

node.js verwendet Cluster, um multi-process_node.js zu implementieren

Zunächst erkläre ich feierlich:
nodeJS ist eine Single-Threaded-Sprache!
nodeJS ist eine Single-Threaded-Sprache!
nodeJS ist eine Single-Threaded-Sprache!
Sagen Sie wichtige Dinge dreimal. Da NodeJS mit seinen eigenen Fähigkeiten geboren wird, ist es seit seiner Geburt bei Tausenden von Fans begehrt (ich bin auch sein eingefleischter Fan). Der dumme PHP hat jedoch tatsächlich über meine Leistung von NodeJS gelacht. Es gilt als instabil und unzuverlässig und kann nur eine Single-Core-CPU verwenden. Hot Chicken NodeJS
Scheiße! Scheiße!
Do mo shi~
Aber der große Bruder ist der große Bruder, nodeJS hat das Clustermodul bereits in Version 0.8 hinzugefügt. Es ist zwar ein Schlag ins Gesicht von PHP, obwohl PHP auch damit begonnen hat, NodeJS zu kopieren und PHP7 zu beenden, aber Dreckskerl, du wirst nur kopieren...
233333
Entschuldigung, das Obige ist ein Absatz meiner eigenen Obszönität ~ Der obige Inhalt ist ein reiner Scherz und jede Ähnlichkeit ist rein zufällig.
Ok~ Lassen Sie uns den Multiprozess von nodeJS~ offiziell vorstellen
In der Vergangenheit war die Implementierungsleistung aufgrund der Unvollkommenheit des Clusters selbst, möglicherweise aus verschiedenen Gründen, nicht gut. Das Ergebnis war der Aufstieg des pm2-Pakets. Mit einem pm2 können Sie ganz einfach mehrere Prozesse starten, um einen Lastausgleich zu erreichen.
Die interne Implementierung von pm2 und die interne Implementierung von Cluster sind tatsächlich identisch. Sie kapseln beide eine Schicht von child_process--fork. Und child_process--fork kapselt die Fork-Methode des Unix-Systems. Da wir nun hier sind, werfen wir einen Blick auf die offizielle Erklärung.
pm2 start app.js
Lassen Sie mich übersetzen: Fork ist eigentlich eine Methode zum Erstellen eines untergeordneten Prozesses. Der neu erstellte Prozess wird als untergeordneter Prozess betrachtet, und der Prozess, der fork aufruft, ist der übergeordnete Prozess. Der untergeordnete Prozess und der übergeordnete Prozess befinden sich ursprünglich in unabhängigen Speicherräumen. Wenn Sie jedoch eine Gabel verwenden, befinden sich beide im selben Bereich. Das Lesen und Schreiben des Speichers sowie die Dateizuordnung wirken sich jedoch nicht gegenseitig aus.
fork() creates a new process by duplicating the calling process. The new process is referred to as the child process. The calling process is referred to as the parent process. The child process and the parent process run in separate memory spaces. At the time of fork() both memory spaces have the same content. Memory writes, file mappings (mmap(2)), and unmappings (munmap(2)) performed by one of the processes do not affect the other.
Sehen Sie sich das Bild an~~~
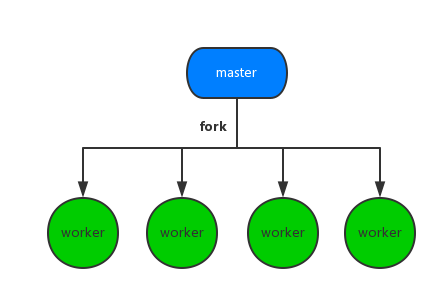
Es ist sehr einfach, den Port zu überwachen. . .
