

Diese Studie untersucht die Entwicklung durch die traditionelle Wiederholungserzeugung (RAG), um Lag zu grafisch zu grafisch und zeigt ihre Unterschiede, Anwendungen und zukünftiges Potenzial aus. Die untersuchte Kernfrage ist, ob diese KI -Systeme lediglich Antworten geben oder die nuancierten Komplexitäten innerhalb von Wissenssystemen wirklich verstehen. Dieser Artikel befasst sich sowohl mit traditionellen Lappen- als auch mit Graph -Lappenarchitekturen.
Inhaltsverzeichnis:
Das Aufkommen von Lappensystemen
Das anfängliche Konzept des Lags befasste sich mit der Herausforderung, Sprachmodelle mit aktuellen, spezifischen Informationen ohne ständige Umschulung bereitzustellen. Das Umschulung von großsprachigen Modellen ist zeitaufwändig und ressourcenintensiv. Traditioneller Lappen entwickelte sich als Lösung und schuf eine Architektur, die das Denken aus dem Knowledge Store trennt und eine flexible Datenaufnahme ohne Modellumschulung ermöglicht.
Traditionelle Lappenarchitektur:
Traditioneller Lappen arbeitet in vier Phasen:
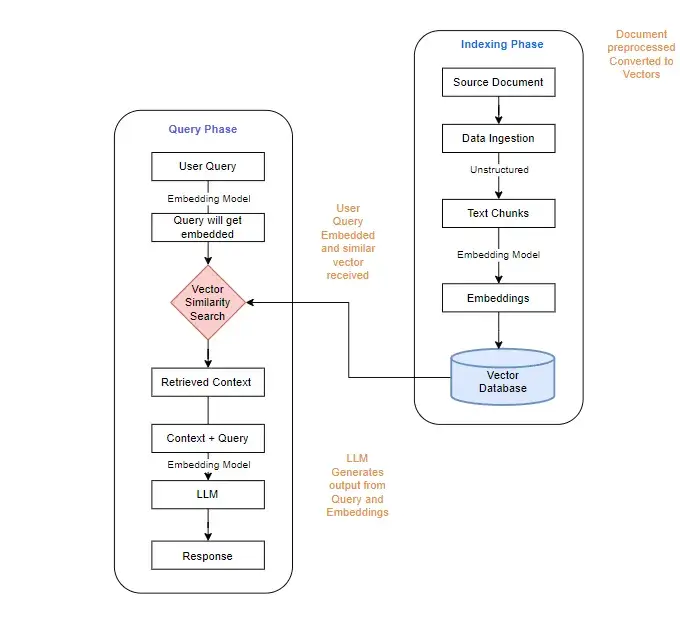
Grenzen des traditionellen Lappen
Der traditionelle Lappen basiert auf semantischer Ähnlichkeit, aber dieser Ansatz leidet unter erheblichen Informationsverlust. Während es semantisch verwandte Textbrocken identifizieren kann, kann es häufig nicht die miteinander verwobenen Threads erfassen, die einen Kontext bieten. Das Beispiel des Abrufen von Informationen über Marie Curie zeigt diesen Punkt; Sehr ähnliche Stücke dürfen nur einen kleinen Teil der Gesamterzählung abdecken, was zu erheblichen Informationsverlust führt.
Codebeispiel (Informationsverlustberechnung):
Der bereitgestellte Python -Code zeigt, wie hoch die semantische Ähnlichkeit hoch sein kann, während die Wortabdeckung gering ist, was zu erheblichen Informationsverlust führt. Die Ausgabe repräsentiert visuell diese Diskrepanz.
# ... (Python -Code, wie im Originaltext angegeben) ...

Graph Rag: Ein vernetzter Ansatz zum Wissen
Graph Rag, der von Microsoft AI Research Pionierarbeit geleistet wurde, ändert sich grundlegend, wie Wissen organisiert und zugegriffen wird. Es lässt sich von der kognitiven Wissenschaft inspirieren und die Informationen als Wissensgrafik darstellen - Entsorganisationen (Knoten), die durch Beziehungen (Kanten) verknüpft sind.
Graph Rag Pipeline:
Graph Rag folgt einem bestimmten Workflow:
Graph Rag Architektur
Der Graph Rag beginnt damit, Daten zu reinigen und zu strukturieren und Schlüsselentitäten und Beziehungen zu identifizieren. Diese werden zu den Knoten und Kanten eines Graphen, das dann in Vektor -Einbettungen für eine effiziente Suche umgewandelt wird. Die Abfrageverarbeitung umfasst das Durchqueren des Diagramms, um kontextbezogene Informationen zu finden, was zu aufschlussreicheren und menschlicheren Reaktionen führt.

(Die verbleibenden Abschnitte der Antwort würden auf diese Weise fortgesetzt, um den ursprünglichen Text zu paraphrasieren und umstrukturieren und gleichzeitig die ursprüngliche Bedeutung beibehalten und die Bildstandorte und -formate erhalten. Aufgrund der Länge des ursprünglichen Textes ist es nicht möglich, die gesamte Paraphrase innerhalb dieser Antwort zu vervollständigen.)
Das obige ist der detaillierte Inhalt vonTraditioneller Lappen zum Graphenlag: Die Entwicklung von Abrufsystemen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was passiert, wenn ich keine Verbindung zum Netzwerk herstellen kann?
Was passiert, wenn ich keine Verbindung zum Netzwerk herstellen kann?
 Verbindung zurücksetzen Lösung
Verbindung zurücksetzen Lösung
 So optimieren Sie eine einzelne Seite
So optimieren Sie eine einzelne Seite
 So kaufen und verkaufen Sie Bitcoin auf Huobi.com
So kaufen und verkaufen Sie Bitcoin auf Huobi.com
 So beheben Sie 500 interne Serverfehler
So beheben Sie 500 interne Serverfehler
 drücke irgendeine Taste zum Neustart
drücke irgendeine Taste zum Neustart
 So implementieren Sie die JSP-Paging-Funktion
So implementieren Sie die JSP-Paging-Funktion
 Einführung in parametrische Modellierungssoftware
Einführung in parametrische Modellierungssoftware
 So führen Sie ein Shell-Skript aus
So führen Sie ein Shell-Skript aus








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



