
 Backend-Entwicklung
Python-Tutorial
Detaillierte Erläuterung der Verwendung des integrierten Protokollierungsmoduls in Python
Backend-Entwicklung
Python-Tutorial
Detaillierte Erläuterung der Verwendung des integrierten Protokollierungsmoduls in Python
Detaillierte Erläuterung der Verwendung des integrierten Protokollierungsmoduls in Python

Einführung in das Protokollierungsmodul
Das Protokollierungsmodul von Python bietet ein allgemeines Protokollierungssystem, das von Modulen oder Anwendungen von Drittanbietern verwendet werden kann. Dieses Modul bietet verschiedene Protokollebenen und kann Protokolle auf unterschiedliche Weise aufzeichnen, z. B. Dateien, HTTP GET/POST, SMTP, Socket usw. Sie können sogar bestimmte Protokollierungsmethoden selbst implementieren.
Der Mechanismus des Protokollierungsmoduls und von log4j ist derselbe, die spezifischen Implementierungsdetails sind jedoch unterschiedlich. Das Modul bietet Logger, Handler, Filter und Formatierer.
- Logger: Stellt eine Protokollschnittstelle zur Verwendung durch Anwendungscode bereit. Die am häufigsten verwendeten Logger-Vorgänge lassen sich in zwei Kategorien einteilen: Konfiguration und Senden von Protokollnachrichten. Sie können das Logger-Objekt über logging.getLogger(name) abrufen. Wenn der Name nicht angegeben ist, wird das Stammobjekt zurückgegeben. Wenn Sie die getLogger-Methode mehrmals mit demselben Namen aufrufen, wird dasselbe Logger-Objekt zurückgegeben.
- Handler: Protokolldatensätze an entsprechende Ziele senden, z. B. Dateien, Sockets usw. Ein Logger-Objekt kann über die addHandler-Methode 0 zu mehreren Handlern hinzufügen, und jeder Handler kann unterschiedliche Protokollebenen definieren, um eine hierarchische Filterung und Anzeige von Protokollen zu erreichen.
- Filter: Bietet eine elegante Möglichkeit zu bestimmen, ob ein Protokolldatensatz an den Handler gesendet wird.
- Formatierer: Geben Sie das spezifische Format der Protokollausgabe an. Der Konstruktor des Formatierers erfordert zwei Parameter: die Formatzeichenfolge der Nachricht und die Datumszeichenfolge, die beide optional sind.
Ähnlich wie bei log4j können Aufrufe von Loggern, Handlern und Protokollnachrichten nur dann bestimmte Protokollebenen (Level) haben, wenn die Ebene der Protokollnachricht größer als die Ebene des Loggers und Handlers ist.
Protokollierungsnutzungsanalyse
1. Initialisieren Sie logger = logging.getLogger("endlesscode"). Fügen Sie am besten den Namen des zu protokollierenden Moduls nach der Methode getLogger() hinzu das Modul hier. Name
2. Legen Sie die Ebene logger.setLevel(logging.DEBUG) fest: NOTSET <
3. Handler, häufig verwendet werden StreamHandler und FileHandler. Unter Windows können Sie einfach verstehen, dass einer das Konsolen- und Dateiprotokoll ist, einer im CMD-Fenster gedruckt wird und der andere in einer Datei aufgezeichnet wird
4. Formatierer, der die Reihenfolge, Struktur und den Inhalt der endgültigen Protokollinformationen definiert. Ich verwende gerne dieses Format: „[%(asctime)s] [%(levelname)s] %(message)s“, „%Y-“. %m -%d %H:%M:%S',
%(name)s Name des Loggers
%(levelname)s Protokollebene in Textform
