

理解Javascript_07_理解instanceof实现原理_javascript技巧

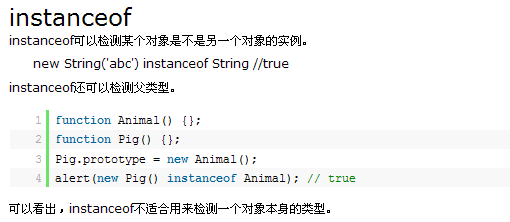
那么instanceof的这种行为到底是如何实现的呢,现在让我们揭开instanceof背后的迷雾。
instanceof原理
照惯例,我们先来看一段代码:
function Cat(){}
Cat.prototype = {}
function Dog(){}
Dog.prototype ={}
var dog1 = new Dog();
alert(dog1 instanceof Dog);//true
alert(dog1 instanceof Object);//true
Dog.prototype = Cat.prototype;
alert(dog1 instanceof Dog);//false
alert(dog1 instanceof Cat);//false
alert(dog1 instanceof Object);//true;
var dog2= new Dog();
alert(dog2 instanceof Dog);//true
alert(dog2 instanceof Cat);//true
alert(dog2 instanceof Object);//true
Dog.prototype = null;
var dog3 = new Dog();
alert(dog3 instanceof Cat);//false
alert(dog3 instanceof Object);//true
alert(dog3 instanceof Dog);//error
让我们画一张内存图来分析一下:
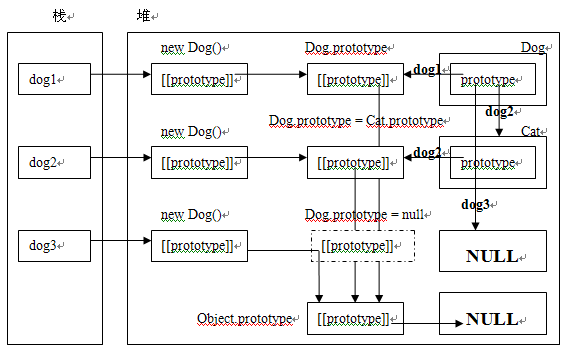
内存图比较复杂,解释一下:
程序本身是一个动态的概念,随着程序的执行,Dog.prototype会不断的改变。但是为了方便,我只画了一张图来表达这三次prototype引用的改变。在堆中,右边是函数对象的内存表示,中间的是函数对象的prototype属性的指向,左边的是函数对象创建的对象实例。其中函数对象指向prototype属性的指针上写了dog1,dog2,dog3分别对应Dog.prototype的三次引用改变。它们和栈中的dog1,dog2,dog3也有对应的关系。(注:关于函数对象将在后续博文中讲解)
来有一点要注意,就是dog3中函数对象的prototype属性为null,则函数对象实例dog3的内部[[prototype]]属性将指向Object.prototype,这一点在《理解Javascript_06_理解对象的创建过程》已经讲解过了。
结论
根据代码运行结果和内存结构,推导出结论:
instanceof 检测一个对象A是不是另一个对象B的实例的原理是:查看对象B的prototype指向的对象是否在对象A的[[prototype]]链上。如果在,则返回true,如果不在则返回false。不过有一个特殊的情况,当对象B的prototype为null将会报错(类似于空指针异常)。
这里推荐一篇文章,来自于岁月如歌,也是关于instanceof原理的,角度不同,但有异曲同工之妙。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1391
1391
 52
52

 Vertiefendes Verständnis des zugrunde liegenden Implementierungsmechanismus der Kafka-Nachrichtenwarteschlange
Feb 01, 2024 am 08:15 AM
Vertiefendes Verständnis des zugrunde liegenden Implementierungsmechanismus der Kafka-Nachrichtenwarteschlange
Feb 01, 2024 am 08:15 AM
Überblick über die zugrunde liegenden Implementierungsprinzipien der Kafka-Nachrichtenwarteschlange Kafka ist ein verteiltes, skalierbares Nachrichtenwarteschlangensystem, das große Datenmengen verarbeiten kann und einen hohen Durchsatz und eine geringe Latenz aufweist. Kafka wurde ursprünglich von LinkedIn entwickelt und ist heute ein Top-Level-Projekt der Apache Software Foundation. Architektur Kafka ist ein verteiltes System, das aus mehreren Servern besteht. Jeder Server wird als Knoten bezeichnet und jeder Knoten ist ein unabhängiger Prozess. Knoten werden über ein Netzwerk verbunden, um einen Cluster zu bilden. K
 Was macht die Instanz von?
