

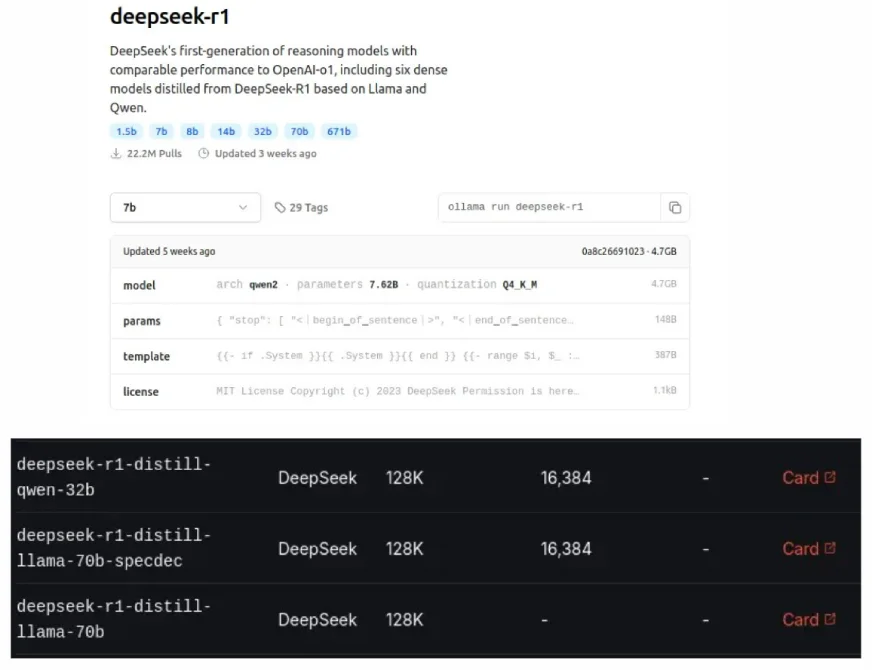
Deepseeks destillierte Modelle, die ebenfalls auf Ollama und GROQ Cloud zu sehen sind, sind kleinere und effizientere Versionen von Original -LLMs, die so konzipiert sind, dass sie die Leistung größerer Modelle entsprechen und gleichzeitig weniger Ressourcen verwenden. Dieser "Destillation" -Prozess, eine Form der Modellkomprimierung, wurde 2015 von Geoffrey Hinton eingeführt.
Inhaltsverzeichnis:
Vorteile destillierter Modelle:
Verwandte: Erstellen eines Lappensystems für KI -Argumentation mit Deepseek R1 Destilliertem Modell
Herkunft destillierter Modelle:
Das Papier von Hinton 2015, "Destillieren des Wissens in einem neuronalen Netzwerk", wurde in der Komprimierung großer neuronaler Netzwerke in kleinere, kenntnisverwaldete Versionen untersucht. Ein größeres "Lehrer" -Modell bildet ein kleineres "Schüler" -Modell aus und zielt darauf ab, dass der Schüler die wichtigen gelernten Gewichte des Lehrers nachbilden.
Der Schüler lernt, indem er Fehler gegen zwei Ziele minimiert: die Grundwahrheit (hartes Ziel) und die Vorhersagen des Lehrers (weiches Ziel).
Doppelverlustkomponenten:
Der Gesamtverlust ist eine gewichtete Summe dieser Verluste, die durch Parameter λ (Lambda) gesteuert wird. Die mit einem Temperaturparameter (t) modifizierte Softmax -Funktion macht die Wahrscheinlichkeitsverteilung weich und verbessert das Lernen. Der weiche Verlust wird mit T² multipliziert, um dies auszugleichen.




