
 Backend-Entwicklung
Python-Tutorial
Analyse der wichtigsten Punkte beim Schreiben eines grundlegenden Code-Interpreters mit Python
Backend-Entwicklung
Python-Tutorial
Analyse der wichtigsten Punkte beim Schreiben eines grundlegenden Code-Interpreters mit Python
Analyse der wichtigsten Punkte beim Schreiben eines grundlegenden Code-Interpreters mit Python

Ich habe mich schon immer sehr für Compiler und Parser interessiert. Auch das Konzept und das Gesamtgerüst eines Compilers sind mir sehr klar, aber ich weiß nicht viel über die Details. Der Programmquellcode, den wir schreiben, ist tatsächlich eine Zeichenfolge. Der Compiler oder Interpreter kann diese Zeichenfolge direkt verstehen und ausführen. In diesem Artikel wird Python verwendet, um einen einfachen Parser zum Interpretieren einer kleinen Listenoperationssprache (ähnlich der Python-Liste) zu implementieren. Tatsächlich sind Compiler und Interpreter kein Geheimnis, solange die grundlegende Theorie verstanden wird, ist die Implementierung relativ einfach (natürlich ist ein Compiler oder Interpreter auf Produktebene immer noch sehr kompliziert).
Von dieser Listensprache unterstützte Operationen:
veca = [1, 2, 3] # 列表声明 vecb = [4, 5, 6] print 'veca:', veca # 打印字符串、列表,print expr+ print 'veca * 2:', veca * 2 # 列表与整数乘法 print 'veca + 2:', veca + 2 # 列表与整数加法 print 'veca + vecb:', veca + vecb # 列表加法 print 'veca + [11, 12]:', veca + [11, 12] print 'veca * vecb:', veca * vecb # 列表乘法 print 'veca:', veca print 'vecb:', vecb
Entsprechende Ausgabe:
veca: [1, 2, 3] veca * 2: [2, 4, 6] veca + 2: [1, 2, 3, 2] veca + vecb: [1, 2, 3, 2, 4, 5, 6] veca + [11, 12]: [1, 2, 3, 2, 11, 12] veca * vecb: [4, 5, 6, 8, 10, 12, 12, 15, 18, 8, 10, 12] veca: [1, 2, 3, 2] vecb: [4, 5, 6]
Wenn Compiler und Interpreter eingegebene Zeichenströme verarbeiten, stimmen sie grundsätzlich mit der Art und Weise überein, wie Menschen Sätze verstehen. Zum Beispiel:
I love you.
Wenn Sie neu im Englischlernen sind, müssen Sie zunächst die Bedeutung jedes Wortes kennen und dann den Wortteil jedes Wortes analysieren, um ihn an die Subjekt-Prädikat-Objekt-Struktur anzupassen, damit Sie die Bedeutung verstehen können dieses Satzes. Dieser Satz ist eine Zeichenfolge, die einen lexikalischen Einheitsstrom erhält. Tatsächlich handelt es sich um eine lexikalische Analyse, die die Konvertierung vom Zeichenstrom in den lexikalischen Einheitsstrom abschließt. Die Analyse der Wortart und die Bestimmung der Subjekt-Verb-Objekt-Struktur besteht darin, diese Struktur gemäß der englischen Grammatik zu identifizieren. Dies ist eine grammatikalische Analyse, und der grammatikalische Analysebaum wird basierend auf dem Fluss der eingegebenen lexikalischen Einheiten identifiziert. Durch die Kombination der Wortbedeutung und der grammatikalischen Struktur wird schließlich die Bedeutung des Satzes ermittelt. Dies ist eine semantische Analyse. Der Verarbeitungsprozess von Compiler und Interpreter ist ähnlich, aber etwas komplizierter. Hier konzentrieren wir uns nur auf den Interpreter:
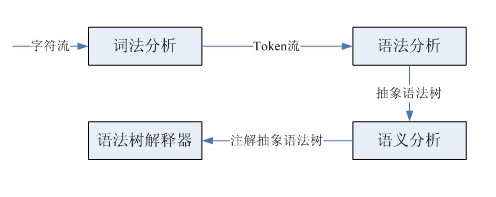
Wir implementieren lediglich eine sehr einfache kleine Sprache, daher ist die Generierung von Syntaxbäumen und die anschließende komplexe semantische Analyse nicht erforderlich. Als nächstes werde ich einen Blick auf die lexikalische Analyse und die Syntaxanalyse werfen.