Nov 14, 2023 pm 03:50 PM
Was macht die Instanz von?
Nov 14, 2023 pm 03:50 PM
Die Funktion von „instanceof“ besteht darin, zu bestimmen, ob ein Objekt eine Instanz einer bestimmten Klasse ist oder ob es eine Schnittstelle implementiert. Instanz von ist ein Operator, mit dem überprüft wird, ob ein Objekt von einem bestimmten Typ ist. Verwendungsszenarien des Instanzoperators: 1. Typprüfung: Kann verwendet werden, um den spezifischen Typ eines Objekts zu bestimmen, um je nach Typ unterschiedliche Logik auszuführen. 2. Schnittstellenbeurteilung: Kann verwendet werden, um festzustellen, ob ein Objekt eine Schnittstelle implementiert , um zu bestimmen, ob ein Objekt eine Schnittstelle implementiert. 3. Abwärtstransformation usw.
 Detaillierte Erläuterung des Betriebsmechanismus und der Implementierungsprinzipien des PHP-Kerns
Nov 08, 2023 pm 01:15 PM
Detaillierte Erläuterung des Betriebsmechanismus und der Implementierungsprinzipien des PHP-Kerns
Nov 08, 2023 pm 01:15 PM
PHP ist eine beliebte serverseitige Open-Source-Skriptsprache, die häufig für die Webentwicklung verwendet wird. Es kann dynamische Daten verarbeiten und die HTML-Ausgabe steuern, aber wie erreicht man das? Anschließend stellt dieser Artikel den Kernbetriebsmechanismus und die Implementierungsprinzipien von PHP vor und verwendet spezifische Codebeispiele, um den Betriebsprozess weiter zu veranschaulichen. PHP-Quellcode-Interpretation PHP-Quellcode ist ein in der Sprache C geschriebenes Programm. Nach der Kompilierung wird die ausführbare Datei php.exe generiert. Für PHP, das in der Webentwicklung verwendet wird, wird es im Allgemeinen über A ausgeführt
 Implementierungsprinzip des Partikelschwarmalgorithmus in PHP
Jul 10, 2023 pm 11:03 PM
Implementierungsprinzip des Partikelschwarmalgorithmus in PHP
Jul 10, 2023 pm 11:03 PM
Prinzip der Implementierung der Partikelschwarmoptimierung in PHP Die Partikelschwarmoptimierung (PSO) ist ein Optimierungsalgorithmus, der häufig zur Lösung komplexer nichtlinearer Probleme verwendet wird. Es simuliert das Futtersuchverhalten eines Vogelschwarms, um die optimale Lösung zu finden. In PHP können wir den PSO-Algorithmus verwenden, um Probleme schnell zu lösen. In diesem Artikel werden das Implementierungsprinzip und entsprechende Codebeispiele vorgestellt. Grundprinzip der Partikelschwarmoptimierung Das Grundprinzip des Partikelschwarmalgorithmus besteht darin, die optimale Lösung durch iterative Suche zu finden. Der Algorithmus enthält eine Gruppe von Partikeln
 Eingehende Analyse der technischen Prinzipien und anwendbaren Szenarien der Kafka-Nachrichtenwarteschlange
Feb 01, 2024 am 08:34 AM
Eingehende Analyse der technischen Prinzipien und anwendbaren Szenarien der Kafka-Nachrichtenwarteschlange
Feb 01, 2024 am 08:34 AM
Das Implementierungsprinzip der Kafka-Nachrichtenwarteschlange Kafka ist ein verteiltes Publish-Subscribe-Messagingsystem, das große Datenmengen verarbeiten kann und eine hohe Zuverlässigkeit und Skalierbarkeit aufweist. Das Implementierungsprinzip von Kafka lautet wie folgt: 1. Themen und Partitionen Daten in Kafka werden in Themen gespeichert, und jedes Thema kann in mehrere Partitionen unterteilt werden. Eine Partition ist die kleinste Speichereinheit in Kafka, bei der es sich um eine geordnete, unveränderliche Protokolldatei handelt. Produzenten schreiben Daten zu Themen und Konsumenten lesen daraus
