

PHP 资料缓存数组的实现

PHP 文件缓存数组的实现
在一个试验性项目中,我需要从 sqlite3 数据库中随机读取一条记录给用户,要读取的数据表现在有23850条记录,按 skemu 分类,一般每个 skemu 下有 3000多条记录,原先我使用了 sqlite3 的随机查询语句:
$query="SELECT * FROM shiti WHERE skemu = " . intval($kemuid) . " order by random() limit 1";
然后在我现在用的电脑上没有感觉到明显迟延,但当我把服务器换到一个 P4 1.8G 512M内存的机器上运行时,感觉数据读取速度非常慢,需要2、3秒才能读出数据。如果每次用户要取一条随机记录,都执行这样一个随机查询的话,瓶颈将会出现在数据库查询过程中,难以想像这样的性能如何来适应众多用户的同时访问。为此,我考虑减少数据库的查询次数,先把记录 id 取出来放到数组中,然后从中再来随机取一条记录,同时存为文件供以后读取,这样以减少数据库查询的次数。
以下函数实现读出 id 集:
static function getIDs($kemuid)
{
$cachefile="cache/" . $kemuid . ".cache";
$datas=array();
if (!file_exists($cachefile)||time() < (filemtime($cachefile) + 14400))
//缓存不存在或超过4小时
{
global $data;
//读取 id 集
$query="SELECT sid FROM shiti WHERE skemu = " . intval($kemuid);
$res = $data->query($query);
while($r = $data->fetchArray($res))
{
$datas[]=$r['sid'];
}
//写入缓存
file_put_contents($cachefile,serialize($datas));
}
else
{
//读出缓存
$fp = fopen($cachefile,'r');//读
$datas = unserialize(fread($fp,filesize($cachefile)));//反序列化,并赋值
}
return $datas;
}
<span style="font-family:Arial"><span style="color:#548dd4"><span style="color:#366092">调用它的读取随机记录函数:</span></span></span>
static function getRondam($kemuid)
{
global $data;
$ids=self::getIDs($kemuid);
$index=rand(0,count($ids)-1);
$id=$ids[$index];
$query="SELECT * FROM shiti WHERE sid = " . intval($id);
$res = $data->query($query);
$r = $data->fetchArray($res);
$r['da']=$s;
return $r;
}
<span style="font-family:Arial">这样比每次执行随机查询快多了,但是还是要比生成一个HTML缓存要慢一点,但那样需要把更多数据暴露给客户端,或是存储更多缓存,我想这已经是一个比较均衡的方案了。</span>
<span style="font-family:Arial"></span>
<span style="font-family:Arial">这个解决办法的要点在于数组的序列化与反序列化,大家应该很容易看得懂。</span>

