

在线成语词典 洪恩在线成语词典小偷程序php版

主要函数是file_get_contents,主程序分两段,跟我一起看过来吧(凡人博客原创代码,转载请注明)。
复制代码 代码如下:
function escape($str){
preg_match_all('/[\x80-\xff].|[\x01-\x7f]+/',$str,$r);
$ar = $r[0];
foreach($ar as $k=>$v){
if(ord($v[0]) $ar[$k] = rawurlencode($v);
else
$ar[$k] = '%u'.bin2hex(iconv('GB2312','UCS-2',$v));
}
return join('',$ar);
}
上面的函数主要是用php实现JavaScript的escape编码过程,因为洪恩的查询接口需要传递过去的值是经过escape编码后的成语条目。
复制代码 代码如下:
function chacy($chengyu){
$chengyu=escape($chengyu);
$text=@file_get_contents('http://study.hongen.com/dict/ndsearchchengyu.aspx?type=exact&word='.$chengyu);
$pos1=strpos($text,'

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Arbeiten mit Flash -Sitzungsdaten in Laravel
Mar 12, 2025 pm 05:08 PM
Arbeiten mit Flash -Sitzungsdaten in Laravel
Mar 12, 2025 pm 05:08 PM
Laravel vereinfacht die Behandlung von temporären Sitzungsdaten mithilfe seiner intuitiven Flash -Methoden. Dies ist perfekt zum Anzeigen von kurzen Nachrichten, Warnungen oder Benachrichtigungen in Ihrer Anwendung. Die Daten bestehen nur für die nachfolgende Anfrage standardmäßig: $ Anfrage-
 Curl in PHP: So verwenden Sie die PHP -Curl -Erweiterung in REST -APIs
Mar 14, 2025 am 11:42 AM
Curl in PHP: So verwenden Sie die PHP -Curl -Erweiterung in REST -APIs
Mar 14, 2025 am 11:42 AM
Die PHP Client -URL -Erweiterung (CURL) ist ein leistungsstarkes Tool für Entwickler, das eine nahtlose Interaktion mit Remote -Servern und REST -APIs ermöglicht. Durch die Nutzung von Libcurl, einer angesehenen Bibliothek mit Multi-Protokoll-Dateien, erleichtert PHP Curl effiziente Execu
 Vereinfachte HTTP -Reaktion verspottet in Laravel -Tests
Mar 12, 2025 pm 05:09 PM
Vereinfachte HTTP -Reaktion verspottet in Laravel -Tests
Mar 12, 2025 pm 05:09 PM
Laravel bietet eine kurze HTTP -Antwortsimulationssyntax und vereinfache HTTP -Interaktionstests. Dieser Ansatz reduziert die Code -Redundanz erheblich, während Ihre Testsimulation intuitiver wird. Die grundlegende Implementierung bietet eine Vielzahl von Verknüpfungen zum Antworttyp: Verwenden Sie Illuminate \ Support \ facades \ http; Http :: fake ([ 'Google.com' => 'Hallo Welt',, 'github.com' => ['foo' => 'bar'], 'Forge.laravel.com' =>
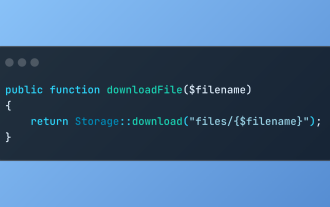 Datei -Downloads in Laravel mit Speicher :: Download ermitteln
Mar 06, 2025 am 02:22 AM
Datei -Downloads in Laravel mit Speicher :: Download ermitteln
Mar 06, 2025 am 02:22 AM
Die Speicher :: Download -Methode des Laravel -Frameworks bietet eine prägnante API für die sichere Bearbeitung von Datei -Downloads beim Verwalten von Abstraktionen des Dateispeichers. Hier ist ein Beispiel für die Verwendung von Storage :: download () im Beispiel -Controller:
 12 Beste PHP -Chat -Skripte auf Codecanyon
Mar 13, 2025 pm 12:08 PM
12 Beste PHP -Chat -Skripte auf Codecanyon
Mar 13, 2025 pm 12:08 PM
Möchten Sie den dringlichsten Problemen Ihrer Kunden in Echtzeit und Sofortlösungen anbieten? Mit Live-Chat können Sie Echtzeitgespräche mit Kunden führen und ihre Probleme sofort lösen. Sie ermöglichen es Ihnen, Ihrem Brauch einen schnelleren Service zu bieten
 Erklären Sie das Konzept der späten statischen Bindung in PHP.
Mar 21, 2025 pm 01:33 PM
Erklären Sie das Konzept der späten statischen Bindung in PHP.
Mar 21, 2025 pm 01:33 PM
In Artikel wird die in PHP 5.3 eingeführte LSB -Bindung (LSB) erörtert, die die Laufzeitauflösung der statischen Methode ermöglicht, um eine flexiblere Vererbung zu erfordern. Die praktischen Anwendungen und potenziellen Perfo von LSB
 PHP -Protokollierung: Best Practices für die PHP -Protokollanalyse
Mar 10, 2025 pm 02:32 PM
PHP -Protokollierung: Best Practices für die PHP -Protokollanalyse
Mar 10, 2025 pm 02:32 PM
Die PHP -Protokollierung ist für die Überwachung und Debugie von Webanwendungen von wesentlicher Bedeutung sowie für das Erfassen kritischer Ereignisse, Fehler und Laufzeitverhalten. Es bietet wertvolle Einblicke in die Systemleistung, hilft bei der Identifizierung von Problemen und unterstützt eine schnellere Fehlerbehebung
 So registrieren und verwenden Sie Laravel -Dienstleister
Mar 07, 2025 am 01:18 AM
So registrieren und verwenden Sie Laravel -Dienstleister
Mar 07, 2025 am 01:18 AM
Der Service -Container und die Dienstleister von Laravel sind für seine Architektur von grundlegender Bedeutung. In diesem Artikel werden Servicecontainer untersucht, Details für die Erstellung, Registrierung, Registrierung und die praktische Nutzung mit Beispielen mit Beispielen untersucht. Wir beginnen mit einem Ove