Es ist jedoch nicht schwierig, die Kommunikation zu implementieren. Der Schlüssel liegt in der Zuweisung von Anforderungen. Dies ist eine große Falle für nodeJS.
vor langer Zeit
Der Meister von nodeJS war am Anfang nur ein kleiner Eunuch. Jedes Mal, wenn er (eine Konkubine) darum bat, zu kommen, sah er einfach schweigend zu, wie mehrere Arbeiter und kleine Kaiser miteinander konkurrierten gewonnen, Dann kümmern sich andere Arbeiter einfach um sich selbst und warten auf die nächste Anfrage. Daher wird jedes Mal, wenn eine Anfrage kommt, ein blutiger Sturm ausgelöst. Was wir jedoch am meisten erlebt haben, ist das Phänomen der donnernden Herde, das heißt, die CPU platzt.Ich werde ein Bild von Meister TJ verwenden, um es zu erklären.
Hier bindet der Master nur den Port und führt keine Verarbeitung für eingehende Anfragen durch. Durch Übergabe des fd des Sockets an den geforkten Prozess. Das Ergebnis war, dass vier Männer (Arbeiter) eine Konkubine ausraubten (Ganz zu schweigen davon, wie blutig die Szene war). 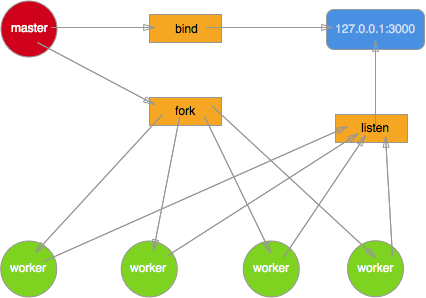
Dies sollte das Kernmodul des NodeJS-Prozesses sein. Es gibt mehrere grundlegende Methoden, aber hier werde ich nur die Kernmethoden vorstellen: Spawn, Fork und Exec. Wenn Sie interessiert sind, können Sie als Referenz zu child_process gehen. child_process.spawn(command, args)
Diese Methode wird verwendet, um das angegebene Programm auszuführen. Zum Beispiel:
Es handelt sich um einen asynchronen Befehl, der jedoch keinen Rückruf unterstützt. Wir können jedoch „process.on“ verwenden, um die Ergebnisse zu überwachen. Es verfügt über 3 Parameter.
Befehl: Befehl ausführennode app.js
args[Array]: vom Befehl getragene Parameter
Optionen[Objekt]: Umgebungsvariablenobjekt
OK~ Geben wir eine einfache Demo: Versuchen Sie es auszuführen
touch apawn.js
const spawn = require('child_process').spawn;
const touch = spawn('touch',['spawn.js']);
touch.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
touch.stderr.on('data', (data) => {
console.log(`stderr: ${data}`);
});
touch.on('close', (code) => {
console.log(`child process exited with code $[code]`);
});
child_process.exec(order,cb(err[,stdout,stderr]));child process exited with code 0
Reihenfolge: ist der Befehl, den Sie ausführen. Zum Beispiel:
cb: ist die Rückruffunktion, nachdem der Befehl erfolgreich ausgeführt wurde.
rm spawn.js
正常情况下会删除spawn.js文件。
上面两个只是简单的运行进程的命令。 最后,(Boss总是最后出场的). 我们来瞧瞧fork方法的使用.
fork其实也是用来执行进程,比如,spawn("node",['app.js']),其实和fork('app.js') 是一样的效果的。但是,fork牛逼的地方在于他在开启一个子进程时,同时建立了一个信息通道(双工的哦). 俩个进程之间使用process.on("message",fn)和process.send(...)进行信息的交流.
child_process.fork(order) //创建子进程
worker.on('message',cb) //监听message事件
worker.send(mes) //发送信息
他和spawn类似都是通过返回的通道进行通信。举一个demo, 两个文件master.js和worker.js 来看一下.
