

mysql如何去除两个字段数据相同的记录?

比如说有个name列和一个eamil列,如果数据库里面有条记录的这两列的值相同(我说的是这条记录的对应的那两列的值相同,并不是同一条记录里面两列值相同)的话就自动删除其他多余的列而保留最新的那一条(也就是ID最小的那个,ID是一个自增主键)
——————————————————
也就是说表里面有两条记录的name都是admin,email都是abc@163.com,我只想保留其中一条,这该怎么做
回复内容:
其实你会用英文搜索的话。可以很方便在stack overflow上 找到相关的信息 真的学CS的就不要用百度了 用google你会发现一个不一样的世界的随便贴一个
sql - How can I remove duplicate rows?
稍微讲一下其中一个思路(里面有很多很好的答案 你可以自己去看)
就是做一个group by 保留其中id 最大的(你说自增长 id最大的应该就是最新的)就可以了
具体sql query 可以这样写
<span class="k">delete</span> <span class="k">from</span> <span class="n">test</span> <span class="k">where</span> <span class="n">id</span> <span class="k">not</span> <span class="k">in</span><span class="p">(</span> <span class="k">select</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span><span class="p">,</span><span class="k">max</span><span class="p">(</span><span class="n">id</span><span class="p">)</span> <span class="k">from</span> <span class="n">test</span> <span class="k">group</span> <span class="k">by</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span> <span class="k">having</span> <span class="n">id</span> <span class="k">is</span> <span class="k">not</span> <span class="k">null</span><span class="p">)</span>
数据:
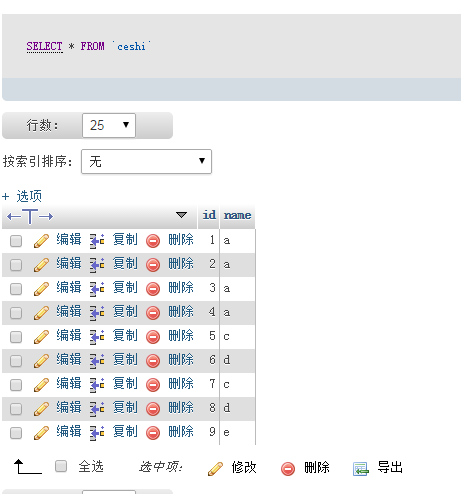

执行sql:select count(*) as count ,name,id from ceshi group by name
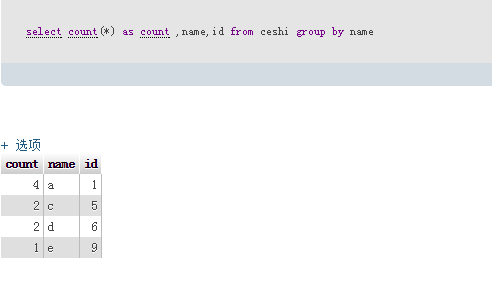 最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)
最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)如果想保留id的最大值:
简单的办法是:delete from ceshi where id not in (select count(*) as count ,name,id from (select * from ceshi order by id desc) group by name) distinct 其实非常的简单,只需要把你这张表当成两张表来处理就行了。
DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id 这里有个问题,题主说保留最新的那一条(也就是ID最小的那个),既然是递增,最新的不应该是最大的那条吗?
上面的的语句,p1.id '即可。
当然是用group by,count可以更精准控制重复n次的情况。不过目测楼主需求应该只要把重复的删掉,保留最新的就可以了。 DELETE FROM table WHERE id not in ( SELECT
tb.id FROM ( SELECT tmp.* FROM table tmp ) tb GROUP BY tb.field1, tb.field2,… );
table是表名,field是要去重的字段。 新建一个表,设置name,email为唯一索引,然后重新插入旧表数据

