

In diesem Artikel werden die Abruf-Generation (RAG), eine hochmoderne KI-Technik, die die Reaktionsgenauigkeit durch Verschmelzung von Abruf- und Erzeugungsfähigkeiten steigert. RAG verbessert die Fähigkeit von AI, zuverlässige, kontextbezogene Antworten zu geben, indem er zuerst relevante, aktuelle Informationen von einer Wissensbasis abruft, bevor eine Antwort generiert wird. Die Diskussion deckt den RAG -Workflow im Detail ab, einschließlich der Verwendung von Vektordatenbanken für ein effizientes Datenabruf, die Bedeutung von Distanzmetriken für die Ähnlichkeitsübereinstimmung und darüber, wie Lag gemeinsame KI -Fallstricke wie Halluzinationen und Konfabulationen mindert. Es werden auch praktische Schritte zur Einrichtung und Implementierung von RAG durchgeführt, was dies zu einem umfassenden Leitfaden für alle macht, die die Abrufheit von KI-basierten Wissensabrechnungen verbessern möchten.
*Dieser Artikel ist Teil des *** Data Science Blogathon.
RAG ist eine KI -Methode, die die Antwortgenauigkeit verbessert, indem relevante Informationen abgerufen werden, bevor eine Antwort generiert wird. Im Gegensatz zu herkömmlicher KI, die ausschließlich auf Trainingsdaten beruht, durchsucht Lag nach einer Datenbank oder Wissensquelle nach aktuellen oder spezifischen Informationen. Diese Informationen informieren dann die Erzeugung einer genaueren und zuverlässigeren Antwort. Der RAG -Ansatz kombiniert Abruf- und Erzeugungsmodelle, um die Qualität und Genauigkeit generierter Inhalte, insbesondere bei NLP -Aufgaben, zu verbessern.
Weitere Lektüre: Abrufen-generale Generation für wissensintensive NLP-Aufgaben