Die lexikalische Analyse und die Syntaxanalyse werden jeweils durch einen lexikalischen Parser und einen Syntaxparser vervollständigt. Diese beiden Parser haben eine ähnliche Struktur und Funktionalität. Beide nehmen eine Eingabesequenz als Eingabe und identifizieren dann bestimmte Strukturen. Der lexikalische Parser analysiert Token (lexikalische Einheiten) einzeln aus dem Quellcode-Zeichenstrom, während der Syntaxparser Unterstrukturen und lexikalische Einheiten identifiziert und dann einige Verarbeitungen durchführt. Beide Parser können über LL(1)-Parser mit rekursivem Abstieg implementiert werden. Die von diesem Parsertyp ausgeführten Schritte sind: Vorhersagen des Klauseltyps, Aufrufen der Parsing-Funktion entsprechend der Unterstruktur, Anpassen der lexikalischen Einheit und anschließendes Einfügen des Codes als Benutzerdefinierte Aktionen ausführen.
Hier ist eine kurze Einführung in LL(1). Die Struktur einer Anweisung wird normalerweise durch eine Baumstruktur dargestellt, die als Analysebaum bezeichnet wird. LL(1) basiert auf dem Analysebaum für die Syntaxanalyse. Zum Beispiel: x = x 2;
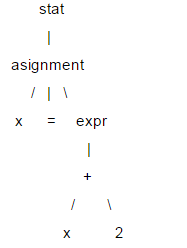
In diesem Baum werden Blattknoten wie x, = und 2 als Endknoten und die anderen als Nicht-Terminalknoten bezeichnet. Beim Parsen von LL(1) ist es nicht erforderlich, eine spezifische Baumdatenstruktur zu erstellen. Sie können für jeden Nicht-Terminalknoten eine Parsing-Funktion schreiben und diese aufrufen, wenn der entsprechende Knoten gefunden wird Funktion in der Aufrufsequenz (entspricht Tree Traversal), um Analysebauminformationen zu erhalten. Wenn LL(1) analysiert wird, wird es in der Reihenfolge vom Wurzelknoten zum Blattknoten ausgeführt, es handelt sich also um einen „absteigenden“ Prozess, und die Analysefunktion kann sich selbst aufrufen, ist also „rekursiv“, also ist LL( 1) wird auch als rekursiver Abstiegsparser bezeichnet.
Die beiden Ls in LL(1) bedeuten beide von links nach rechts. Das erste L bedeutet, dass der Parser den Eingabeinhalt in der Reihenfolge von links nach rechts analysiert. Das zweite L bedeutet, dass er während des absteigenden Prozesses auch den Eingabeinhalt analysiert Durchlaufen Sie die untergeordneten Knoten der Reihe nach nach rechts, und 1 bedeutet, Vorhersagen basierend auf 1 Lookahead-Einheit zu treffen.
Werfen wir einen Blick auf die Implementierung der Listen-Minisprache. Die erste ist die Grammatik der Sprache, die zur Beschreibung einer Sprache verwendet wird und als Designspezifikation des Parsers gilt.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
这是用DSL描述的文法,其中大部分概念和正则表达式类似。"a|b"表示a或者b,所有以单引号括起的字符串是关键字,比如:print,=等。大写的单词是词法单元。可以看到这个小语言的文法还是很简单的。有很多解析器生成器可以自动根据文法生成对应的解析器,比如:ANTRL,flex,yacc等,这里采用手写解析器主要是为了理解解析器的原理。下面看一下这个小语言的解释器是如何实现的。
首先是词法解析器,完成字符流到token流的转换。采用LL(1)实现,所以使用1个向前看字符预测匹配的token。对于像INT、ID这样由多个字符组成的词法规则,解析器有一个与之对应的方法。由于语法解析器并不关心空白字符,所以词法解析器在遇到空白字符时直接忽略掉。每个token都有两个属性类型和值,比如整型、标识符类型等,对于整型类型它的值就是该整数。语法解析器需要根据token的类型进行预测,所以词法解析必须返回类型信息。语法解析器以iterator的方式获取token,所以词法解析器实现了next_token方法,以元组方式(type, value)返回下一个token,在没有token的情况时返回EOF。
'''''
A simple lexer of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
Created on 2012-9-26
@author: bjzllou
'''
EOF = -1
# token type
COMMA = 'COMMA'
EQUAL = 'EQUAL'
LBRACK = 'LBRACK'
RBRACK = 'RBRACK'
TIMES = 'TIMES'
ADD = 'ADD'
PRINT = 'print'
ID = 'ID'
INT = 'INT'
STR = 'STR'
class Veclexer:
'''''
LL(1) lexer.
