

Php中文件下载功能实现超详细流程分析_php技巧

浏览器发送一个请求,请求访问服务器中的某个网页(如:down.php),该网页的代码如下
客户端从服务端下载文件的流程分析:
浏览器发送一个请求,请求访问服务器中的某个网页(如:down.php),该网页的代码如下。
服务器接受到该请求以后,马上运行该down.php文件
运行该文件的时候,必然要把将要被下载的文件读入内存当中(这里是圣诞狂欢.jpg这张图片),这里通过fopen()函数完成该动作
注意:任何有关从服务器下载的文件操作,必然需要先在服务端将文件读入内存当中
现在文件已经在内存当中了,这是需要从内存当中读取文件,通过fread()函数完成该动作
需要注意的是,如果文件较大,文件应该是被分成多段返回给客户端的,并不是等文件在服务端全部读取完毕后,一次性返回给客户端,因为这样子会增加服务器的负荷。
所以我们需要在php代码中设置一次读取的字节数,比如我在下面的代码中通过$buffer=1024设置一次读取的字节数,每读取一次,就输出数据(即返回给浏览器)
流程图: 
复制代码 代码如下:
header("Content-type:text/html;charset=utf-8");
// $file_name="cookie.jpg";
$file_name="圣诞狂欢.jpg";
//用以解决中文不能显示出来的问题
$file_name=iconv("utf-8","gb2312",$file_name);
$file_sub_path=$_SERVER['DOCUMENT_ROOT']."marcofly/phpstudy/down/down/";
$file_path=$file_sub_path.$file_name;
//首先要判断给定的文件存在与否
if(!file_exists($file_path)){
echo "没有该文件文件";
return ;
}
$fp=fopen($file_path,"r");
$file_size=filesize($file_path);
//下载文件需要用到的头
Header("Content-type: application/octet-stream");
Header("Accept-Ranges: bytes");
Header("Accept-Length:".$file_size);
Header("Content-Disposition: attachment; filename=".$file_name);
$buffer=1024;
$file_count=0;
//向浏览器返回数据
while(!feof($fp) && $file_count<$file_size){
$file_con=fread($fp,$buffer);
$file_count+=$buffer;
echo $file_con;
}
fclose($fp);
?>
几点注意事项:
header("Content-type:text/html;charset=utf-8")的作用:在服务器响应浏览器的请求时,告诉浏览器以编码格式为UTF-8的编码显示该内容
关于file_exists()函数不支持中文路径的问题:因为php函数比较早,不支持中文,所以如果被下载的文件名是中文的话,需要对其进行字符编码转换,否则file_exists()函数不能识别,可以使用iconv()函数进行编码转换
$file_sub_path() 我使用的是绝对路径,执行效率要比相对路径高
Header("Content-type: application/octet-stream")的作用:通过这句代码客户端浏览器就能知道服务端返回的文件形式
Header("Accept-Ranges: bytes")的作用:告诉客户端浏览器返回的文件大小是按照字节进行计算的
Header("Accept-Length:".$file_size)的作用:告诉浏览器返回的文件大小
Header("Content-Disposition: attachment; filename=".$file_name)的作用:告诉浏览器返回的文件的名称
以上四个Header()是必需的
fclose($fp)可以把缓冲区内最后剩余的数据输出到磁盘文件中,并释放文件指针和有关的缓冲区

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So verwenden Sie Magnetlinks
Feb 18, 2024 am 10:02 AM
So verwenden Sie Magnetlinks
Feb 18, 2024 am 10:02 AM
Magnet-Link ist eine Link-Methode zum Herunterladen von Ressourcen, die bequemer und effizienter ist als herkömmliche Download-Methoden. Mit Magnet-Links können Sie Ressourcen im Peer-to-Peer-Verfahren herunterladen, ohne auf einen Zwischenserver angewiesen zu sein. In diesem Artikel erfahren Sie, wie Sie Magnetlinks verwenden und worauf Sie achten sollten. 1. Was ist ein Magnet-Link? Ein Magnet-Link ist eine Download-Methode, die auf dem P2P-Protokoll (Peer-to-Peer) basiert. Über Magnet-Links können Benutzer eine direkte Verbindung zum Herausgeber der Ressource herstellen, um die gemeinsame Nutzung und das Herunterladen von Ressourcen abzuschließen. Im Vergleich zu herkömmlichen Download-Methoden magnetisch
 So laden Sie Episoden des Hongguo-Kurzdramas herunter
Mar 11, 2024 pm 09:16 PM
So laden Sie Episoden des Hongguo-Kurzdramas herunter
Mar 11, 2024 pm 09:16 PM
Hongguo Short Play ist nicht nur eine Plattform zum Ansehen von Kurzstücken, sondern auch eine Fundgrube an reichhaltigen Inhalten, darunter Romane und andere spannende Inhalte. Für viele lesebegeisterte Nutzer ist das zweifellos eine große Überraschung. Viele Benutzer wissen jedoch immer noch nicht, wie sie diese Romane in Hongguo Short Play herunterladen und ansehen können. Im Folgenden stellt Ihnen der Herausgeber dieser Website detaillierte Download-Schritte vor, in der Hoffnung, allen bedürftigen Partnern zu helfen. Wie kann ich das Hongguo-Kurzspiel herunterladen und ansehen? Antwort: [Hongguo-Kurzspiel] – [Hörbuch] – [Artikel] – [Download]. Spezifische Schritte: 1. Öffnen Sie zuerst die Hongguo Short Drama-Software, rufen Sie die Startseite auf und klicken Sie oben auf der Seite auf die Schaltfläche [Bücher anhören]. 2. Dann können wir hier auf der Romanseite viele Artikelinhalte sehen
 Was soll ich tun, wenn ich das Hintergrundbild einer anderen Person herunterlade, nachdem ich mich bei WallpaperEngine bei einem anderen Konto angemeldet habe?
