
 Technologie-Peripheriegeräte
KI
Konvertieren Sie Textdokumente in eine TF-IDF-Matrix mit TFIDFVectorizer
Technologie-Peripheriegeräte
KI
Konvertieren Sie Textdokumente in eine TF-IDF-Matrix mit TFIDFVectorizer
Konvertieren Sie Textdokumente in eine TF-IDF-Matrix mit TFIDFVectorizer

In diesem Artikel werden die TF-IDF-Technik (Frequenz-Inverse-Dokumentfrequenz) erläutert, ein entscheidendes Werkzeug in der natürlichen Sprachverarbeitung (NLP) zur Analyse von Textdaten. TF-IDF übertrifft die Einschränkungen der Basis-Wörter-Ansätze, indem sie Begriffe basierend auf ihrer Häufigkeit innerhalb eines Dokuments und ihrer Seltenheit über eine Sammlung von Dokumenten gewichtet werden. Diese verbesserte Gewichtung verbessert die Textklassifizierung und erhöht die analytischen Fähigkeiten von maschinellen Lernmodellen. Wir werden demonstrieren, wie ein TF-IDF-Modell in Python von Grund auf neu erstellt und numerische Berechnungen durchgeführt werden.
Inhaltsverzeichnis
- Schlüsselbegriffe in TF-IDF
- Term Frequenz (TF) erklärt
- Dokumentfrequenz (DF) erläutert
- Inverse Dokumentfrequenz (IDF) erläutert
- TF-IDF verstehen
- Numerische TF-IDF-Berechnung
- Schritt 1: Berechnung der Termfrequenz (TF)
- Schritt 2: Berechnung der inversen Dokumentfrequenz (IDF)
- Schritt 3: Berechnung von TF-IDF
- Python-Implementierung mit einem integrierten Datensatz
- Schritt 1: Installation der erforderlichen Bibliotheken
- Schritt 2: Bibliotheken importieren
- Schritt 3: Laden des Datensatzes
- Schritt 4: Initialisieren von
TfidfVectorizer - Schritt 5: Anpassen und Transformieren von Dokumenten
- Schritt 6: Untersuchung der TF-IDF-Matrix untersuchen
- Abschluss
- Häufig gestellte Fragen
Schlüsselbegriffe in TF-IDF
Definieren wir vor dem Fortfahren die wichtigsten Begriffe:
- T : Begriff (individuelles Wort)
- D : Dokument (eine Reihe von Wörtern)
- N : Gesamtzahl der Dokumente im Korpus
- Corpus : Die gesamte Sammlung von Dokumenten
Term Frequenz (TF) erklärt
Die Term Frequenz (TF) quantifiziert, wie oft ein Begriff in einem bestimmten Dokument erscheint. Ein höherer TF zeigt eine größere Bedeutung in diesem Dokument an. Die Formel lautet:
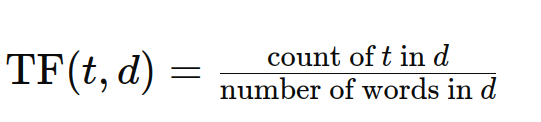
Dokumentfrequenz (DF) erläutert
Dokumentfrequenz (DF) misst die Anzahl der Dokumente innerhalb des Korpus, der einen bestimmten Term enthält. Im Gegensatz zu TF zählt es das Vorhandensein eines Begriffs und nicht des Vorkommens. Die Formel lautet:
Df (t) = Anzahl der Dokumente, die Begriff t enthalten
Inverse Dokumentfrequenz (IDF) erläutert
Die inverse Dokumentfrequenz (IDF) bewertet die Informativität eines Wortes. Während TF alle Begriffe gleich behandelt, sind IDF -Abfälle gemeinsame Wörter (wie Stoppwörter) und seltenere Begriffe. Die Formel lautet:
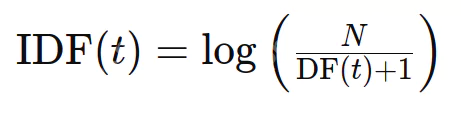
wobei n die Gesamtzahl der Dokumente ist und DF (t) die Anzahl der Dokumente, die Begriff t enthalten.
