

In diesem Blog -Beitrag werden effiziente Speicherverwaltungstechniken zum Laden großer Pytorch -Modelle untersucht, insbesondere bei der Bearbeitung begrenzter GPU- oder CPU -Ressourcen. Der Autor konzentriert sich auf Szenarien, in denen Modelle unter Verwendung von torch.save(model.state_dict(), "model.pth") gespeichert werden. Während die Beispiele ein großes Sprachmodell (LLM) verwenden, gelten die Techniken für jedes Pytorch -Modell.
Schlüsselstrategien für die effiziente Modellbelastung:
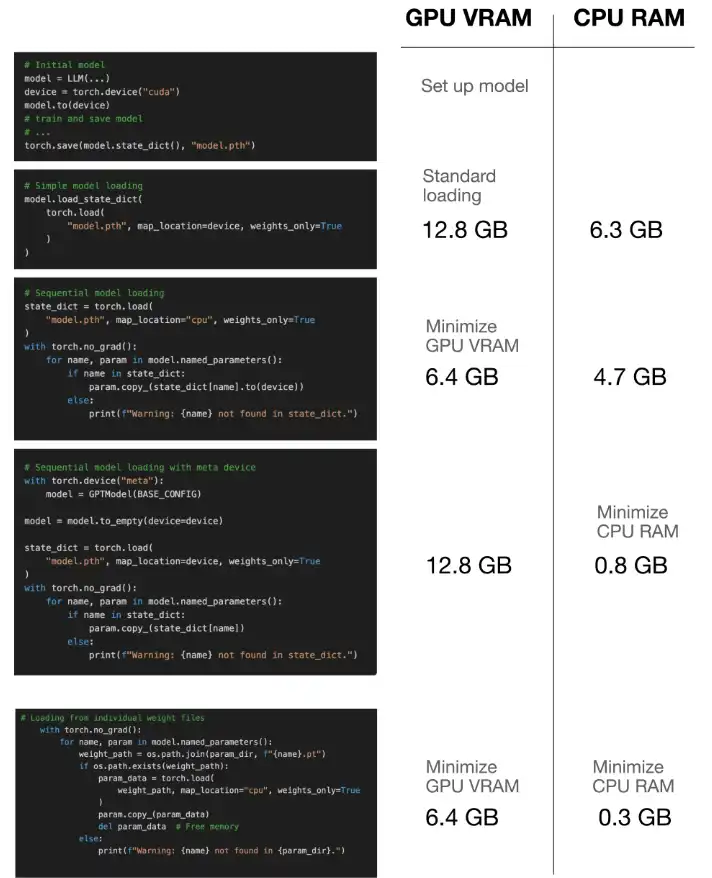
Der Artikel beschreibt verschiedene Methoden zur Optimierung des Speicherverbrauchs während des Modellladens:
Sequentielle Gewichtbelastung: Diese Technik lädt die Modellarchitektur in die GPU und kopiert dann iterativ individuelle Gewichte aus dem CPU -Speicher in die GPU. Dies verhindert das gleichzeitige Vorhandensein sowohl des vollständigen Modells als auch des vollständigen Gewichts im GPU -Gedächtnis, wodurch der Verbrauch des Spitzengedächtnisses signifikant verringert wird.
Meta -Gerät: Pytorchs "Meta" -Gerät ermöglicht die Erstellung von Tensor ohne sofortige Speicherzuweisung. Das Modell wird auf dem Meta -Gerät initialisiert und dann in die GPU übertragen, und die Gewichte werden direkt auf die GPU geladen, wodurch die Verwendung von CPU -Speicher minimiert wird. Dies ist besonders nützlich für Systeme mit begrenztem CPU -RAM.
mmap=True in torch.load() : Diese Option verwendet die Speicher-Made-Datei-I/A-Datei-Datei-Datei, sodass PyTorch Modelldaten direkt von der Datenträger auf Bedarf lesen kann, anstatt alles in RAM zu laden. Dies ist ideal für Systeme mit begrenztem CPU -Speicher und schneller Festplatten -E/A.
Individuelles Gewichtssparen und Laden: Als letztes Ausweg für extrem begrenzte Ressourcen schlägt der Artikel vor, jeden Modellparameter (Tensor) als separate Datei zu speichern. Das Laden erfolgt dann jeweils ein Parameter und minimiert zu jedem Zeitpunkt den Speicher Fußabdruck. Dies kommt auf Kosten des erhöhten E/A -Overheads.
Praktische Implementierung und Benchmarking:
Der Beitrag enthält Python -Code -Snippets, die jede Technik demonstrieren, einschließlich Dienstprogrammfunktionen für die Verfolgung der GPU- und CPU -Speicherverwendung. Diese Benchmarks veranschaulichen die von jeder Methode erzielten Speichereinsparungen. Der Autor vergleicht die Speicherverwendung jedes Ansatzes und hebt die Kompromisse zwischen Gedächtniseffizienz und potenziellen Leistungsauswirkungen hervor.
Abschluss:
Der Artikel schließt mit der Betonung der Bedeutung der Speicherbelastung des Speichermodells, insbesondere für große Modelle. Es wird empfohlen, die am besten geeignete Technik basierend auf den spezifischen Hardwarebeschränkungen (CPU -RAM, GPU VRAM) und E/A -Geschwindigkeiten auszuwählen. Der mmap=True -Ansatz wird im Allgemeinen für begrenzte CPU -RAM bevorzugt, während die individuelle Gewichtsbelastung ein letzter Ausweg für extrem eingeschränkte Umgebungen ist. Die sequentielle Lademethode bietet eine gute Balance für viele Szenarien.
Das obige ist der detaillierte Inhalt vonSpeichereffizientes Modellgewichtsbeladung in Pytorch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL-Datenbank wiederherstellen
MySQL-Datenbank wiederherstellen
 Was sind die Federrahmen?
Was sind die Federrahmen?
 So entsperren Sie Android-Berechtigungsbeschränkungen
So entsperren Sie Android-Berechtigungsbeschränkungen
 C-Sprache, um das kleinste gemeinsame Vielfache zu finden
C-Sprache, um das kleinste gemeinsame Vielfache zu finden
 Was ist Benutzerklebrigkeit?
Was ist Benutzerklebrigkeit?
 Was ist der Leerzeichencode in HTML?
Was ist der Leerzeichencode in HTML?
 Verwendung von Head-Befehlen
Verwendung von Head-Befehlen
 Der Zweck des Levels
Der Zweck des Levels
 Was sind die Hauptunterschiede zwischen Linux und Windows?
Was sind die Hauptunterschiede zwischen Linux und Windows?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