It uses only one lookahead char to determine which is next token.
For each non-terminal token, it has a rule to handle it.
LL(1) is a quit weak parser, it isn't appropriate for the grammar which is
left-recursive or ambiguity. For example, the rule 'T: T r' is left recursive.
However, it's rather simple and has high performance, and fits simple grammar.
'''
def __init__(self, input):
self.input = input
# current index of the input stream.
self.idx = 1
# lookahead char.
self.cur_c = input[0]
def next_token(self):
while self.cur_c != EOF:
c = self.cur_c
if c.isspace():
self.consume()
elif c == '[':
self.consume()
return (LBRACK, c)
elif c == ']':
self.consume()
return (RBRACK, c)
elif c == ',':
self.consume()
return (COMMA, c)
elif c == '=':
self.consume()
return (EQUAL, c)
elif c == '*':
self.consume()
return (TIMES, c)
elif c == '+':
self.consume()
return (ADD, c)
elif c == '\'' or c == '"':
return self._string()
elif c.isdigit():
return self._int()
elif c.isalpha():
t = self._print()
return t if t else self._id()
else:
raise Exception('not support token')
return (EOF, 'EOF')
def has_next(self):
return self.cur_c != EOF
def _id(self):
n = self.cur_c
self.consume()
while self.cur_c.isalpha():
n += self.cur_c
self.consume()
return (ID, n)
def _int(self):
n = self.cur_c
self.consume()
while self.cur_c.isdigit():
n += self.cur_c
self.consume()
return (INT, int(n))
def _print(self):
n = self.input[self.idx - 1 : self.idx + 4]
if n == 'print':
self.idx += 4
self.cur_c = self.input[self.idx]
return (PRINT, n)
return None
def _string(self):
quotes_type = self.cur_c
self.consume()
s = ''
while self.cur_c != '\n' and self.cur_c != quotes_type:
s += self.cur_c
self.consume()
if self.cur_c != quotes_type:
raise Exception('string quotes is not matched. excepted %s' % quotes_type)
self.consume()
return (STR, s)
def consume(self):
if self.idx >= len(self.input):
self.cur_c = EOF
return
self.cur_c = self.input[self.idx]
self.idx += 1
if __name__ == '__main__':
exp = '''''
veca = [1, 2, 3]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
'''
lex = Veclexer(exp)
t = lex.next_token()
while t[0] != EOF:
print t
t = lex.next_token()
运行这个程序,可以得到源代码:
veca = [1, 2, 3] print 'veca:', veca print 'veca * 2:', veca * 2 print 'veca + 2:', veca + 2
对应的token序列:
('ID', 'veca')
('EQUAL', '=')
('LBRACK', '[')
('INT', 1)
('COMMA', ',')
('INT', 2)
('COMMA', ',')
('INT', 3)
('RBRACK', ']')
('print', 'print')
('STR', 'veca:')
('COMMA', ',')
('ID', 'veca')
('print', 'print')
('STR', 'veca * 2:')
('COMMA', ',')
('ID', 'veca')
('TIMES', '*')
('INT', 2)
('print', 'print')
('STR', 'veca + 2:')
('COMMA', ',')
('ID', 'veca')
('ADD', '+')
('INT', 2)
接下来看一下语法解析器的实现。语法解析器的的输入是token流,根据一个向前看词法单元预测匹配的规则。对于每个遇到的非终结符调用对应的解析函数,而终结符(token)则match掉,如果不匹配则表示有语法错误。由于都是使用的LL(1),所以和词法解析器类似, 这里不再赘述。
'''''
A simple parser of a small vector language.