//master.js
const childProcess = require('child_process');
const worker = childProcess.fork('worker.js');
worker.on('message',function(mes){
console.log(`from worder, message: ${mes}`);
});
worker.send("this is master");
//worker.js
process.on('message',function(mes){
console.log(`from master, message: ${mes}`);
});
process.send("this is worker");运行,node app.js, 会输出一下结果:
from master, message: this is master from worker, message: this is worker
现在我们已经学会了,如何使用child_process来创建一个基本的进程了。
关于net 这一模块,大家可以参考一下net模块.
ok . 现在我们正式进入,模拟nodeJS cluster模块通信的procedure了。
out of date 的cluster
这里先介绍一下,曾经的cluster实现的一套机理。同样,再放一次图
我们使用net和child_process来模仿一下。
//master.js
const net = require('net');
const fork = require('child_process').fork;
var handle = net._createServerHandle('0.0.0.0', 3000);
for(var i=0;i<4;i++) {
fork('./worker').send({}, handle);
}
//worker.js
const net = require('net');
//监听master发送过来的信息
process.on('message', function(m, handle) {
start(handle);
});
var buf = 'hello nodejs'; ///返回信息
var res = ['HTTP/1.1 200 OK','content-length:'+buf.length].join('\r\n')+'\r\n\r\n'+buf; //嵌套字
function start(server) {
server.listen();
var num=0;
//监听connection函数
server.onconnection = function(err,handle) {
num++;
console.log(`worker[${process.pid}]:${num}`);
var socket = new net.Socket({
handle: handle
});
socket.readable = socket.writable = true;
socket.end(res);
}
}ok~ 我们运行一下程序, 首先运行node master.js.
然后使用测试工具,siege.
siege -c 100 -r 2 http://localhost:3000
OK,我们看一下,到底此时的负载是否均衡。
worker[1182]:52 worker[1183]:42 worker[1184]:90 worker[1181]:16
发现,这样任由worker去争夺请求,效率真的很低呀。每一次,触发请求,都有可能导致惊群事件的发生啊喂。所以,后来cluster改变了一种模式,使用master来控制请求的分配,官方给出的算法其实就是round-robin 轮转方法。
高富帅版cluster
现在具体的实现模型就变成这个.

由master来控制请求的给予。通过监听端口,创建一个socket,将获得的请求传递给子进程。
从tj大神那里借鉴的代码demo:
//master
const net = require('net');
const fork = require('child_process').fork;
var workers = [];
for (var i = 0; i < 4; i++) {
workers.push(fork('./worker'));
}
var handle = net._createServerHandle('0.0.0.0', 3000);
handle.listen();
//将监听事件移到master中
handle.onconnection = function (err,handle) {
var worker = workers.pop(); //取出一个pop
worker.send({},handle);
workers.unshift(worker); //再放回取出的pop
}
//worker.js
const net = require('net');
process.on('message', function (m, handle) {
start(handle);
});
var buf = 'hello Node.js';
var res = ['HTTP/1.1 200 OK','content-length:'+buf.length].join('\r\n')+'\r\n\r\n'+buf;
function start(handle) {
console.log('got a connection on worker, pid = %d', process.pid);
var socket = new net.Socket({
handle: handle
});
socket.readable = socket.writable = true;
socket.end(res);
}这里就经由master来掌控全局了. 当一个皇帝(worker)正在宠幸妃子的时候,master就会安排剩下的几个皇帝排队一个几个的来。 其实中间的handle就会我们具体的业务逻辑. 如同:app.js.
ok~ 我们再来看一下cluster模块实现多进程的具体写法.
cluster模块实现多进程
现在的cluster已经可以说完全做到的负载均衡。在cluster说明我已经做了阐述了。我们来看一下具体的实现吧
var cluster = require('cluster');
var http = require('http');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log('[master] ' + "start master...");
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('listening', function (worker, address) {
console.log('[master] ' + 'listening: worker' + worker.id + ',pid:' + worker.process.pid + ', Address:' + address.address + ":" + address.port);
});
} else if (cluster.isWorker) {
console.log('[worker] ' + "start worker ..." + cluster.worker.id);
var num = 0;
http.createServer(function (req, res) {
num++;
console.log('worker'+cluster.worker.id+":"+num);
res.end('worker'+cluster.worker.id+',PID:'+process.pid);
}).listen(3000);
}这里使用的是HTTP模块,当然,完全也可以替换为socket模块. 不过由于这样书写,将集群和单边给混淆了。 所以,推荐写法是将具体业务逻辑独立出来.
