

ExtJS中文乱码之GBK格式编码解决方案及代码_extjs

这几天做后台看了一些Ext的知识,在切入工作项目的时候出现了乱码情况,所以就总结了这篇ExtJS中文乱码之GBK格式编码解决办法的文章,作为记录。
1、具体情况:
在引入:
02.
03.
04.
05.
后,写了一个简单的例子:
结果出现:
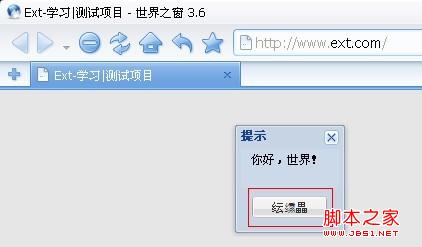
2、页面的编码是GBK,具体代码如下:
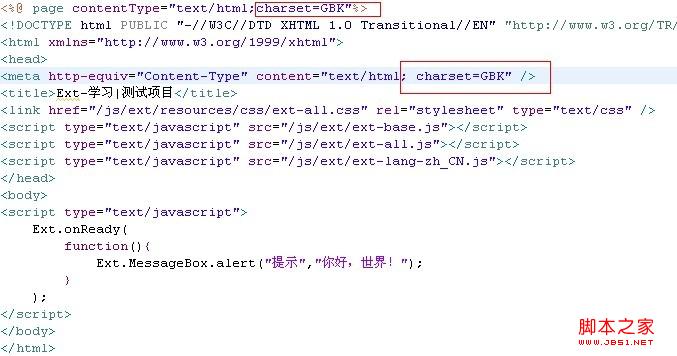
3、解决办法:
(1)把页面的编码定义为UFT-8后正常,但项目指定编码是UTF-8,所以不能采用这个思路。
(2)把引入的资源文件(/js/ext/ext-lang-zh_CN.js)改变为合适的编码,具体如下:
A 、用EditPlus打开这个js文件,选择另存为,如下图:
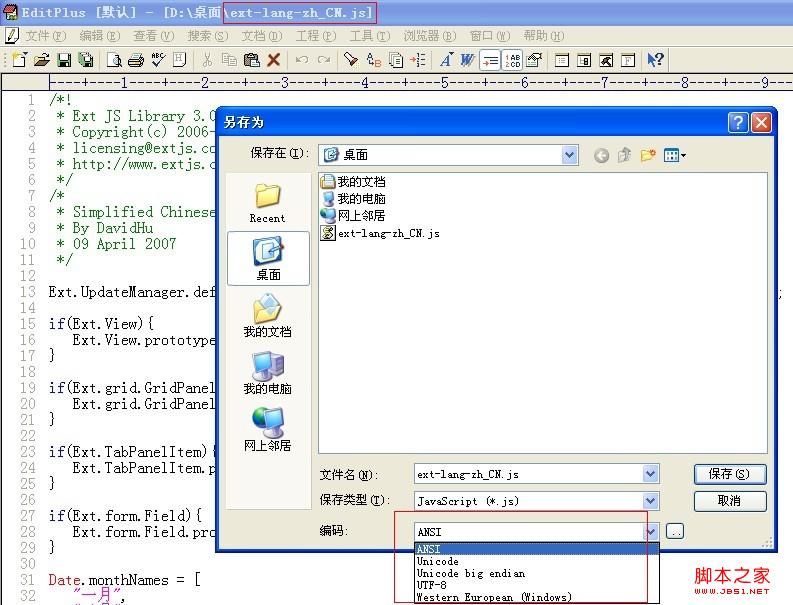
B、可以看到编码选项一共有5项,但是都不是我们需要的,我们点击后面的 更多的小按钮(上面有两个点的不起眼的哪个按钮)
看到下图后,选择图中的编码并确认:

然后,替换工程里面的js,再测试:
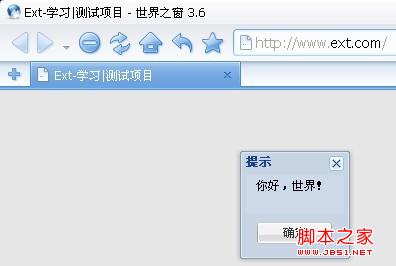
可以看到,乱码问题已经解决,文字显示正常了。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 Methoden zur Lösung des Problems verstümmelter chinesischer Zeichen in PHP Dompdf
Mar 05, 2024 pm 03:45 PM
Methoden zur Lösung des Problems verstümmelter chinesischer Zeichen in PHP Dompdf
Mar 05, 2024 pm 03:45 PM
Methoden zur Lösung des chinesischen verstümmelten Problems von PHPDompdf PHPDompdf ist ein Tool zum Konvertieren von HTML-Dokumenten in PDF-Dateien. Es ist leistungsstark und einfach zu verwenden. Allerdings stößt man bei der Verarbeitung chinesischer Inhalte manchmal auf das Problem verstümmelter chinesischer Schriftzeichen. In diesem Artikel werden einige Methoden zur Lösung des Problems verstümmelter chinesischer Zeichen in PHPDompdf vorgestellt und spezifische Codebeispiele bereitgestellt. 1. Bei der Verwendung von Schriftartdateien zur Verarbeitung chinesischer Inhalte besteht ein häufiges Problem darin, dass Dompdf standardmäßig keine chinesischen Inhalte unterstützt.
