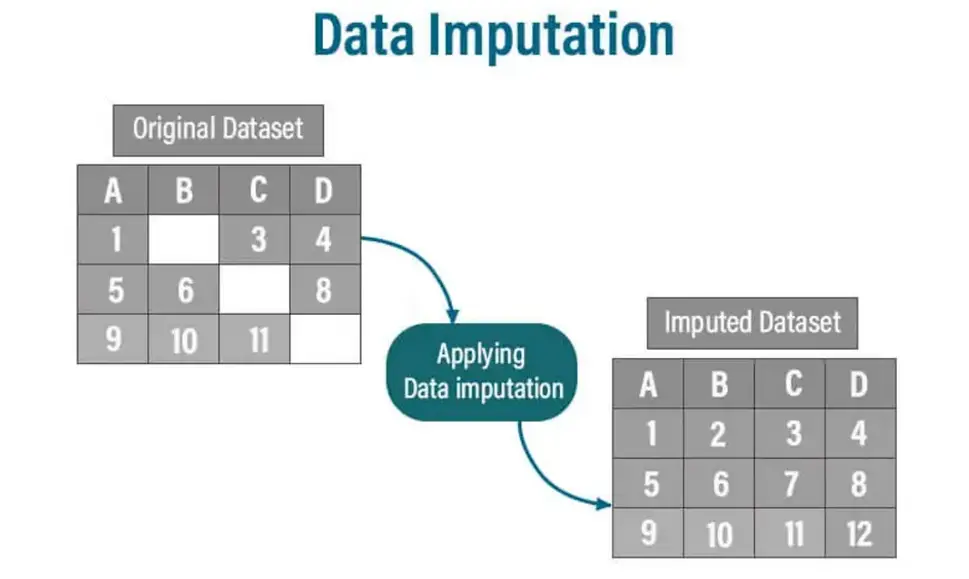
Warum ist Datenpatatur wichtig?
In mehreren wichtigen Gründen wird die Bedeutung der Datenimputation hervorgehoben:
Pandas fillna()
Die Pandas fillna() -Methode ist so konzipiert, dass sie NaN -Werte (nicht eine Zahl) in Datenrahmen oder Serien ersetzen. Es bietet verschiedene Imputationsstrategien.
fillna() syntax

Zu den wichtigsten Parametern gehören value (der Ersatzwert), method (z. B. "FFILL" für die Vorwärtsfüllung, "BFILL" für Rückwärtsfüllung), axis , inplace , limit und downcast .
Verwenden von fillna() für verschiedene Imputationstechniken
Mehrere Imputationstechniken können mit fillna() implementiert werden:
(Code -Beispiele für jede Technik würden hier enthalten, die die Struktur und den Inhalt der Codebeispiele des Originaltextes widerspiegeln.)
Abschluss
Eine effektive fehlende Datenbehandlung ist für eine zuverlässige Datenanalyse und maschinelles Lernen von entscheidender Bedeutung. Die Pandas ' fillna() -Methode bietet eine leistungsstarke und flexible Lösung und bietet eine Reihe von Imputationsstrategien, um unterschiedliche Datentypen und Kontexte zu entsprechen. Die Auswahl der richtigen Methode hängt von den Eigenschaften des Datensatzes und den Analysezielen ab.
Häufig gestellte Fragen
(Der FAQS -Abschnitt würde beibehalten, der den Inhalt des Originaltextes widerspiegelt.)
Das obige ist der detaillierte Inhalt vonPandas fillna () für die Datenreputation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So erstellen Sie einen neuen Ordner in Webstorm
So erstellen Sie einen neuen Ordner in Webstorm
 So lösen Sie das Problem, dass document.cookie nicht abgerufen werden kann
So lösen Sie das Problem, dass document.cookie nicht abgerufen werden kann
 So lesen Sie den Wagenrücklauf in Java
So lesen Sie den Wagenrücklauf in Java
 CAD-Zeilenbruchbefehl
CAD-Zeilenbruchbefehl
 Einführung in Schnittstellentypen
Einführung in Schnittstellentypen
 Ist Yiouoky eine legale Software?
Ist Yiouoky eine legale Software?
 Was sind die SEO-Keyword-Ranking-Tools?
Was sind die SEO-Keyword-Ranking-Tools?
 Was tun, wenn der Computer den Tod vortäuscht?
Was tun, wenn der Computer den Tod vortäuscht?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