var cluster = require('cluster');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log('[master] ' + "start master...");
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('listening', function (worker, address) {
console.log('[master] ' + 'listening: worker' + worker.id + ',pid:' + worker.process.pid + ', Address:' + address.address + ":" + address.port);
});
} else if (cluster.isWorker) {
require('app.js');
}
//app.js就是开启具体的业务逻辑了
//app.js具体内容
const net = require('net');
//自动创建socket
const server = net.createServer(function(socket) { //'connection' listener
socket.on('end', function() {
console.log('server disconnected');
});
socket.on('data', function() {
socket.end('hello\r\n');
});
});
//开启端口的监听
server.listen(8124, function() { //'listening' listener
console.log('working')
});接着我们开启服务,node master.js
然后进行测试
siege -c 100 -r 2 http://localhost:8124
我这里开启的是长连接. 每个worker处理的长连接数是有限的。所以,当有额外的连接到来时,worker会断开当前没有响应的连接,去处理新的连接。
不过,平常我们都是使用HTTP开启 短连接,快速处理大并发的请求。
这是我改成HTTP短连接之后的结果
Transactions: 200 hits Availability: 100.00 % Elapsed time: 2.09 secs Data transferred: 0.00 MB Response time: 0.02 secs Transaction rate: 95.69 trans/sec Throughput: 0.00 MB/sec Concurrency: 1.74 Successful transactions: 200 Failed transactions: 0 Longest transaction: 0.05 Shortest transaction: 0.02
那,怎么模拟大并发嘞?
e e e e e e e e e ...
自己解决啊~
开玩笑的啦~ 不然我写blog是为了什么呢? 就是为了传播知识.
在介绍工具之前,我想先说几个关于性能的基本概念
QPS(TPS),并发数,响应时间,吞吐量,吞吐率
你母鸡的性能测试theories
自从我们和服务器扯上关系后,我们前端的性能测试真的很多。但这也是我们必须掌握的tip. 本来前端宝宝只需要看看控制台,了解一下网页运行是否运行顺畅, 看看TimeLine,Profile 就可以了。 不过,作为一名有追求,有志于改变世界的童鞋来说。。。
md~ 又要学了...
ok~ 好了,在进入正题之前,我再放一次 线上的测试结果.
Transactions: 200 hits Availability: 100.00 % Elapsed time: 13.46 secs Data transferred: 0.15 MB Response time: 3.64 secs Transaction rate: 14.86 trans/sec Throughput: 0.01 MB/sec Concurrency: 54.15 Successful transactions: 200 Failed transactions: 0 Longest transaction: 11.27 Shortest transaction: 0.01
根据上面的数据,就可以得出,你网页的大致性能了。
恩~ let's begin
吞吐率
关于吞吐率有多种解读,一种是:描绘web服务器单位时间处理请求的能力。根据这个描述,其单位就为: req/sec. 另一种是: 单位时间内网络上传输的数据量。 而根据这个描述的话,他的单位就为: MB/sec.
而这个指标就是上面数据中的Throughput. 当然,肯定是越大越好了
吞吐量
这个和上面的吞吐率很有点关系的。 吞吐量是在没有时间的限制下,你一次测试的传输数据总和。 所以,没有时间条件的测试,都是耍流氓。
这个对应于上面数据中的Data transferred.
事务 && TPS
熟悉数据库操作的童鞋,应该知道,在数据库中常常会提到一个叫做事务的概念。 在数据库中,一个事务,常常代表着一个具体的处理流程和结果. 比如,我现在想要的数据是 2013-2015年,数学期末考试成绩排名. 这个就是一个具体的事务,那么我们映射到数据库中就是,取出2013-2015年的排名,然后取平均值,返回最后的排序结果。 可以看出,事务并不单单指单一的操作,他是由一个或一个以上 操作组合而成具有 实际意义的。 那,反映到前端测试,我们应该怎样去定义呢? 首先,我们需要了解,前端的网络交流其实就是 请求-响应模式. 也就是说,每一次请求,我们都可以理解为一次事务(trans).
所以,TPS(transaction per second)就可以理解为1sec内,系统能够处理的请求数目.他的单位也就是: trans/sec . 你当然也可以理解为seq/sec.