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

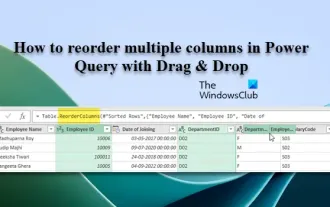 So ordnen Sie mehrere Spalten in Power Query per Drag & Drop neu an
Mar 14, 2024 am 10:55 AM
So ordnen Sie mehrere Spalten in Power Query per Drag & Drop neu an
Mar 14, 2024 am 10:55 AM
In diesem Artikel zeigen wir Ihnen, wie Sie mehrere Spalten in PowerQuery per Drag & Drop neu anordnen. Beim Importieren von Daten aus verschiedenen Quellen kann es vorkommen, dass die Spalten nicht in der gewünschten Reihenfolge vorliegen. Durch die Neuordnung von Spalten können Sie diese nicht nur in einer logischen Reihenfolge anordnen, die Ihren Analyse- oder Berichtsanforderungen entspricht, sondern verbessert auch die Lesbarkeit Ihrer Daten und beschleunigt Aufgaben wie Filtern, Sortieren und Durchführen von Berechnungen. Wie ordne ich mehrere Spalten in Excel neu an? Es gibt viele Möglichkeiten, Spalten in Excel neu anzuordnen. Sie können einfach die Spaltenüberschrift auswählen und an die gewünschte Stelle ziehen. Dieser Ansatz kann jedoch umständlich werden, wenn es um große Tabellen mit vielen Spalten geht. Um Spalten effizienter neu anzuordnen, können Sie den erweiterten Abfrageeditor verwenden. Erweiterung der Abfrage
 React Query-Datenbank-Plug-in: So importieren und exportieren Sie Daten
Sep 26, 2023 pm 05:37 PM
React Query-Datenbank-Plug-in: So importieren und exportieren Sie Daten
Sep 26, 2023 pm 05:37 PM
ReactQuery-Datenbank-Plug-in: Methoden zum Implementieren des Datenimports und -exports, spezifische Codebeispiele sind erforderlich. Mit der weit verbreiteten Anwendung von ReactQuery in der Front-End-Entwicklung beginnen immer mehr Entwickler, es zur Datenverwaltung zu verwenden. In der tatsächlichen Entwicklung müssen wir häufig Daten in lokale Dateien exportieren oder Daten aus lokalen Dateien in die Datenbank importieren. Um diese Funktionen komfortabler umzusetzen, können Sie das ReactQuery-Datenbank-Plugin verwenden. Das ReactQuery-Datenbank-Plugin bietet eine Reihe von Methoden
 php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出php提交表单通过后,弹出的对话框怎样在当前页弹出而不是在空白页弹出?想实现这样的效果:而不是空白页弹出:------解决方案--------------------如果你的验证用PHP在后端,那么就用Ajax;仅供参考:HTML code
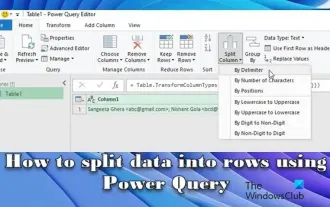 So teilen Sie Daten mithilfe von Power Query in NTFS auf
Mar 15, 2024 am 11:00 AM
So teilen Sie Daten mithilfe von Power Query in NTFS auf
Mar 15, 2024 am 11:00 AM
In diesem Artikel wird erläutert, wie Sie PowerQuery zum Aufteilen von Daten in Zeilen verwenden. Beim Exportieren von Daten aus anderen Systemen oder Quellen kommt es häufig vor, dass die Daten in Zellen gespeichert werden, die mehrere Werte kombinieren. Mit PowerQuery können wir solche Daten einfach in Zeilen aufteilen, wodurch die Daten einfacher zu verarbeiten und zu analysieren sind. Dies kann passieren, wenn der Benutzer die Excel-Regeln nicht versteht und versehentlich mehrere Daten in eine Zelle eingibt oder wenn die Daten beim Kopieren/Einfügen aus anderen Quellen nicht richtig formatiert sind. Die Verarbeitung dieser Daten erfordert zusätzliche Schritte zum Extrahieren und Organisieren der Informationen für die Analyse oder Berichterstellung. Wie teilt man Daten in PowerQuery auf? PowerQuery-Transformationen können auf einer Vielzahl verschiedener Faktoren wie Word basieren
 Welche Daten befinden sich im Datenordner?
May 05, 2023 pm 04:30 PM
Welche Daten befinden sich im Datenordner?
May 05, 2023 pm 04:30 PM
Der Datenordner enthält System- und Programmdaten, wie z. B. Softwareeinstellungen und Installationspakete. Jeder Ordner im Datenordner stellt einen anderen Typ von Datenspeicherordner dar, unabhängig davon, ob sich die Datendatei auf den Dateinamen „Data“ oder die Dateierweiterung „Benannte Daten“ bezieht Es handelt sich bei allen um vom System oder Programm angepasste Datendateien. Daten sind eine Sicherungsdatei zur Datenspeicherung, die im Allgemeinen mit Meidaplayer, Notepad oder Word geöffnet werden kann.
 Abfrageabsichtserkennung basierend auf Wissenserweiterung und vorab trainiertem großem Modell
May 19, 2023 pm 02:01 PM
Abfrageabsichtserkennung basierend auf Wissenserweiterung und vorab trainiertem großem Modell
May 19, 2023 pm 02:01 PM
1. Einführung in den Hintergrund Die Digitalisierung von Unternehmen ist in den letzten Jahren ein heißes Thema. Sie bezieht sich auf den Einsatz digitaler Technologien der neuen Generation wie künstliche Intelligenz, Big Data und Cloud Computing, um das Geschäftsmodell von Unternehmen zu verändern und so neues Wachstum im Unternehmensgeschäft zu fördern . Die Unternehmensdigitalisierung umfasst im Allgemeinen die Digitalisierung des Geschäftsbetriebs und die Digitalisierung der Unternehmensführung. Diese gemeinsame Nutzung führt hauptsächlich die Digitalisierung der Unternehmensführungsebene ein. Vereinfacht ausgedrückt bedeutet Informationsdigitalisierung das Lesen, Schreiben, Speichern und Übertragen von Informationen auf digitale Weise. Von den früheren Papierdokumenten bis hin zu den aktuellen elektronischen Dokumenten und Online-Zusammenarbeitsdokumenten ist die Informationsdigitalisierung im heutigen Büro zur neuen Normalität geworden. Derzeit nutzt Alibaba DingTalk Documents und Yuque Documents für die geschäftliche Zusammenarbeit, und die Zahl der Online-Dokumente hat mehr als 20 Millionen erreicht. Darüber hinaus werden viele Unternehmen dies intern tun
 Was tun, wenn die MySQL-Ladedaten verstümmelt sind?
Feb 16, 2023 am 10:37 AM
Was tun, wenn die MySQL-Ladedaten verstümmelt sind?
Feb 16, 2023 am 10:37 AM
Die Lösung für die verstümmelten MySQL-Ladedaten: 1. Suchen Sie die SQL-Anweisung mit verstümmelten Zeichen. 2. Ändern Sie die Anweisung in „LOAD DATA LOCAL INFILE „employee.txt“ INTO TABLE EMPLOYEE Zeichensatz utf8;“.
 Was sind die Unterschiede zwischen xdata und data
Dec 11, 2023 am 11:30 AM
Was sind die Unterschiede zwischen xdata und data
Dec 11, 2023 am 11:30 AM
Die Unterschiede sind: 1. xdata bezieht sich normalerweise auf unabhängige Variablen, während sich data auf den gesamten Datensatz bezieht. 2. xdata wird hauptsächlich zum Erstellen von Datenanalysemodellen verwendet, während Daten normalerweise für Datenanalysen und Statistiken verwendet werden Für die Regressionsanalyse, Varianzanalyse und Vorhersagemodellierung können Daten mit verschiedenen statistischen Methoden analysiert werden. 4. xdata erfordert normalerweise eine Datenvorverarbeitung und Daten können vollständige Originaldaten enthalten.
