

In der heutigen datengesteuerten Welt ist eine effiziente Datenanalyse für fundierte Entscheidungen von größter Bedeutung. Python ist mit seiner benutzerfreundlichen Syntax und umfangreichen Bibliotheken zur Anlaufzeit für Datenwissenschaftler und Analysten geworden. In diesem Artikel werden zehn essentielle Python -Bibliotheken für die Datenanalyse hervorgehoben, die sowohl für Anfänger als auch für erfahrene Benutzer gerecht werden.
Numpy bildet das Grundgestein der numerischen Computerfunktionen von Python. Es zeichnet sich aus der Umstellung großer, mehrdimensionaler Arrays und Matrizen aus und bietet eine umfassende Suite mathematischer Funktionen für eine effiziente Array-Manipulation.
Stärken:
Einschränkungen:
Numph als NP importieren
Data = NP.Array ([1, 2, 3, 4, 5])
print ("Array:", Daten)
print ("Mean:", np.mean (Daten))
print ("Standardabweichung:", np.std (Daten))Ausgabe

Pandas vereinfacht die Datenmanipulation mit seiner DataFrame -Struktur, ideal für die Arbeit mit tabellarischen Daten. Die Reinigung, Transformation und Analyse strukturierter Datensätze wird bei Pandas erheblich einfacher.
Stärken:
Einschränkungen:
Pandas als PD importieren
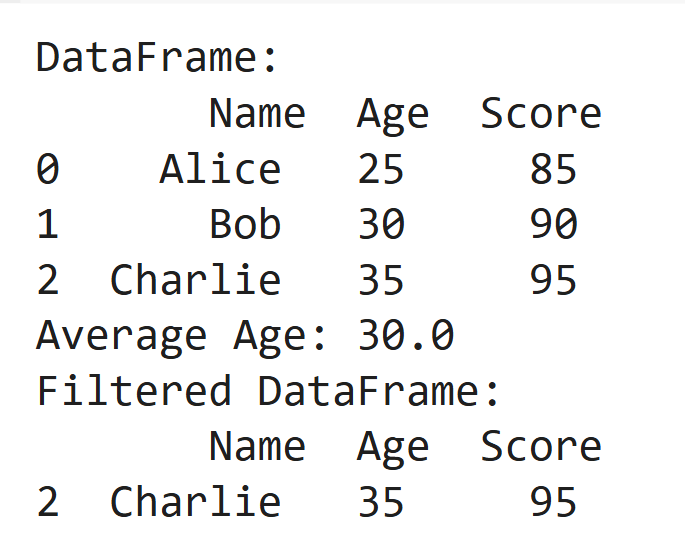
Data = Pd.Dataframe ({'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35], 'Score': [85, 90, 95]})
print ("DataFrame: \ n", Daten)
print ("Durchschnittsalter:", Daten ['Alter']. Mean ())
print ("gefilterte Datenframe: \ n", Daten [Daten ['Score']> 90])Ausgabe
Matplotlib ist eine vielseitige Ploting -Bibliothek, die die Erstellung einer breiten Palette von statischen, interaktiven und sogar animierten Visualisierungen ermöglicht.
Stärken:
Einschränkungen:
matplotlib.pyplot als pLT importieren
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
PLT.PLOT (x, y, label = "Zeilendiagramm")
pt.xlabel ('x-axis')
Plt.ylabel ('y-Achse')
Plt.title ('Matplotlib -Beispiel')
Plt.Legend ()
Plt.Show ()Ausgabe

Seeborn baut auf Matplotlib auf und vereinfacht die Schaffung statistisch informativer und visuell ansprechender Diagramme.
Stärken:
Einschränkungen:
Importieren Sie Seeborn als SNS
matplotlib.pyplot als pLT importieren
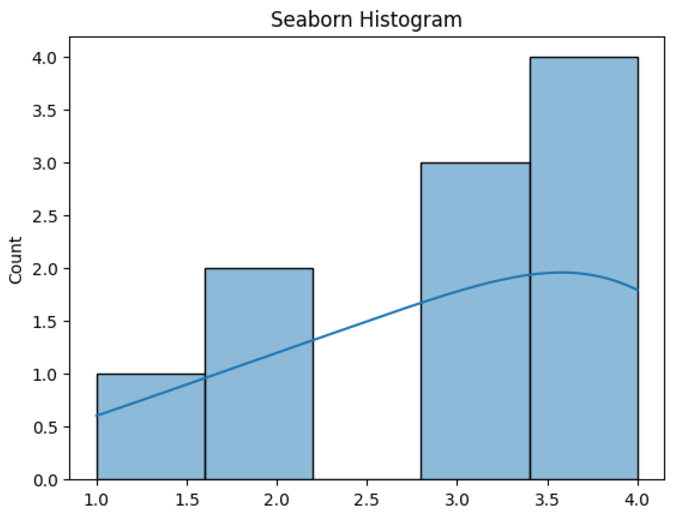
Daten = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
sns.histplot (Daten, kde = true)
PLT.TITLE ('SEABORN HISTOGRAM')
Plt.Show ()Ausgabe
Scipy erweitert Numpy und bietet erweiterte Tools für das wissenschaftliche Computer, einschließlich Optimierung, Integration und Signalverarbeitung.
Stärken:
Einschränkungen:
von scipy.stats import test_ind
Gruppe1 = [1, 2, 3, 4, 5]
Gruppe2 = [2, 3, 4, 5, 6]
t_stat, p_value = ttest_ind (Gruppe1, Gruppe2)
print ("t-statistic:", t_stat)
print ("p-Wert:", p_Value)Ausgabe