所以说,TPS 应该是衡量一个系统承载力最优的一个标识.
TPS的计算公式很容易的出来就是: Transactions / Elapsed time.
不过, 凡事无绝对。 大家以后遇到测试的时候,应该就会知道的.
并发数
就是服务器能够并发处理的连接数,具体我也母鸡他的单位是什么。 官方给出的解释是:
Concurrency is average number of simultaneous connections, a number which rises as server performance decreases.
这里我们就理解为,这就是一个衡量系统的承载力的一个标准吧。 当Concurrency 越高,表示 系统承载的越多,但性能也越低。
ok~ 但是我们如何利用这些数据,来确定我们的并发策略呢? e e e e e e e ...
当然, 一两次测试的结果真的没有什么卵用. 所以实际上,我们需要进行多次测试,然后画图才行。 当然,一些大公司,早就有一套完整的系统来计算你web服务器的瓶颈,以及 给出 最优的并发策略.
废话不多说,我们来看看,如何分析,才能得出 比较好的 并发策略。
探究并发策略
首先,我们这里的并发需要进行区分. 一个是并发的请求数,一个是并发的用户数. 这两个对于服务器是完全不同的需求。
假如100个用户同时向服务器分别进行10次请求,与1个用户向服务器连续进行1000次请求。两个的效果一样么?
一个用户向服务器连续进行1000次请求的过程中,任何时刻服务器的网卡接受缓存区中只有来自该用户的1个请求,而100个用户同时向服务器分别进行10次请求的过程中,服务器网卡接收缓冲区中最多有100个等待处理的请求,显然这时候服务器的压力更大。
所以上面所说的 并发用户数和吞吐率 是完全不一样的.
不过通常来说,我们更看重的是Concurrency(并发用户数). 因为这样更能反映出系统的 能力。 一般,我们都会对并发用户数进行一些限制,比如apache的maxClients参数.
ok~ 我们来实例分析一下吧.
首先,我们拿到一份测试数据.
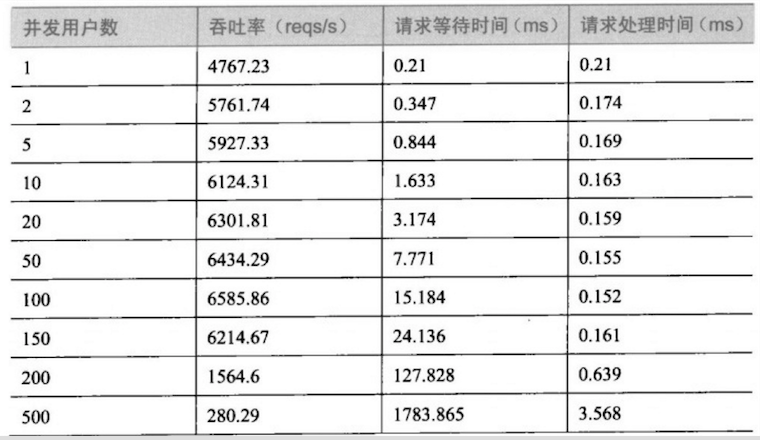
接着,我们进行数据分析.
根据并发数和吞吐率的关系得出下列的图.
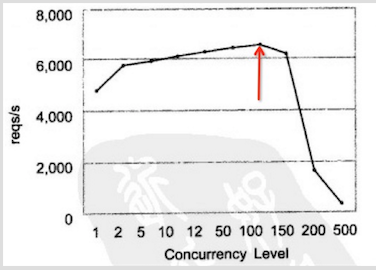
OK~ 我们会发现从大约130并发数的地方开始,吞吐率开始下降,而且越多下降的越厉害。 主要是因为,在前面部分随着用户数的上升,空闲的系统资源得到充分的利用,当然就和正太曲线一样,总会有个顶点。 当到达一定值后,顶点就会出现了. 这就我们的系统的一个瓶颈.