statlist: stat+
stat: ID '=' expr
| 'print' expr (, expr)*
expr: multipart ('+' multipart)*
| STR
multipart: primary ('*' primary)*
primary: INT
| ID
| '[' expr (',', expr)* ']'
INT: (1..9)(0..9)*
ID: (a..z | A..Z)*
STR: (\".*\") | (\'.*\')
example:
veca = [1, 2, 3]
vecb = veca + 4 # vecb: [1, 2, 3, 4]
vecc = veca * 3 # vecc:
Created on 2012-9-26
@author: bjzllou
'''
import veclexer
class Vecparser:
'''''
LL(1) parser.
'''
def __init__(self, lexer):
self.lexer = lexer
# lookahead token. Based on the lookahead token to choose the parse option.
self.cur_token = lexer.next_token()
# similar to symbol table, here it's only used to store variables' value
self.symtab = {}
def statlist(self):
while self.lexer.has_next():
self.stat()
def stat(self):
token_type, token_val = self.cur_token
# Asignment
if token_type == veclexer.ID:
self.consume()
# For the terminal token, it only needs to match and consume.
# If it's not matched, it means that is a syntax error.
self.match(veclexer.EQUAL)
# Store the value to symbol table.
self.symtab[token_val] = self.expr()
# print statement
elif token_type == veclexer.PRINT:
self.consume()
v = str(self.expr())
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v += ' ' + str(self.expr())
print v
else:
raise Exception('not support token %s', token_type)
def expr(self):
token_type, token_val = self.cur_token
if token_type == veclexer.STR:
self.consume()
return token_val
else:
v = self.multipart()
while self.cur_token[0] == veclexer.ADD:
self.consume()
v1 = self.multipart()
if type(v1) == int:
v.append(v1)
elif type(v1) == list:
v = v + v1
return v
def multipart(self):
v = self.primary()
while self.cur_token[0] == veclexer.TIMES:
self.consume()
v1 = self.primary()
if type(v1) == int:
v = [x*v1 for x in v]
elif type(v1) == list:
v = [x*y for x in v for y in v1]
return v
def primary(self):
token_type = self.cur_token[0]
token_val = self.cur_token[1]
# int
if token_type == veclexer.INT:
self.consume()
return token_val
# variables reference
elif token_type == veclexer.ID:
self.consume()
if token_val in self.symtab:
return self.symtab[token_val]
else:
raise Exception('undefined variable %s' % token_val)
# parse list
elif token_type == veclexer.LBRACK:
self.match(veclexer.LBRACK)
v = [self.expr()]
while self.cur_token[0] == veclexer.COMMA:
self.match(veclexer.COMMA)
v.append(self.expr())
self.match(veclexer.RBRACK)
return v
def consume(self):
self.cur_token = self.lexer.next_token()
def match(self, token_type):
if self.cur_token[0] == token_type:
self.consume()
return True
raise Exception('expecting %s; found %s' % (token_type, self.cur_token[0]))
if __name__ == '__main__':
prog = '''''
veca = [1, 2, 3]
vecb = [4, 5, 6]
print 'veca:', veca
print 'veca * 2:', veca * 2
print 'veca + 2:', veca + 2
print 'veca + vecb:', veca + vecb
print 'veca + [11, 12]:', veca + [11, 12]
print 'veca * vecb:', veca * vecb
print 'veca:', veca
print 'vecb:', vecb
'''
lex = veclexer.Veclexer(prog)
parser = Vecparser(lex)
parser.statlist()
运行代码便会得到之前介绍中的输出内容。这个解释器极其简陋,只实现了基本的表达式操作,所以不需要构建语法树。如果要为列表语言添加控制结构,就必须实现语法树,在语法树的基础上去解释执行。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie kann ich die gesamte Spalte eines Datenrahmens effizient in einen anderen Datenrahmen mit verschiedenen Strukturen in Python kopieren?