%(message)s Vom Benutzer ausgegebene Nachrichten
%(asctime)s Die aktuelle Zeit als String. Das Standardformat ist „2003-07-08 16:49:45,896“. Was auf das Komma folgt, sind Millisekunden
%(levelno)s Protokollebene in numerischer Form
%(Pfadname)s Der vollständige Pfadname des Moduls, das die Protokollausgabefunktion aufruft, darf nicht
enthalten
%(filename)s Der Dateiname des Moduls, das die Protokollausgabefunktion
aufruft
%(module)s Der Modulname, der die Protokollausgabefunktion aufruft
%(funcName)s ist der Funktionsname zum Aufrufen der Protokollausgabefunktion
%(lineno)d Die Codezeile, in der sich die Anweisung befindet, die die Protokollausgabefunktion aufruft
%(erstellt)f aktuelle Zeit, dargestellt durch eine UNIX-Standard-Gleitkommazahl, die die Zeit
darstellt
%(relativeCreated)d Bei der Ausgabe von Protokollinformationen die Anzahl der Millisekunden seit der Erstellung des Loggers
%(thread)d Thread-ID. Wahrscheinlich nicht
%(threadName)s Thread-Name. Wahrscheinlich nicht
%(process)d Prozess-ID. Wahrscheinlich nicht
5. Aufzeichnen Verwenden Sie object.debug(message), um Protokolle aufzuzeichnen
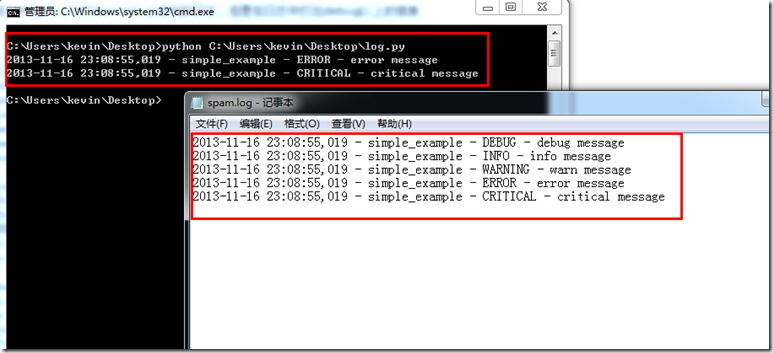
Schreiben wir unten ein Beispiel. Im CMD-Fenster werden nur Protokolle mit der Stufe „Fehler“ oder höher gedruckt, aber Informationen mit der Stufe „Debug“ werden im Protokoll
gedruckt
import logging
logger = logging.getLogger("simple_example")
logger.setLevel(logging.DEBUG)
# 建立一个filehandler来把日志记录在文件里,级别为debug以上
fh = logging.FileHandler("spam.log")
fh.setLevel(logging.DEBUG)
# 建立一个streamhandler来把日志打在CMD窗口上,级别为error以上
ch = logging.StreamHandler()
ch.setLevel(logging.ERROR)
# 设置日志格式
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
ch.setFormatter(formatter)
fh.setFormatter(formatter)
#将相应的handler添加在logger对象中
logger.addHandler(ch)
logger.addHandler(fh)
# 开始打日志
logger.debug("debug message")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
logger.critical("critical message")
#! /usr/bin/env python
#coding=gbk
import logging,os
class Logger:
def __init__(self, path,clevel = logging.DEBUG,Flevel = logging.DEBUG):
self.logger = logging.getLogger(path)
self.logger.setLevel(logging.DEBUG)
fmt = logging.Formatter('[%(asctime)s] [%(levelname)s] %(message)s', '%Y-%m-%d %H:%M:%S')
#设置CMD日志
sh = logging.StreamHandler()
sh.setFormatter(fmt)
sh.setLevel(clevel)
#设置文件日志
fh = logging.FileHandler(path)
fh.setFormatter(fmt)
fh.setLevel(Flevel)
self.logger.addHandler(sh)
self.logger.addHandler(fh)
def debug(self,message):
self.logger.debug(message)
def info(self,message):
self.logger.info(message)
def war(self,message):
self.logger.warn(message)
def error(self,message):
self.logger.error(message)
def cri(self,message):
self.logger.critical(message)
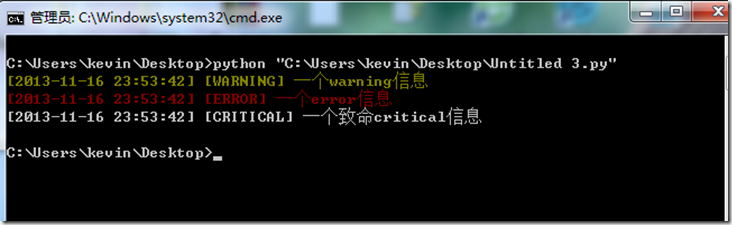
if __name__ =='__main__':
logyyx = Logger('yyx.log',logging.ERROR,logging.DEBUG)
logyyx.debug('一个debug信息')
logyyx.info('一个info信息')
logyyx.war('一个warning信息')
logyyx.error('一个error信息')
logyyx.cri('一个致命critical信息')
logobj = Logger(‘filename',clevel,Flevel)
verwenden
#! /usr/bin/env python
#coding=gbk
import logging,os
import ctypes
FOREGROUND_WHITE = 0x0007
FOREGROUND_BLUE = 0x01 # text color contains blue.