TF-IDF verstehen
TF-IDF kombiniert Term Häufigkeit und umgekehrte Dokumentfrequenz, um die Signifikanz eines Begriffs innerhalb eines Dokuments relativ zum gesamten Korpus zu bestimmen. Die Formel lautet:
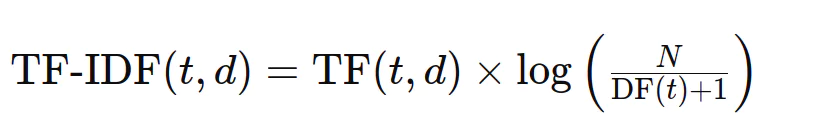
Numerische TF-IDF-Berechnung
Veranschaulichen Sie die numerische TF-IDF-Berechnung mit Beispieldokumenten:
Unterlagen:
- "Der Himmel ist blau."
- "Die Sonne ist heute hell."
- "Die Sonne am Himmel ist hell."
- "Wir können die leuchtende Sonne sehen, die helle Sonne."
Befolgen Sie die im Originaltext beschriebenen Schritte, wir berechnen TF, IDF und dann TF-IDF für jeden Begriff in jedem Dokument. (Die detaillierten Berechnungen werden hier für die Kürze weggelassen, spiegeln jedoch das ursprüngliche Beispiel wider.)
Python-Implementierung mit einem integrierten Datensatz
In diesem Abschnitt wird die TF-IDF-Berechnung unter Verwendung von TfidfVectorizer von Scikit-Learn und dem 20 Newsgroups-Datensatz angezeigt.
Schritt 1: Installation der erforderlichen Bibliotheken
PIP Installieren Sie Scikit-Learn
Schritt 2: Bibliotheken importieren
Pandas als PD importieren Aus sklearn.datasets importieren Sie Fetch_20newsgroups von sklearn.feature_extraction.text import tfidfVectorizer
Schritt 3: Laden des Datensatzes
Newsgroups = Fetch_20NewsGroups (Subset = 'Train')
Schritt 4: Initialisieren von TfidfVectorizer
vectorizer = tfidfVectorizer (stop_words = 'englisch', max_features = 1000)
Schritt 5: Anpassen und Transformieren von Dokumenten
tfidf_matrix = vectorizer.fit_transform (newsgroups.data)
Schritt 6: Untersuchung der TF-IDF-Matrix untersuchen
df_tfidf = pd.dataframe (tfidf_matrix.toarray (), columns = vectorizer.get_feature_names_out ())) df_tfidf.head ()
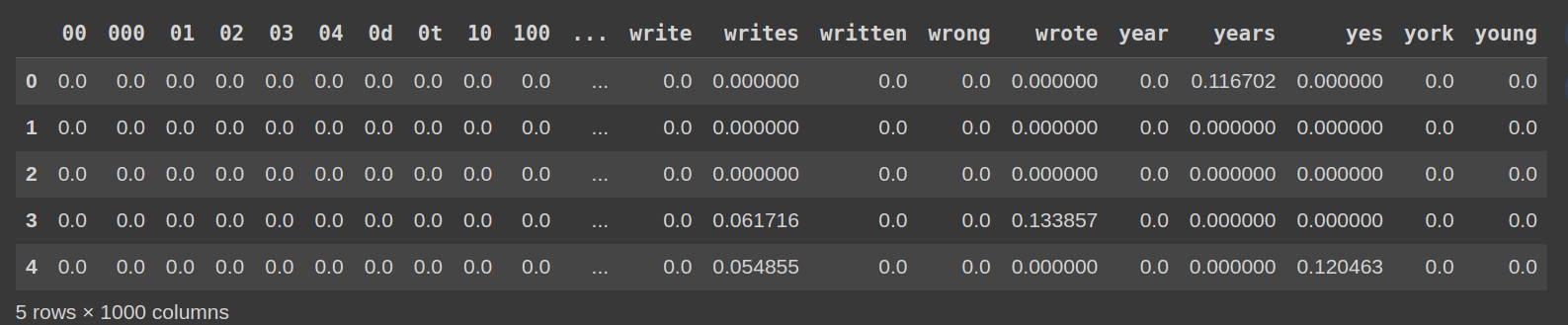
Abschluss
Unter Verwendung des 20 Newsgroups-Datensatzes und TfidfVectorizer transformieren wir Textdokumente effizient in eine TF-IDF-Matrix. Diese Matrix stellt die Bedeutung jedes Begriffs dar und ermöglicht verschiedene NLP -Aufgaben wie die Klassifizierung und Clusterbildung von Text. Der TfidfVectorizer von Scikit-Learn vereinfacht diesen Prozess erheblich.
