

正则截取html中的一段,该如何解决
Jun 13, 2016 am 11:45 AM
正则截取html中的一段
<br /><html><br /><body><br />.........<br />.........<br /><ul class="style5"><br /><li><a href="/profiles/83291221"><img src="/static/imghw/default1.png" data-src="/images/252754752" class="lazy" alt="标题标题" />标题标题</a></li><br /><li><a href="/profiles/83291221"><img src="/static/imghw/default1.png" data-src="/images/252754752" class="lazy" alt="标题标题" />标题标题</a></li><br /><li><a href="/profiles/83291221"><img src="/static/imghw/default1.png" data-src="/images/252754752" class="lazy" alt="标题标题" />标题标题</a></li><br /></ul><br />........<br />........<br /><br /></body><br /><br /></html><br /><br /><br />
这样的循环 我要截取第一条,多的不要
 标题标题
标题标题------解决方案--------------------
<br />preg_match_all("<br><font color='#FF8000'>------解决方案--------------------</font><br><li><a href=[\"\']\/(.*)\/(.*)[\"\']><img (.*) alt="正则截取html中的一段,该如何解决" >(.*)</a></li><br><font color='#FF8000'>------解决方案--------------------</font><br>U", $str, $out);<br />$a = $out[2][0];<br />$b = $out[4][0];<br />echo "a::$a , b::$b";<br />------解决方案--------------------
preg_match('#<ul class="style5">(.+?)</ul>#s',$s,$m);<br />preg_match('#<li><a href="/profiles/(\d+)"><img [^ alt="正则截取html中的一段,该如何解决" >]+>(.+?)</a></li>#s',$m[1],$ar);<br />print_r($ar);
Heißer Artikel

Hot-Tools-Tags

Heißer Artikel

Heiße Artikel -Tags

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Lösung: Ihre Organisation verlangt von Ihnen, dass Sie Ihre PIN ändern
Oct 04, 2023 pm 05:45 PM
Lösung: Ihre Organisation verlangt von Ihnen, dass Sie Ihre PIN ändern
Oct 04, 2023 pm 05:45 PM
Lösung: Ihre Organisation verlangt von Ihnen, dass Sie Ihre PIN ändern
 So passen Sie die Fensterrahmeneinstellungen unter Windows 11 an: Farbe und Größe ändern
Sep 22, 2023 am 11:37 AM
So passen Sie die Fensterrahmeneinstellungen unter Windows 11 an: Farbe und Größe ändern
Sep 22, 2023 am 11:37 AM
So passen Sie die Fensterrahmeneinstellungen unter Windows 11 an: Farbe und Größe ändern
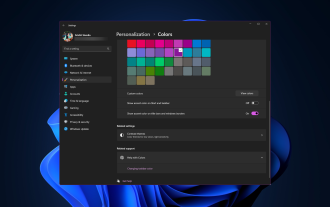 Wie ändere ich die Farbe der Titelleiste unter Windows 11?
Sep 14, 2023 pm 03:33 PM
Wie ändere ich die Farbe der Titelleiste unter Windows 11?
Sep 14, 2023 pm 03:33 PM
Wie ändere ich die Farbe der Titelleiste unter Windows 11?
 So aktivieren oder deaktivieren Sie die Vorschau von Miniaturansichten in der Taskleiste unter Windows 11
Sep 15, 2023 pm 03:57 PM
So aktivieren oder deaktivieren Sie die Vorschau von Miniaturansichten in der Taskleiste unter Windows 11
Sep 15, 2023 pm 03:57 PM
So aktivieren oder deaktivieren Sie die Vorschau von Miniaturansichten in der Taskleiste unter Windows 11
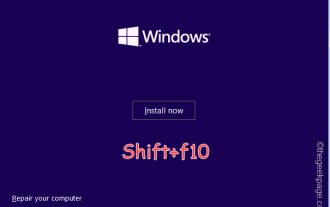 OOBELANGUAGE-Fehlerprobleme bei der Reparatur von Windows 11/10
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE-Fehlerprobleme bei der Reparatur von Windows 11/10
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE-Fehlerprobleme bei der Reparatur von Windows 11/10
 Was sind die Unterschiede zwischen Huawei GT3 Pro und GT4?
Dec 29, 2023 pm 02:27 PM
Was sind die Unterschiede zwischen Huawei GT3 Pro und GT4?
Dec 29, 2023 pm 02:27 PM
Was sind die Unterschiede zwischen Huawei GT3 Pro und GT4?
 Anleitung zur Anzeigeskalierung unter Windows 11
Sep 19, 2023 pm 06:45 PM
Anleitung zur Anzeigeskalierung unter Windows 11
Sep 19, 2023 pm 06:45 PM
Anleitung zur Anzeigeskalierung unter Windows 11
 10 Möglichkeiten, die Helligkeit unter Windows 11 anzupassen
Dec 18, 2023 pm 02:21 PM
10 Möglichkeiten, die Helligkeit unter Windows 11 anzupassen
Dec 18, 2023 pm 02:21 PM
10 Möglichkeiten, die Helligkeit unter Windows 11 anzupassen