 11 gängige Techniken zur Kodierung von Klassifizierungsmerkmalen
Apr 12, 2023 pm 12:16 PM
11 gängige Techniken zur Kodierung von Klassifizierungsmerkmalen
Apr 12, 2023 pm 12:16 PM
Algorithmen für maschinelles Lernen akzeptieren nur numerische Eingaben. Wenn wir also auf kategoriale Merkmale stoßen, werden wir die kategorialen Merkmale kodieren. In diesem Artikel werden 11 gängige Methoden zur Kodierung kategorialer Variablen zusammengefasst. 1. ONE HOT ENCODING Die beliebteste und am häufigsten verwendete Kodierungsmethode ist One Hot Enoding. Eine einzelne Variable mit n Beobachtungen und d unterschiedlichen Werten wird in d binäre Variablen mit n Beobachtungen umgewandelt, wobei jede binäre Variable durch ein Bit (0, 1) identifiziert wird. Beispiel: Die einfachste Implementierung nach dem Codieren ist die Verwendung von pandas' get_dummiesnew_df=pd.get_dummies(columns=[‘Sex’], data=df)2,
 Wie viele Bytes belegen utf8-codierte chinesische Zeichen?
Feb 21, 2023 am 11:40 AM
Wie viele Bytes belegen utf8-codierte chinesische Zeichen?
Feb 21, 2023 am 11:40 AM
UTF8-kodierte chinesische Zeichen belegen 3 Bytes. Bei der UTF-8-Kodierung entspricht ein chinesisches Zeichen drei Bytes und ein chinesisches Satzzeichen belegt drei Bytes, während bei der Unicode-Kodierung ein chinesisches Zeichen (einschließlich traditionellem Chinesisch) zwei Bytes entspricht. UTF-8 benötigt zur Kodierung jedes Zeichens nur 1 Byte. Für Latein, Griechisch, Kyrillisch und Hebräisch sind 2 Byte erforderlich Codierung.
 Die ultimative Lösung für das Problem der verstümmelten chinesischen Zeichen in PyCharm
Jan 27, 2024 am 08:00 AM
Die ultimative Lösung für das Problem der verstümmelten chinesischen Zeichen in PyCharm
Jan 27, 2024 am 08:00 AM
Die ultimative Methode zur Lösung des Problems verstümmelter chinesischer Zeichen in PyCharm erfordert spezifische Codebeispiele. Einführung: PyCharm ist eine häufig verwendete integrierte Entwicklungsumgebung (IDE) für Python und verfügt über leistungsstarke Funktionen und eine benutzerfreundliche Benutzeroberfläche Mehrheit der Entwickler. Wenn PyCharm jedoch chinesische Zeichen verarbeitet, kann es manchmal zu verstümmelten Zeichen kommen, was zu bestimmten Problemen bei der Entwicklung und beim Debuggen führt. In diesem Artikel wird vorgestellt, wie das chinesische verstümmelte Problem in PyCharm gelöst werden kann, und es werden spezifische Codebeispiele gegeben. 1. Richten Sie das Projekt ein
 Häufige Ursachen und Lösungen für verstümmelte chinesische Zeichen bei der MySQL-Installation
Mar 02, 2024 am 09:00 AM
Häufige Ursachen und Lösungen für verstümmelte chinesische Zeichen bei der MySQL-Installation
Mar 02, 2024 am 09:00 AM