Apr 01, 2025 pm 11:15 PM
Wie kann ich die gesamte Spalte eines Datenrahmens effizient in einen anderen Datenrahmen mit verschiedenen Strukturen in Python kopieren?
Apr 01, 2025 pm 11:15 PM
Bei der Verwendung von Pythons Pandas -Bibliothek ist das Kopieren von ganzen Spalten zwischen zwei Datenrahmen mit unterschiedlichen Strukturen ein häufiges Problem. Angenommen, wir haben zwei Daten ...
 Können Python -Parameteranmerkungen Zeichenfolgen verwenden?
Apr 01, 2025 pm 08:39 PM
Können Python -Parameteranmerkungen Zeichenfolgen verwenden?
Apr 01, 2025 pm 08:39 PM
Alternative Verwendung von Python -Parameteranmerkungen in der Python -Programmierung, Parameteranmerkungen sind eine sehr nützliche Funktion, die den Entwicklern helfen kann, Funktionen besser zu verstehen und zu verwenden ...
 Wie lösten Python -Skripte an einem bestimmten Ort die Ausgabe in Cursorposition?
Apr 01, 2025 pm 11:30 PM
Wie lösten Python -Skripte an einem bestimmten Ort die Ausgabe in Cursorposition?
Apr 01, 2025 pm 11:30 PM
Wie lösten Python -Skripte an einem bestimmten Ort die Ausgabe in Cursorposition? Beim Schreiben von Python -Skripten ist es üblich, die vorherige Ausgabe an die Cursorposition zu löschen ...
 Warum kann mein Code nicht die von der API zurückgegebenen Daten erhalten? Wie löst ich dieses Problem?
Apr 01, 2025 pm 08:09 PM
Warum kann mein Code nicht die von der API zurückgegebenen Daten erhalten? Wie löst ich dieses Problem?
Apr 01, 2025 pm 08:09 PM
Warum kann mein Code nicht die von der API zurückgegebenen Daten erhalten? Bei der Programmierung stoßen wir häufig auf das Problem der Rückgabe von Nullwerten, wenn API aufruft, was nicht nur verwirrend ist ...
 Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen ohne Serving_forver () an?
Apr 01, 2025 pm 10:51 PM
Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen ohne Serving_forver () an?
Apr 01, 2025 pm 10:51 PM
Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen an? Uvicorn ist ein leichter Webserver, der auf ASGI basiert. Eine seiner Kernfunktionen ist es, auf HTTP -Anfragen zu hören und weiterzumachen ...
 Wie erstelle ich dynamisch ein Objekt über eine Zeichenfolge und rufe seine Methoden in Python auf?
Apr 01, 2025 pm 11:18 PM
Wie erstelle ich dynamisch ein Objekt über eine Zeichenfolge und rufe seine Methoden in Python auf?
Apr 01, 2025 pm 11:18 PM
Wie erstellt in Python ein Objekt dynamisch über eine Zeichenfolge und ruft seine Methoden auf? Dies ist eine häufige Programmieranforderung, insbesondere wenn sie konfiguriert oder ausgeführt werden muss ...
 Wie kann man Go oder Rost verwenden, um Python -Skripte anzurufen, um eine echte parallele Ausführung zu erreichen?
Apr 01, 2025 pm 11:39 PM
Wie kann man Go oder Rost verwenden, um Python -Skripte anzurufen, um eine echte parallele Ausführung zu erreichen?
Apr 01, 2025 pm 11:39 PM
Wie kann man Go oder Rost verwenden, um Python -Skripte anzurufen, um eine echte parallele Ausführung zu erreichen? Vor kurzem habe ich Python verwendet ...
 Wo kann man Python .WHL -Dateien unter Windows herunterladen?
Apr 01, 2025 pm 08:18 PM
Wo kann man Python .WHL -Dateien unter Windows herunterladen?
Apr 01, 2025 pm 08:18 PM
Python Binary Library (.WHL) -Download -Methode untersucht die Schwierigkeiten, die viele Python -Entwickler bei der Installation bestimmter Bibliotheken auf Windows -Systemen auftreten. Eine gemeinsame Lösung ...