Häufig gestellte Fragen
Der FAQS-Abschnitt bleibt weitgehend unverändert und adressiert die logarithmische Natur der IDF, die Skalierbarkeit großer Datensätze, Einschränkungen von TF-IDF (ignorierende Wortreihenfolge und Kontext ignorieren) und gemeinsame Anwendungen (Suchmaschinen, Textklassifizierung, Clustering, Zusammenfassung).
Das obige ist der detaillierte Inhalt vonKonvertieren Sie Textdokumente in eine TF-IDF-Matrix mit TFIDFVectorizer. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1677
1677
 14
1431
52
1334
25
1280
29
1257
24
14
1431
52
1334
25
1280
29
1257
24

 Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Während der Arbeit an Agentic AI navigieren Entwickler häufig die Kompromisse zwischen Geschwindigkeit, Flexibilität und Ressourceneffizienz. Ich habe den Agenten-KI-Framework untersucht und bin auf Agno gestoßen (früher war es phi-
 OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
Die Veröffentlichung umfasst drei verschiedene Modelle, GPT-4.1, GPT-4.1 Mini und GPT-4.1-Nano, die einen Zug zu aufgabenspezifischen Optimierungen innerhalb der Landschaft des Großsprachenmodells signalisieren. Diese Modelle ersetzen nicht sofort benutzergerichtete Schnittstellen wie
 Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
SQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulieren Raketenstarts mit Rocketpy: Eine umfassende Anleitung Dieser Artikel führt Sie durch die Simulation von Rocketpy-Starts mit hoher Leistung mit Rocketpy, einer leistungsstarken Python-Bibliothek. Wir werden alles abdecken, von der Definition von Raketenkomponenten bis zur Analyse von Simula
 DeepCoder-14b: Der Open-Source-Wettbewerb mit O3-Mini und O1
Apr 26, 2025 am 09:07 AM
DeepCoder-14b: Der Open-Source-Wettbewerb mit O3-Mini und O1
Apr 26, 2025 am 09:07 AM
In einer bedeutenden Entwicklung für die KI-Community haben Agentica und gemeinsam KI ein Open-Source-KI-Codierungsmodell namens DeepCoder-14b veröffentlicht. Angebotsfunktionen der Codegenerierung mit geschlossenen Wettbewerbern wie OpenAI,
 Die Eingabeaufforderung: Chatgpt generiert gefälschte Pässe
Apr 16, 2025 am 11:35 AM
Die Eingabeaufforderung: Chatgpt generiert gefälschte Pässe
Apr 16, 2025 am 11:35 AM
Der Chip Giant Nvidia sagte am Montag, es werde zum ersten Mal in den USA die Herstellung von KI -Supercomputern - Maschinen mit der Verarbeitung reichlicher Daten herstellen und komplexe Algorithmen ausführen. Die Ankündigung erfolgt nach Präsident Trump SI
 Eine Eingabeaufforderung kann die Schutzmaßnahmen von den großen LLM umgehen
Apr 25, 2025 am 11:16 AM
Eine Eingabeaufforderung kann die Schutzmaßnahmen von den großen LLM umgehen
Apr 25, 2025 am 11:16 AM
Die bahnbrechende Forschung von HiddenLayer zeigt eine kritische Anfälligkeit in führenden großsprachigen Modellen (LLMs). Ihre Ergebnisse zeigen eine universelle Bypass -Technik, die als "Policy Puppetry" bezeichnet wird und fast alle wichtigen LLMs umgehen können
 Guy Peri hilft bei der Zukunft von McCormick durch Datenumwandlung
Apr 19, 2025 am 11:35 AM
Guy Peri hilft bei der Zukunft von McCormick durch Datenumwandlung
Apr 19, 2025 am 11:35 AM
Guy Peri ist McCormicks Chief Information und Digital Officer. Obwohl Peri nur sieben Monate nach seiner Rolle eine umfassende Transformation der digitalen Fähigkeiten des Unternehmens vorantreibt. Sein beruflicher Fokus auf Daten und Analysen informiert