Mar 19, 2024 pm 02:00 PM
Was soll ich tun, wenn ich das Hintergrundbild einer anderen Person herunterlade, nachdem ich mich bei WallpaperEngine bei einem anderen Konto angemeldet habe?
Mar 19, 2024 pm 02:00 PM
Wenn Sie sich auf Ihrem Computer beim Steam-Konto einer anderen Person anmelden und das Konto dieser anderen Person über eine Hintergrundsoftware verfügt, lädt Steam automatisch die Hintergrundbilder herunter, die für das Konto der anderen Person abonniert wurden, nachdem Sie zu Ihrem eigenen Konto zurückgewechselt haben Deaktivieren der Steam-Cloud-Synchronisierung. Was tun, wenn WallpaperEngine die Hintergrundbilder anderer Personen herunterlädt, nachdem Sie sich bei einem anderen Konto angemeldet haben? 1. Melden Sie sich bei Ihrem eigenen Steam-Konto an, suchen Sie in den Einstellungen nach der Cloud-Synchronisierung und deaktivieren Sie die Steam-Cloud-Synchronisierung. 2. Melden Sie sich bei dem Steam-Konto einer anderen Person an, bei dem Sie sich zuvor angemeldet haben, öffnen Sie den Wallpaper Creative Workshop, suchen Sie nach den Abonnementinhalten und kündigen Sie dann alle Abonnements. (Falls Sie das Hintergrundbild in Zukunft nicht mehr finden, können Sie es zunächst abholen und dann das Abonnement kündigen.) 3. Wechseln Sie zurück zu Ihrem eigenen Steam
 Wie lade ich Links herunter, die mit 115:// beginnen? Methodeneinführung herunterladen
Mar 14, 2024 am 11:58 AM
Wie lade ich Links herunter, die mit 115:// beginnen? Methodeneinführung herunterladen
Mar 14, 2024 am 11:58 AM
In letzter Zeit haben viele Benutzer den Editor gefragt, wie man Links herunterlädt, die mit 115:// beginnen? Wenn Sie Links herunterladen möchten, die mit 115:// beginnen, müssen Sie den 115-Browser verwenden. Nachdem Sie den 115-Browser heruntergeladen haben, schauen wir uns das unten vom Herausgeber zusammengestellte Download-Tutorial an. Einführung zum Herunterladen von Links, die mit 115:// beginnen. 1. Melden Sie sich bei 115.com an, laden Sie den 115-Browser herunter und installieren Sie ihn. 2. Geben Sie Folgendes ein: chrome://extensions/ in die Adressleiste des 115-Browsers, rufen Sie das Extension Center auf, suchen Sie nach Tampermonkey und installieren Sie das entsprechende Plug-in. 3. Geben Sie in die Adressleiste des Browsers 115 ein: Grease Monkey Script: https://greasyfork.org/en/
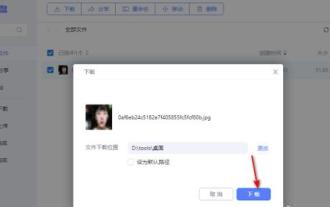 So laden Sie Dateien von der 123-Cloud-Festplatte herunter
Feb 23, 2024 pm 08:58 PM
So laden Sie Dateien von der 123-Cloud-Festplatte herunter
Feb 23, 2024 pm 08:58 PM
123 Cloud Disk kann viele Dateien herunterladen. Wie lade ich Dateien konkret herunter? Benutzer können die Datei auswählen, die sie herunterladen möchten, und zum Herunterladen klicken, oder mit der rechten Maustaste auf die Datei klicken und „Herunterladen“ auswählen. In dieser Einführung in die Methode zum Herunterladen von Dateien von der 123-Cloud-Festplatte erfahren Sie, wie Sie sie herunterladen. Freunde, die nicht viel darüber wissen, sollten sich beeilen und einen Blick darauf werfen! So laden Sie Dateien von 123 Cloud Disk herunter 1. Öffnen Sie zuerst die Software, klicken Sie auf die Software, die heruntergeladen werden muss, und dann wird darauf ein Download-Button angezeigt. 2. Oder klicken Sie mit der rechten Maustaste auf die Software und Sie können die Download-Schaltfläche in der Liste sehen. 3. Es erscheint ein Download-Fenster. Wählen Sie den Speicherort aus, den Sie herunterladen möchten. 4. Klicken Sie nach der Auswahl auf „Herunterladen“, um diese Dateien herunterzuladen.