 Analysieren Sie das Implementierungsprinzip der asynchronen Aufgabenverarbeitungsfunktion von swoole
Aug 05, 2023 pm 04:15 PM
Analysieren Sie das Implementierungsprinzip der asynchronen Aufgabenverarbeitungsfunktion von swoole
Aug 05, 2023 pm 04:15 PM
Analysieren Sie das Implementierungsprinzip der asynchronen Aufgabenverarbeitungsfunktion von swoole. Mit der rasanten Entwicklung der Internettechnologie ist die Verarbeitung verschiedener Probleme immer komplexer geworden. In der Webentwicklung ist die Bewältigung einer großen Anzahl an Anfragen und Aufgaben eine häufige Herausforderung. Die herkömmliche synchrone Blockierungsmethode kann die Anforderungen einer hohen Parallelität nicht erfüllen, sodass die asynchrone Aufgabenverarbeitung eine Lösung darstellt. Als PHP-Coroutine-Netzwerk-Framework bietet Swoole leistungsstarke asynchrone Aufgabenverarbeitungsfunktionen. In diesem Artikel wird das Implementierungsprinzip anhand eines einfachen Beispiels analysiert. Bevor wir beginnen, müssen wir sicherstellen, dass dies der Fall ist
 Beherrschen Sie den zugrunde liegenden Arbeitsmechanismus der Tomcat-Middleware
Dec 28, 2023 pm 05:25 PM
Beherrschen Sie den zugrunde liegenden Arbeitsmechanismus der Tomcat-Middleware
Dec 28, 2023 pm 05:25 PM
Um die zugrunde liegenden Implementierungsprinzipien der Tomcat-Middleware zu verstehen, benötigen Sie spezifische Codebeispiele. Tomcat ist ein weit verbreiteter Open-Source-Java-Webserver und Servlet-Container. Es ist hoch skalierbar und flexibel und wird häufig zum Bereitstellen und Ausführen von Java-Webanwendungen verwendet. Um die zugrunde liegenden Implementierungsprinzipien der Tomcat-Middleware besser zu verstehen, müssen wir ihre Kernkomponenten und Betriebsmechanismen untersuchen. In diesem Artikel werden die zugrunde liegenden Implementierungsprinzipien der Tomcat-Middleware anhand spezifischer Codebeispiele analysiert. Tom
 Das Prinzip der Java-Crawler-Technologie: Detaillierte Analyse des Crawling-Prozesses für Webseitendaten
Jan 09, 2024 pm 02:46 PM
Das Prinzip der Java-Crawler-Technologie: Detaillierte Analyse des Crawling-Prozesses für Webseitendaten
Jan 09, 2024 pm 02:46 PM
Eingehende Analyse der Java-Crawler-Technologie: Implementierungsprinzipien des Crawlens von Webseitendaten Einführung: Mit der rasanten Entwicklung des Internets und dem explosionsartigen Wachstum von Informationen werden große Datenmengen auf verschiedenen Webseiten gespeichert. Diese Webseitendaten sind für uns sehr wichtig, um Informationsextraktion, Datenanalyse und Geschäftsentwicklung durchzuführen. Die Java-Crawler-Technologie ist eine häufig verwendete Methode zum Crawlen von Webseitendaten. In diesem Artikel werden die Implementierungsprinzipien der Java-Crawler-Technologie ausführlich analysiert und spezifische Codebeispiele bereitgestellt. 1. Was ist Crawler-Technologie? Crawler-Technologie (WebCrawling) wird auch Web-Crawler-Technologie genannt.