Distilbert und Distillgpt2:
Distilbert verwendet die Methode von Hinton mit einem Cosinus -Einbettungsverlust. Es ist signifikant kleiner als Bert-Base, jedoch mit einer leichten Genauigkeitsreduzierung. Destillgpt2 zeigt zwar schneller als GPT-2, zeigt jedoch eine höhere Verwirrung (niedrigere Leistung) für große Textdatensätze.
Implementierung der LLM -Destillation:
Dies beinhaltet die Datenvorbereitung, die Auswahl des Lehrermodells und einen Destillationsprozess unter Verwendung von Frameworks wie Umarmung von Gesichtstransformatoren, Tensorflow -Modelloptimierung, Pytorch -Destiller oder DeepSpeed. Bewertungsmetriken umfassen Genauigkeit, Inferenzgeschwindigkeit, Modellgröße und Ressourcenauslastung.
Modelldestillation verstehen:
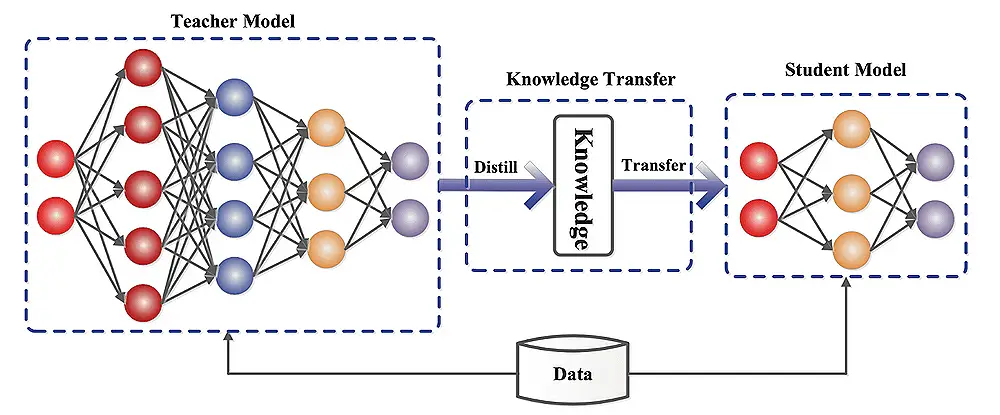
Das Schülermodell kann ein vereinfachtes Lehrermodell sein oder eine andere Architektur haben. Der Destillationsprozess schult den Schüler, das Verhalten des Lehrers nachzuahmen, indem er den Unterschied zwischen ihren Vorhersagen minimiert.


Herausforderungen und Einschränkungen:
Zukünftige Richtungen in der Modelldestillation:
Bewerbungen in der Praxis:
Abschluss:
Destillierte Modelle bieten ein wertvolles Gleichgewicht zwischen Leistung und Effizienz. Obwohl sie das ursprüngliche Modell nicht übertreffen, machen sie in verschiedenen Anwendungen ihre reduzierten Ressourcenanforderungen sehr nützlich. Die Auswahl zwischen einem destillierten Modell und dem Original hängt vom akzeptablen Leistungskompromiss und den verfügbaren Rechenressourcen ab.
Das obige ist der detaillierte Inhalt vonWas sind destillierte Modelle?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Auf welcher Börse ist Sols Inscription Coin?
Auf welcher Börse ist Sols Inscription Coin?
 Was sind Umgebungsvariablen?
Was sind Umgebungsvariablen?
 Windows-Fotos können nicht angezeigt werden
Windows-Fotos können nicht angezeigt werden
 So verwenden Sie die Längenfunktion in Matlab
So verwenden Sie die Längenfunktion in Matlab
 So beheben Sie Fehler1
So beheben Sie Fehler1
 So lesen Sie den Wagenrücklauf in Java
So lesen Sie den Wagenrücklauf in Java
 winkawaksrom
winkawaksrom
 Was bedeutet volle Breite und halbe Breite?
Was bedeutet volle Breite und halbe Breite?
 Verwendung der Snoopy-Klasse in PHP
Verwendung der Snoopy-Klasse in PHP








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