接着,我们细化分析,响应时间和并发用户数的相关性

同样额道理,当并发数到达130左右,正对每个req的响应时间开始增加,越大越抖,这适合吞吐率是相关的。 所以,我们可以得出一个结论,该次连接 并发数 最好设置为100~150之间。 当然,这样的分析很肤浅,不过,对于我们这些前端宝宝来说了解一下就足够了。
接下来,我们使用工具来武装自己的头脑.
这里主要介绍一个测试工具,siege.
并发测试工具
事实上并发测试工具主要有3个siege,ab,还有webbench. 我这里之所以没介绍webbench的原因,因为,我在尝试安装他时,老子,电脑差点就挂了(我的MAC pro)... 不过后面,被聪明的我 巧妙的挽回~ 所以,如果有其他大神在MAC x11 上成功安装,可以私信小弟。让我学习学习。
ok~ 吐槽完了。我们正式说一下siege吧
siege
安装siege利用MAC神器 homebrew, 就是就和js前端世界的npm一样.
安装ing:
brew install siege
安装成功--bingo
接着,我们来看一下语法吧.
-c NUM 设置并发的用户数量.eg: -c 100;
-r NUM 设置发送几轮的请求,即,总的请求数为: -cNum*-rNum但是, -r不能和-t一起使用(为什么呢?你猜).eg: -r 20
-t NUM 测试持续时间,指你运行一次测试需要的时间,在timeout后,结束测试.
-f file. 用来测试file里面的url路径 eg: -f girls.txt.
-b . 就是询问开不开启基准测试(benchmark)。 这个参数不太重要,有兴趣的同学,可以下去学习一下。
关于-c -r我就不介绍了。 大家有兴趣,可以参考一下,我前一篇文章让你升级的网络知识. 这里主要介绍一下 -f 参数.
通常,如果我们想要测试多个页面的话,可以新建一个文件,在文件中创建 你想测试的所有网页地址.
比如:
//文件名为 urls.txt
www.example.com www.example.org 123.45.67.89
然后运行测试
siege -f your/file/path.txt -c 100 -t 10s
OK~ 关于进程和测试的内容就介绍到这了。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Ein Artikel über Speichersteuerung in Node
Apr 26, 2023 pm 05:37 PM
Ein Artikel über Speichersteuerung in Node
Apr 26, 2023 pm 05:37 PM
Der nicht blockierende und ereignisgesteuerte Knotendienst hat den Vorteil eines geringen Speicherverbrauchs und eignet sich sehr gut für die Verarbeitung massiver Netzwerkanforderungen. Unter der Voraussetzung massiver Anfragen müssen Probleme im Zusammenhang mit der „Speicherkontrolle“ berücksichtigt werden. 1. Der Garbage-Collection-Mechanismus und die Speicherbeschränkungen von V8 Js wird von der Garbage-Collection-Maschine gesteuert
 Detaillierte grafische Erläuterung des Speichers und des GC der Node V8-Engine
Mar 29, 2023 pm 06:02 PM
Detaillierte grafische Erläuterung des Speichers und des GC der Node V8-Engine
Mar 29, 2023 pm 06:02 PM
Dieser Artikel vermittelt Ihnen ein detailliertes Verständnis des Speichers und Garbage Collectors (GC) der NodeJS V8-Engine. Ich hoffe, er wird Ihnen hilfreich sein!
 Lassen Sie uns ausführlich über das File-Modul in Node sprechen
Apr 24, 2023 pm 05:49 PM
Lassen Sie uns ausführlich über das File-Modul in Node sprechen
Apr 24, 2023 pm 05:49 PM
Das Dateimodul ist eine Kapselung der zugrunde liegenden Dateioperationen, wie z. B. Lesen/Schreiben/Öffnen/Schließen/Löschen von Dateien, Hinzufügen usw. Das größte Merkmal des Dateimoduls besteht darin, dass alle Methoden zwei Versionen von **synchronem** und **bereitstellen. asynchron**, mit Methoden mit dem Suffix sync sind alle Synchronisationsmethoden, und diejenigen ohne sind alle heterogene Methoden.