Scikit-Learn ist eine leistungsstarke Bibliothek für maschinelles Lernen, die Tools zur Klassifizierung, Regression, Clusterbildung und Dimensionalitätsreduzierung bereitstellt.
Stärken:
Einschränkungen:
Aus sklearn.linear_model importieren Sie linearRegression
X = [[1], [2], [3], [4]]
y = [2, 4, 6, 8]
Modell = linearRegression ()
model.fit (x, y)
print ("Vorhersage für x = 5:", Modell.Predict ([5]]) [0])Ausgabe
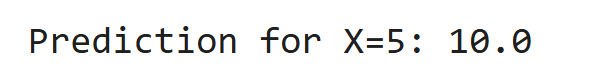
StatsModels konzentriert sich auf statistische Modellierungs- und Hypothesentests, insbesondere auf Ökonometrie und statistische Forschung.
Stärken:
Einschränkungen:
statsmodels.api als SM importieren X = [1, 2, 3, 4] y = [2, 4, 6, 8] X = sm.add_constant (x) Modell = sm.ols (y, x) .fit () print (model.summary ())
Ausgabe

Plotly erstellt interaktive und webrede Visualisierungen, perfekt für Dashboards und Webanwendungen.
Stärken:
Einschränkungen:
plotly.express als px importieren Data = px.data.iris () Abb. Abb.Show ()
Ausgabe

PYSPARK bietet eine Python-Schnittstelle zu Apache Spark und aktiviert verteilte Computing für die Datenverarbeitung in großem Maßstab.
Stärken:
Einschränkungen:
! PIP Installieren Sie PYSPARK
von pyspark.sql import sparkaSession
Spark = SparkSession.builder.Appname ("pyspark Beispiel"). GetorCreate ()
Data = Spark.Createdataframe ([(1, "Alice"), (2, "Bob")], ["ID", "Name"])
Data.show ()Ausgabe

Altair ist eine deklarative Visualisierungsbibliothek, die auf Vega und Vega-Lite basiert und eine kurze Syntax für die Erstellung von anspruchsvollen Diagrammen bietet.
Stärken:
Einschränkungen:
Altair als Alt importieren
Pandas als PD importieren
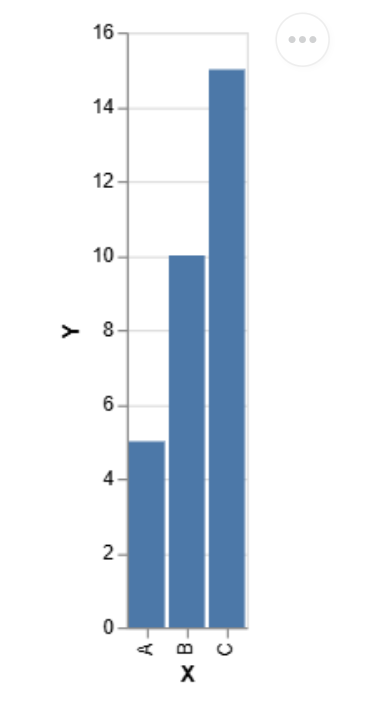
Data = pd.dataframe ({'x': ['a', 'b', 'c'], 'y': [5, 10, 15]})
Diagramm = Alt.chart (Daten) .mark_bar (). Encode (x = 'x', y = 'y')
Diagramm.Display ()Ausgabe
Die Auswahl der entsprechenden Bibliothek hängt von mehreren Faktoren ab: der Art Ihrer Aufgabe (Datenreinigung, Visualisierung, Modellierung), Datensatzgröße, Analyseziele und Ihrer Erfahrungsstufe. Berücksichtigen Sie die Stärken und Einschränkungen jeder Bibliothek, bevor Sie Ihre Auswahl treffen.
Die Beliebtheit von Python in der Datenanalyse beruht auf der Benutzerfreundlichkeit, der umfangreichen Bibliotheken, der starken Unterstützung der Community und der nahtlosen Integration in Big Data -Tools.
Pythons reichhaltiges Ökosystem der Bibliotheken ermöglicht es Datenanalysten, verschiedene Herausforderungen zu bewältigen, von einfachen Datenerforschung bis hin zu komplexen Aufgaben des maschinellen Lernens. Die Auswahl der richtigen Tools für den Job ist entscheidend. Diese Übersicht bietet eine solide Grundlage für die Auswahl der besten Python -Bibliotheken für Ihre Datenanalyseanforderungen.
Das obige ist der detaillierte Inhalt vonTop 20 Python -Bibliotheken für die Datenanalyse für 2025. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Detaillierte Erläuterung der Verwendung der Sprintf-Funktion
Detaillierte Erläuterung der Verwendung der Sprintf-Funktion
 So brechen Sie die automatische Verlängerung von Baidu Netdisk ab
So brechen Sie die automatische Verlängerung von Baidu Netdisk ab
 Der Unterschied zwischen div und span
Der Unterschied zwischen div und span
 So verwenden Sie debug.exe
So verwenden Sie debug.exe
 Die Direct3D-Funktion ist nicht verfügbar
Die Direct3D-Funktion ist nicht verfügbar
 Ist das Hongmeng-System einfach zu bedienen?
Ist das Hongmeng-System einfach zu bedienen?
 Python-Nummer zum String
Python-Nummer zum String
 Befehl zur Paketerfassung unter Linux
Befehl zur Paketerfassung unter Linux
 Wie wäre es mit einem N5095-Prozessor?
Wie wäre es mit einem N5095-Prozessor?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