FOREGROUND_GREEN= 0x02 # text color contains green.
FOREGROUND_RED = 0x04 # text color contains red.
FOREGROUND_YELLOW = FOREGROUND_RED | FOREGROUND_GREEN
STD_OUTPUT_HANDLE= -11
std_out_handle = ctypes.windll.kernel32.GetStdHandle(STD_OUTPUT_HANDLE)
def set_color(color, handle=std_out_handle):
bool = ctypes.windll.kernel32.SetConsoleTextAttribute(handle, color)
return bool
class Logger:
def __init__(self, path,clevel = logging.DEBUG,Flevel = logging.DEBUG):
self.logger = logging.getLogger(path)
self.logger.setLevel(logging.DEBUG)
fmt = logging.Formatter('[%(asctime)s] [%(levelname)s] %(message)s', '%Y-%m-%d %H:%M:%S')
#设置CMD日志
sh = logging.StreamHandler()
sh.setFormatter(fmt)
sh.setLevel(clevel)
#设置文件日志
fh = logging.FileHandler(path)
fh.setFormatter(fmt)
fh.setLevel(Flevel)
self.logger.addHandler(sh)
self.logger.addHandler(fh)
def debug(self,message):
self.logger.debug(message)
def info(self,message):
self.logger.info(message)
def war(self,message,color=FOREGROUND_YELLOW):
set_color(color)
self.logger.warn(message)
set_color(FOREGROUND_WHITE)
def error(self,message,color=FOREGROUND_RED):
set_color(color)
self.logger.error(message)
set_color(FOREGROUND_WHITE)
def cri(self,message):
self.logger.critical(message)
if __name__ =='__main__':
logyyx = Logger('yyx.log',logging.WARNING,logging.DEBUG)
logyyx.debug('一个debug信息')
logyyx.info('一个info信息')
logyyx.war('一个warning信息')
logyyx.error('一个error信息')
logyyx.cri('一个致命critical信息')
Protokollierung mit mehreren Modulen verwenden
Das Protokollierungsmodul garantiert, dass innerhalb desselben Python-Interpreters mehrere Aufrufe von logging.getLogger('log_name') dieselbe Logger-Instanz zurückgeben, selbst im Fall mehrerer Module. Daher besteht die typische Methode zur Verwendung der Protokollierung in einem Szenario mit mehreren Modulen darin, die Protokollierung im Hauptmodul zu konfigurieren. Diese Konfiguration wirkt sich auf mehrere Untermodule aus und erhält dann das Logger-Objekt direkt über getLogger in anderen Modulen.