Der Lag -Workflow besteht aus zwei Primärphasen: Abruf und Generation. Der Schritt-für-Schritt-Prozess ist unten beschrieben.
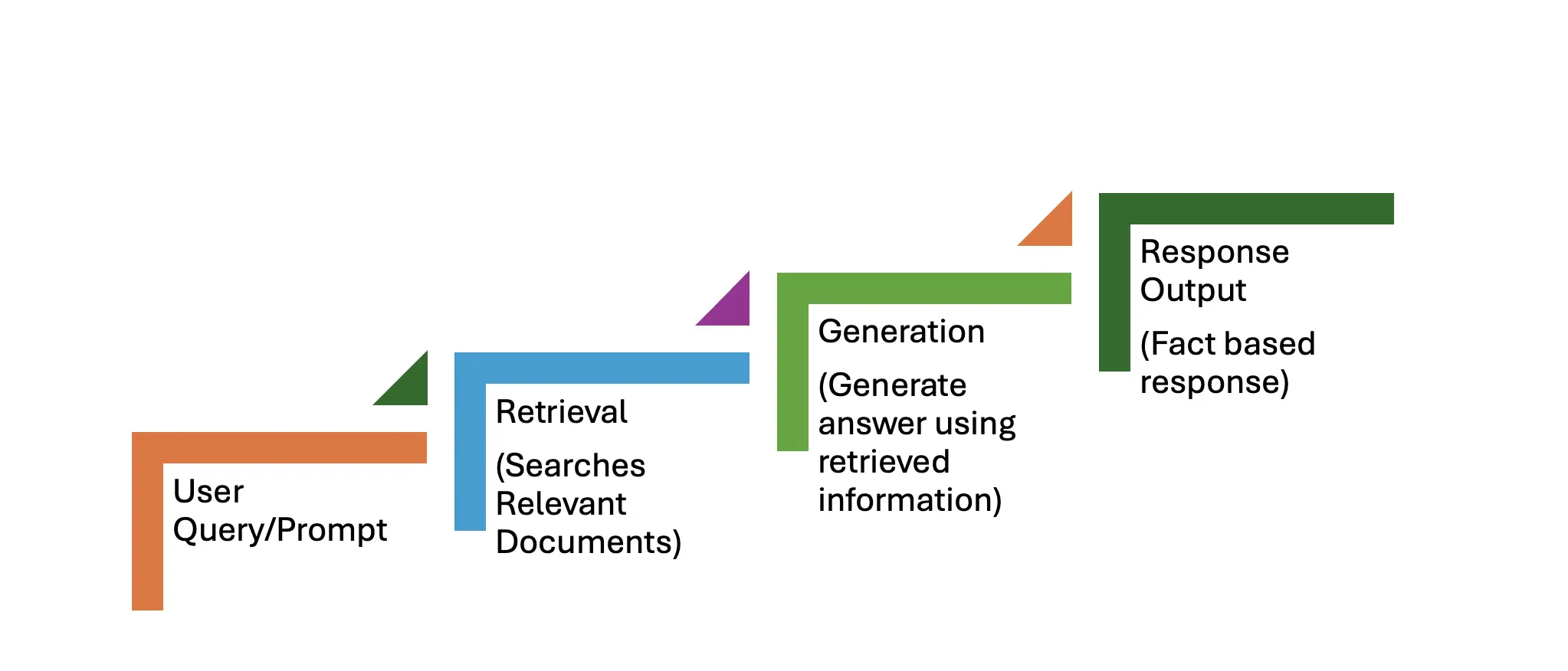
Eine Benutzerabfrage wie: "Was sind die neuesten Fortschritte beim Quantum Computing?" dient als Eingabeaufforderung.
Diese Phase umfasst drei Schritte:
Diese Phase umfasst auch drei Schritte:
Das System gibt eine sachlich genaue und aktuelle Reaktion zurück, die einem rein generativen Modell überlegen ist.
Der Vergleich von KI mit und ohne Lappen unterstreicht die transformative Kraft des Lappen. Traditionelle Modelle beruhen ausschließlich auf vorgebreiteten Daten, während RAG die Antworten mit dem Abrufen von Echtzeitinformationen verbessert und die Lücke zwischen statischer und dynamischer und kontextbezogener Ausgaben überbrückt.
| Mit Lappen | Ohne Lappen |
|---|---|
| Ruft aktuelle Informationen aus externen Quellen ab. | Stützt sich ausschließlich auf vorgeborene (potenziell veraltete) Wissen. |
| Bietet spezifische Lösungen (z. B. Patch -Versionen, Konfigurationsänderungen). | Erzeugt vage, generalisierte Antworten ohne umsetzbare Details. |
| Minimiert das Halluzinationsrisiko, indem die Antworten in realen Dokumenten ergriffen werden. | Ein höheres Risiko für Halluzination oder Ungenauigkeiten, insbesondere für jüngste Informationen. |
| Enthält die neuesten Anbieter -Beratungen oder Sicherheitspatches. | Kann sich der jüngsten Ratschläge oder Aktualisierungen nicht bewusst sein. |
| Kombiniert interne (organisationsspezifische) und externe (öffentliche Datenbank-) Informationen. | Neue oder organisationsspezifische Informationen kann nicht abgerufen werden. |