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Hongmeng native Anwendung zufälliger Poesie
Feb 19, 2024 pm 01:36 PM
Hongmeng native Anwendung zufälliger Poesie
Feb 19, 2024 pm 01:36 PM
Um mehr über Open Source zu erfahren, besuchen Sie bitte: 51CTO Hongmeng Developer Community https://ost.51cto.com Laufumgebung DAYU200:4.0.10.16SDK: 4.0.10.15IDE: 4.0.600 1. Um eine Anwendung zu erstellen, klicken Sie auf Datei- >newFile->CreateProgect. Vorlage auswählen: [OpenHarmony] EmptyAbility: Geben Sie den Projektnamen, shici, den Namen des Anwendungspakets com.nut.shici und den Speicherort der Anwendung XXX ein (kein Chinesisch, Sonderzeichen oder Leerzeichen). CompileSDK10, Modell: Stage. Gerät
 So verwenden Sie die Module email, smtplib, poplib und imaplib zum Senden und Empfangen von E-Mails in Python
May 16, 2023 pm 11:44 PM
So verwenden Sie die Module email, smtplib, poplib und imaplib zum Senden und Empfangen von E-Mails in Python
May 16, 2023 pm 11:44 PM
Der Weg einer E-Mail ist: MUA: MailUserAgent – Mail User Agent. (d. h. E-Mail-Software ähnlich wie Outlook) MTA: MailTransferAgent – Mail-Transfer-Agent, also E-Mail-Dienstanbieter wie NetEase, Sina usw. MDA: MailDeliveryAgent – Mail-Zustellungsagent. Ein Server des E-Mail-Dienstanbieters sender->MUA->MTA->MTA->if
 Was ist der Unterschied zwischen comcn und com
May 12, 2023 pm 04:08 PM
Was ist der Unterschied zwischen comcn und com
May 12, 2023 pm 04:08 PM
Der Unterschied zwischen comcn und com: 1. Es gibt Unterschiede in der Bedeutung zwischen comcn und com, aber keinen Unterschied in der Zugriffsgeschwindigkeit. 2. comcn ist ein internationaler Domainname und ein globaler Top-Level-Domainname zur Verwendung durch kommerzielle Institutionen , während cn ein chinesischer Unternehmensdomänenname ist, können sich nur inländische kommerzielle Institutionen registrieren. 3. Die Suchpriorität besteht darin, dass cn zuerst nach dem .cn-Server sucht Suchen Sie dann nach .com. 4. cn wird von cnnic China Internet Center Management bereitgestellt, die Verwaltungsorganisation von com befindet sich im Ausland.
 php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出php提交表单通过后,弹出的对话框怎样在当前页弹出而不是在空白页弹出?想实现这样的效果:而不是空白页弹出:------解决方案--------------------如果你的验证用PHP在后端,那么就用Ajax;仅供参考:HTML code
 Welche Rolle und Verwendung spielt die Springboot-Administratorüberwachung?
May 25, 2023 pm 06:52 PM
Welche Rolle und Verwendung spielt die Springboot-Administratorüberwachung?
May 25, 2023 pm 06:52 PM
Anwendbare Szenarien: 1. Der Projektumfang ist nicht sehr groß, und die Anforderungen an die Parallelität sind nicht hoch. 3. Es gibt keine dedizierten Betriebs- und Wartungskräfte regelmäßige Projekte oder Einheiten, bei denen die Aufteilung der Verantwortlichkeiten nicht ganz klar ist. Oft reicht ein System von den Anforderungen über Design, Entwicklung und Tests bis hin zur endgültigen Einführung, dem Betrieb und der Wartung. Oftmals werden 80 % der Aufgaben vom Entwicklungsteam erledigt. Daher müssen Entwickler neben der Implementierung der Systemfunktionen auch Kunden beraten, Fragen beantworten und Produktionsprobleme lösen. Stellen Sie sich vor, dass es nach dem Start einer Anwendung keine Überwachungsmaßnahmen gibt. Genau wie beim Autofahren ohne Armaturenbrett fühlt sich niemand auf der Straße so sicher. Es lohnt sich, darüber nachzudenken, wie man Einfachheit und Effizienz in Einklang bringt. 1. Springb
 Sie benötigen die vom Administrator bereitgestellten Berechtigungen, um Änderungen an dieser Datei vorzunehmen.
Jul 26, 2023 am 10:56 AM
Sie benötigen die vom Administrator bereitgestellten Berechtigungen, um Änderungen an dieser Datei vorzunehmen.
Jul 26, 2023 am 10:56 AM
Sie benötigen die vom Administrator bereitgestellten Berechtigungen, um Änderungen an dieser Datei vorzunehmen: 1. Nachdem Sie das Administratorkonto auf der Anmeldeoberfläche ausgewählt und das Kennwort eingegeben haben, können Sie die Datei problemlos ändern. 2. Sie können mit der rechten Maustaste auf die Datei klicken und sie auswählen „Als Administrator“-Lösung: 3. Ändern Sie die Dateiberechtigungen, klicken Sie mit der rechten Maustaste auf die Datei, wählen Sie „Eigenschaften“, klicken Sie auf die Registerkarte „Sicherheit“, dann auf die Schaltfläche „Bearbeiten“, wählen Sie Ihren Benutzernamen aus und aktivieren Sie dann „Vollzugriff“. Option 4. Verwenden Sie die Eingabeaufforderung, um das Problem zu lösen. 5. Legen Sie UA-Berechtigungen fest.
 So verwenden Sie Flask-Admin zum Implementieren der Hintergrundverwaltungsschnittstelle
Aug 03, 2023 pm 11:30 PM
So verwenden Sie Flask-Admin zum Implementieren der Hintergrundverwaltungsschnittstelle
Aug 03, 2023 pm 11:30 PM
So verwenden Sie Flask-Admin zum Implementieren der Backend-Verwaltungsschnittstelle. Hintergrundeinführung: Mit der Entwicklung von Websites und Anwendungen wird die Backend-Verwaltungsschnittstelle immer wichtiger. Während des Entwicklungsprozesses benötigen wir oft eine praktische und schnelle Backend-Verwaltungsschnittstelle, um Daten, Benutzer und andere wichtige Informationen zu verwalten. Flask-Admin ist eine leistungsstarke und benutzerfreundliche Flask-Erweiterung, mit der wir die Hintergrundverwaltungsschnittstelle schnell implementieren können. Flask-Admin ist ein Open-Source-Projekt, das auf Flask und SQLAlchemy basiert
 Anleitung zum Einfügen von Anhängen in das Win10-Postfach
Jan 07, 2024 pm 12:14 PM
Anleitung zum Einfügen von Anhängen in das Win10-Postfach
Jan 07, 2024 pm 12:14 PM
Viele Benutzer müssen in ihrem täglichen Leben E-Mails für die Arbeit versenden, und einige müssen sogar verschiedene Plug-in-Materialien für die Kommunikation anhängen. Wie fügt man Anhänge ein? Werfen wir einen Blick auf das ausführliche Tutorial unten. So fügen Sie Anhänge in das Win10-Postfach ein: 1. Öffnen Sie das Postfach. 2. Klicken Sie auf das Symbol „Neue E-Mail“ in der oberen linken Ecke. 3. Klicken Sie auf „Einfügen“ in der oberen rechten Ecke. 4. Klicken Sie auf „Anhang“ in der oberen rechten Ecke. 5 . Wählen Sie den gewünschten „Anhang“ aus. 6. Fertigstellen