 Anwendungsmethode des gemeinsam genutzten Speichers zwischen mehreren Prozessen in der Golang-Funktion
May 17, 2023 pm 12:52 PM
Anwendungsmethode des gemeinsam genutzten Speichers zwischen mehreren Prozessen in der Golang-Funktion
May 17, 2023 pm 12:52 PM
Als hochgradig gleichzeitige Programmiersprache ermöglichen der integrierte Coroutine-Mechanismus und die Multithread-Operationen von Golang ein leichtes Multitasking. In einem Multiprozess-Verarbeitungsszenario sind jedoch die Kommunikation und der gemeinsame Speicher zwischen verschiedenen Prozessen zu Schlüsselthemen bei der Programmentwicklung geworden. In diesem Artikel wird die Anwendungsmethode zur Realisierung des gemeinsamen Speichers zwischen mehreren Prozessen in Golang vorgestellt. 1. So implementieren Sie Multiprozesse in Golang In Golang kann die gleichzeitige Verarbeitung mehrerer Prozesse auf verschiedene Arten implementiert werden, einschließlich Fork, os.Process,
 Lassen Sie uns über die Ereignisschleife in Node sprechen
Apr 11, 2023 pm 07:08 PM
Lassen Sie uns über die Ereignisschleife in Node sprechen
Apr 11, 2023 pm 07:08 PM
Die Ereignisschleife ist ein grundlegender Bestandteil von Node.js und ermöglicht die asynchrone Programmierung, indem sie sicherstellt, dass der Hauptthread nicht blockiert wird. Das Verständnis der Ereignisschleife ist für die Erstellung effizienter Anwendungen von entscheidender Bedeutung. Der folgende Artikel wird Ihnen ein detailliertes Verständnis der Ereignisschleife in Node vermitteln. Ich hoffe, er wird Ihnen hilfreich sein!
 Was soll ich tun, wenn der Knoten den Befehl npm nicht verwenden kann?
Feb 08, 2023 am 10:09 AM
Was soll ich tun, wenn der Knoten den Befehl npm nicht verwenden kann?
Feb 08, 2023 am 10:09 AM
Der Grund, warum der Knoten den Befehl npm nicht verwenden kann, liegt darin, dass die Umgebungsvariablen nicht richtig konfiguriert sind. Die Lösung ist: 1. Öffnen Sie „Systemeigenschaften“ 2. Suchen Sie nach „Umgebungsvariablen“ -> „Systemvariablen“ und bearbeiten Sie dann die Umgebung Variablen; 3. Suchen Sie den Speicherort des NodeJS-Ordners. 4. Klicken Sie auf „OK“.
 Erfahren Sie mehr über Puffer in Node
Apr 25, 2023 pm 07:49 PM
Erfahren Sie mehr über Puffer in Node
Apr 25, 2023 pm 07:49 PM
Zu Beginn lief JS nur auf der Browserseite. Es war einfach, Unicode-codierte Zeichenfolgen zu verarbeiten, aber es war schwierig, binäre und nicht Unicode-codierte Zeichenfolgen zu verarbeiten. Und Binär ist das Datenformat der niedrigsten Ebene des Computer-, Video-/Audio-/Programm-/Netzwerkpakets
 Ein Artikel über die effiziente Entwicklung von Node.js-Anwendungen auf der Präsentationsebene
Apr 17, 2023 pm 07:02 PM
Ein Artikel über die effiziente Entwicklung von Node.js-Anwendungen auf der Präsentationsebene
Apr 17, 2023 pm 07:02 PM
Wie verwende ich Node.js für die Entwicklung von Front-End-Anwendungen? Der folgende Artikel führt Sie in die Methode zur Entwicklung von Front-End-Anwendungen in Node ein, die die Entwicklung von Anwendungen auf der Präsentationsebene umfasst. Die Lösung, die ich heute geteilt habe, ist für einfache Szenarien gedacht. Sie soll es Front-End-Entwicklern ermöglichen, einige einfache serverseitige Entwicklungsaufgaben zu erledigen, ohne zu viel Hintergrundwissen und Fachwissen über Node.js beherrschen zu müssen, selbst wenn sie über keine Programmierkenntnisse verfügen Erfahrung.