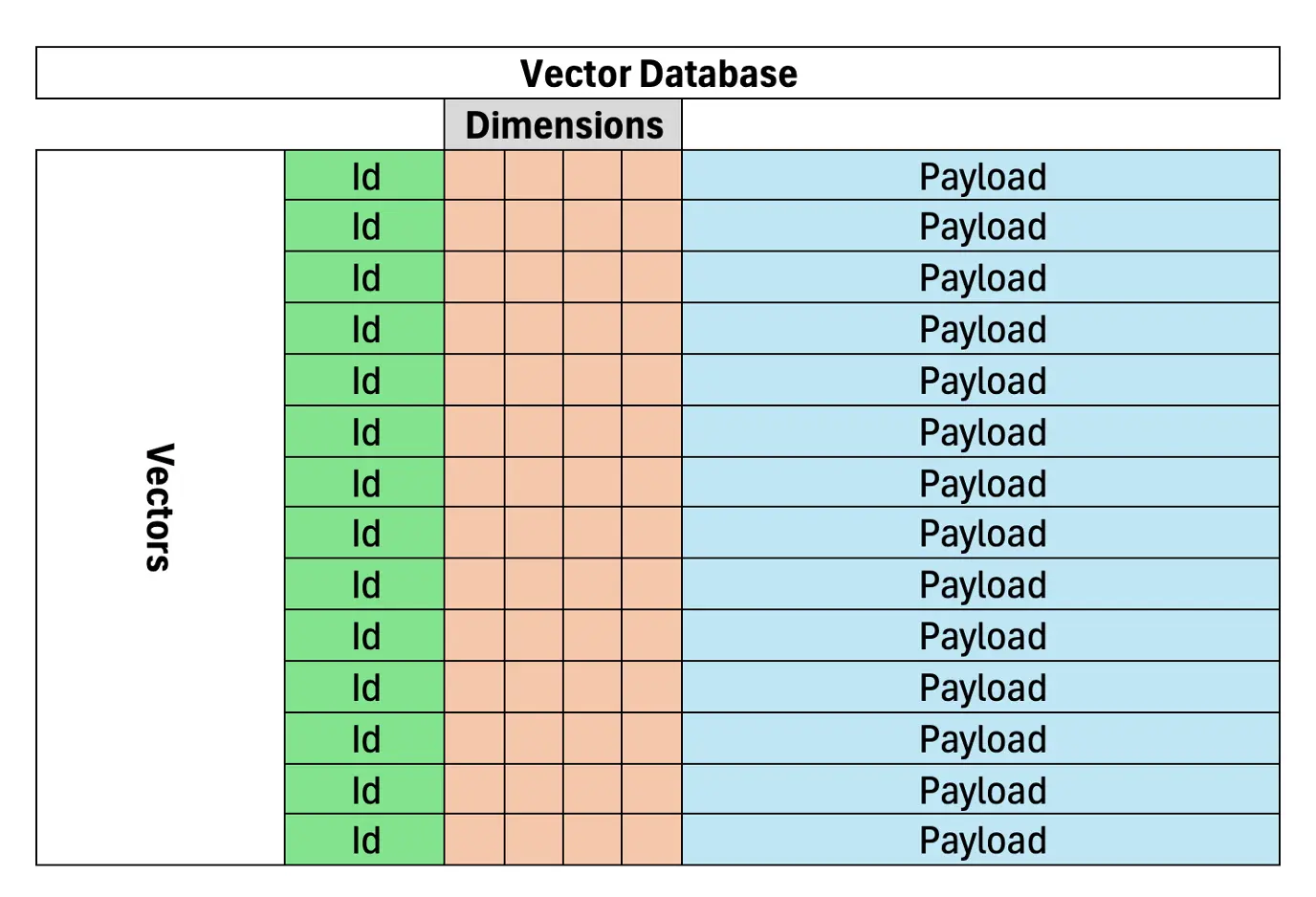
Vektordatenbanken sind entscheidend für ein effizientes und genaues Dokument- oder Datenabruf in RAG, basierend auf der semantischen Ähnlichkeit. Im Gegensatz zur keyword-basierten Suche, die sich auf den exakten Term-Matching stützt, stellen Vektordatenbanken Text als Vektoren in einem hochdimensionalen Raum dar, wodurch ähnliche Bedeutungen zusammengefügt werden. Dies macht sie für Lappensysteme sehr geeignet. Eine Vektor -Datenbank speichert vektorisierte Dokumente und ermöglicht ein genaueres Informationsabruf für KI -Modelle.
(Die verbleibenden Abschnitte würden einem ähnlichen Muster der Umformung und Umstrukturierung folgen, wodurch die ursprünglichen Informationen und die Bildplatzierung beibehalten werden.)
Das obige ist der detaillierte Inhalt vonVerbesserung der AI -Halluzinationen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So lösen Sie ungültige Syntax in Python
So lösen Sie ungültige Syntax in Python
 securefx kann keine Verbindung herstellen
securefx kann keine Verbindung herstellen
 Java konfiguriert JDK-Umgebungsvariablen
Java konfiguriert JDK-Umgebungsvariablen
 Tabellenfeld löschen
Tabellenfeld löschen
 Fil-Währungspreis Echtzeitpreis
Fil-Währungspreis Echtzeitpreis
 So öffnen Sie eine ISO-Datei
So öffnen Sie eine ISO-Datei
 Was ist ein Festplattenkontingent?
Was ist ein Festplattenkontingent?
 Die Hauptkomponenten von dhtml
Die Hauptkomponenten von dhtml
 Welche Rolle spielt die Kafka-Verbrauchergruppe?
Welche Rolle spielt die Kafka-Verbrauchergruppe?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