Konfigurationsdatei:
[loggers]
keys=root,main
[handlers]
keys=consoleHandler,fileHandler
[formatters]
keys=fmt
[logger_root]
level=DEBUG
handlers=consoleHandler
[logger_main]
level=DEBUG
qualname=main
handlers=fileHandler
[handler_consoleHandler]
class=StreamHandler
level=DEBUG
formatter=fmt
args=(sys.stdout,)
[handler_fileHandler]
class=logging.handlers.RotatingFileHandler
level=DEBUG
formatter=fmt
args=('tst.log','a',20000,5,)
[formatter_fmt]
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
datefmt=
import logging
import logging.config
logging.config.fileConfig('logging.conf')
root_logger = logging.getLogger('root')
root_logger.debug('test root logger...')
logger = logging.getLogger('main')
logger.info('test main logger')
logger.info('start import module \'mod\'...')
import mod
logger.debug('let\'s test mod.testLogger()')
mod.testLogger()
root_logger.info('finish test...')
import logging
import submod
logger = logging.getLogger('main.mod')
logger.info('logger of mod say something...')
def testLogger():
logger.debug('this is mod.testLogger...')
submod.tst()
import logging
logger = logging.getLogger('main.mod.submod')
logger.info('logger of submod say something...')
def tst():
logger.info('this is submod.tst()...')
然后运行python main.py,控制台输出:
2012-03-09 18:22:22,793 - root - DEBUG - test root logger... 2012-03-09 18:22:22,793 - main - INFO - test main logger 2012-03-09 18:22:22,809 - main - INFO - start import module 'mod'... 2012-03-09 18:22:22,809 - main.mod.submod - INFO - logger of submod say something... 2012-03-09 18:22:22,809 - main.mod - INFO - logger say something... 2012-03-09 18:22:22,809 - main - DEBUG - let's test mod.testLogger() 2012-03-09 18:22:22,825 - main.mod - DEBUG - this is mod.testLogger... 2012-03-09 18:22:22,825 - main.mod.submod - INFO - this is submod.tst()... 2012-03-09 18:22:22,841 - root - INFO - finish test...
可以看出,和预想的一样,然后在看一下tst.log,logger配置中的输出的目的地:
2012-03-09 18:22:22,793 - main - INFO - test main logger 2012-03-09 18:22:22,809 - main - INFO - start import module 'mod'... 2012-03-09 18:22:22,809 - main.mod.submod - INFO - logger of submod say something... 2012-03-09 18:22:22,809 - main.mod - INFO - logger say something... 2012-03-09 18:22:22,809 - main - DEBUG - let's test mod.testLogger() 2012-03-09 18:22:22,825 - main.mod - DEBUG - this is mod.testLogger... 2012-03-09 18:22:22,825 - main.mod.submod - INFO - this is submod.tst()...
tst.log中没有root logger输出的信息,因为logging.conf中配置了只有main logger及其子logger使用RotatingFileHandler,而root logger是输出到标准输出。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Minio-Objektspeicherung: Hochleistungs-Bereitstellung im Rahmen von CentOS System Minio ist ein hochleistungsfähiges, verteiltes Objektspeichersystem, das auf der GO-Sprache entwickelt wurde und mit Amazons3 kompatibel ist. Es unterstützt eine Vielzahl von Kundensprachen, darunter Java, Python, JavaScript und Go. In diesem Artikel wird kurz die Installation und Kompatibilität von Minio zu CentOS -Systemen vorgestellt. CentOS -Versionskompatibilitätsminio wurde in mehreren CentOS -Versionen verifiziert, einschließlich, aber nicht beschränkt auf: CentOS7.9: Bietet einen vollständigen Installationshandbuch für die Clusterkonfiguration, die Umgebungsvorbereitung, die Einstellungen von Konfigurationsdateien, eine Festplattenpartitionierung und Mini
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
Bei der Installation von PyTorch am CentOS -System müssen Sie die entsprechende Version sorgfältig auswählen und die folgenden Schlüsselfaktoren berücksichtigen: 1. Kompatibilität der Systemumgebung: Betriebssystem: Es wird empfohlen, CentOS7 oder höher zu verwenden. CUDA und CUDNN: Pytorch -Version und CUDA -Version sind eng miteinander verbunden. Beispielsweise erfordert Pytorch1.9.0 CUDA11.1, während Pytorch2.0.1 CUDA11.3 erfordert. Die Cudnn -Version muss auch mit der CUDA -Version übereinstimmen. Bestimmen Sie vor der Auswahl der Pytorch -Version unbedingt, dass kompatible CUDA- und CUDNN -Versionen installiert wurden. Python -Version: Pytorch Official Branch
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