 Einführung in das Herunterladen und Installieren des Superpeople-Spiels
Mar 30, 2024 pm 04:01 PM
Einführung in das Herunterladen und Installieren des Superpeople-Spiels
Mar 30, 2024 pm 04:01 PM
Das Superpeople-Spiel kann über den Steam-Client heruntergeladen werden. Die Größe dieses Spiels beträgt normalerweise eineinhalb Stunden. Hier ist ein spezielles Download- und Installations-Tutorial. Neue Methode zur Beantragung globaler geschlossener Tests 1) Suchen Sie nach „SUPERPEOPLE“ im Steam-Store (Steam-Client-Download) 2) Klicken Sie unten auf der „SUPERPEOPLE“-Store-Seite auf „Zugriff auf geschlossene SUPERPEOPLE-Tests anfordern“ 3) Nachdem Sie auf geklickt haben Schaltfläche „Zugriff anfordern“. Das Spiel „SUPERPEOPLECBT“ kann in der Steam-Bibliothek bestätigt werden. 4) Klicken Sie auf die Schaltfläche „Installieren“ in „SUPERPEOPLECBT“ und laden Sie es herunter
 So laden Sie Videos von einem Videokonto herunter „Muss man gesehen haben: Eine einfache Möglichkeit, Videos von einem Videokonto zu speichern'
Feb 06, 2024 pm 06:42 PM
So laden Sie Videos von einem Videokonto herunter „Muss man gesehen haben: Eine einfache Möglichkeit, Videos von einem Videokonto zu speichern'
Feb 06, 2024 pm 06:42 PM
Jetzt fangen immer mehr Menschen an, Videokonten zu nutzen, die auch eine kurze Videoplattform sind, auf der sie ihr tägliches Leben teilen und mit Videokonten Geld verdienen können. Kürzlich sah ich, wie einige Freunde fragten, warum die Videos vom WeChat-Videokonto nicht heruntergeladen wurden, und es gab tatsächlich keinen Download-Button, sodass er das Video nur auf andere Weise extrahieren konnte mit dir eine dumme Methode, komm und schau es dir an. So extrahieren Sie Videos aus WeChat-Videokonten 1. Öffnen Sie unsere Computerversion von WeChat und suchen Sie auf der linken Seite nach dem Videokonto, das Sie herunterladen möchten. 3. Verwenden Sie abschließend das Bildschirmaufzeichnungstool, um es anzupassen Größe des aufgenommenen Videos. Nehmen Sie es einfach auf und bearbeiten Sie es am Ende. PS: 1. Diese Methode kann nur auf der Computerversion aufgezeichnet werden, nicht auf dem Mobiltelefon.
 Wie lade ich eine Quark-Netzwerkfestplatte lokal herunter? So speichern Sie von Quark Network Disk heruntergeladene Dateien wieder auf dem lokalen Computer
Mar 13, 2024 pm 08:31 PM
Wie lade ich eine Quark-Netzwerkfestplatte lokal herunter? So speichern Sie von Quark Network Disk heruntergeladene Dateien wieder auf dem lokalen Computer
Mar 13, 2024 pm 08:31 PM
Viele Benutzer müssen Dateien herunterladen, wenn sie Quark Network Disk verwenden, aber wir möchten sie lokal speichern. Wie richtet man das also ein? Auf dieser Website erfahren Sie ausführlich, wie Sie von Quark Network Disk heruntergeladene Dateien wieder auf dem lokalen Computer speichern. So speichern Sie von der Quark-Netzwerkfestplatte heruntergeladene Dateien wieder auf Ihrem lokalen Computer 1. Öffnen Sie Quark, melden Sie sich bei Ihrem Konto an und klicken Sie auf das Listensymbol. 2. Nachdem Sie auf das Symbol geklickt haben, wählen Sie das Netzwerklaufwerk aus. 3. Nachdem Sie Quark Network Disk aufgerufen haben, klicken Sie auf „Meine Dateien“. 4. Nachdem Sie „Meine Dateien“ aufgerufen haben, wählen Sie die Datei aus, die Sie herunterladen möchten, und klicken Sie auf das Dreipunktsymbol. 5. Markieren Sie die Datei, die Sie herunterladen möchten, und klicken Sie auf Herunterladen.