Häufige Gründe und Lösungen für verstümmelte chinesische Zeichen bei der MySQL-Installation MySQL ist ein häufig verwendetes relationales Datenbankverwaltungssystem. Bei der Verwendung kann es jedoch zu Problemen mit verstümmelten chinesischen Zeichen kommen, die Entwicklern und Systemadministratoren Probleme bereiten. Das Problem verstümmelter chinesischer Zeichen wird hauptsächlich durch falsche Zeichensatzeinstellungen, inkonsistente Zeichensätze zwischen dem Datenbankserver und dem Client usw. verursacht. In diesem Artikel werden die häufigsten Ursachen und Lösungen für verstümmelte chinesische Zeichen bei der MySQL-Installation ausführlich vorgestellt, um allen zu helfen, dieses Problem besser zu lösen. 1. Häufige Gründe: Zeichensatzeinstellung
 Knowledge Graph: der ideale Partner für große Modelle
Jan 29, 2024 am 09:21 AM
Knowledge Graph: der ideale Partner für große Modelle
Jan 29, 2024 am 09:21 AM
Große Sprachmodelle (LLMs) sind in der Lage, flüssige und kohärente Texte zu generieren, was neue Perspektiven für Bereiche wie Konversation mit künstlicher Intelligenz und kreatives Schreiben eröffnet. Allerdings weist LLM auch einige wesentliche Einschränkungen auf. Erstens beschränkt sich ihr Wissen auf Muster, die aus Trainingsdaten erkannt werden, und es mangelt ihnen an einem echten Verständnis der Welt. Zweitens sind die Denkfähigkeiten begrenzt und können keine logischen Schlussfolgerungen ziehen oder Fakten aus mehreren Datenquellen zusammenführen. Bei komplexeren und offeneren Fragen können die Antworten von LLM absurd oder widersprüchlich werden, was als „Illusionen“ bekannt ist. Obwohl LLM in einigen Aspekten sehr nützlich ist, weist es dennoch gewisse Einschränkungen bei der Bearbeitung komplexer Probleme und realer Situationen auf. Um diese Lücken zu schließen, sind in den letzten Jahren Retrieval-Augmented-Generation-Systeme (RAG) entstanden
 Was tun, wenn Ajax verstümmelte chinesische Zeichen überträgt?
Nov 15, 2023 am 10:42 AM
Was tun, wenn Ajax verstümmelte chinesische Zeichen überträgt?
Nov 15, 2023 am 10:42 AM
Lösungen für die Ajax-Übertragung verstümmelter chinesischer Zeichen: 1. Legen Sie eine einheitliche Codierungsmethode fest. 3. Clientseitige Decodierung. 5. Verwenden Sie das JSON-Format. Detaillierte Einführung: 1. Legen Sie eine einheitliche Codierungsmethode fest, um sicherzustellen, dass der Server und der Client dieselbe Codierungsmethode verwenden. Unter normalen Umständen ist UTF-8 eine häufig verwendete Codierungsmethode, da es mehrere Sprachen und Zeichensätze unterstützen kann. 2. Serverseitige Codierung: Stellen Sie sicher, dass die chinesischen Daten mit der richtigen Codierungsmethode codiert und dann an den Client usw. übergeben werden.
 Mehrere gängige Kodierungsmethoden
Oct 24, 2023 am 10:09 AM
Mehrere gängige Kodierungsmethoden
Oct 24, 2023 am 10:09 AM
Zu den gängigen Kodierungsmethoden gehören ASCII-Kodierung, Unicode-Kodierung, UTF-8-Kodierung, UTF-16-Kodierung, GBK-Kodierung usw. Ausführliche Einführung: 1. Die ASCII-Kodierung ist der früheste Zeichenkodierungsstandard und verwendet 7-Bit-Binärzahlen zur Darstellung von 128 Zeichen, einschließlich englischer Buchstaben, Zahlen, Satzzeichen, Steuerzeichen usw. 2. Die Unicode-Kodierung ist eine Methode zur Darstellung alle Zeichen der Welt Die Standardkodierungsmethode für Zeichen, die jedem Zeichen einen eindeutigen digitalen Codepunkt zuweist. 3. UTF-8-Kodierung usw.
