
 Backend-Entwicklung
Python-Tutorial
Verwenden Sie Python2 und Python3, um Browser zu verschleiern und Webinhalte zu crawlen
Backend-Entwicklung
Python-Tutorial
Verwenden Sie Python2 und Python3, um Browser zu verschleiern und Webinhalte zu crawlen
Verwenden Sie Python2 und Python3, um Browser zu verschleiern und Webinhalte zu crawlen
Oct 18, 2016 pm 01:55 PMDie Python-Webseiten-Crawling-Funktion ist sehr leistungsstark. Sie können urllib oder urllib2 verwenden, um den Inhalt von Webseiten einfach zu crawlen. Oft müssen wir jedoch darauf achten, dass viele Websites möglicherweise über Anti-Collection-Funktionen verfügen, sodass es nicht so einfach ist, die gewünschten Inhalte zu erfassen.
Heute werde ich zeigen, wie man Browser simuliert, um beim Herunterladen von Python2 und Python3 das Blockieren und Crawlen zu überspringen.
Das grundlegendste Crawlen:
#! /usr/bin/env python # -*- coding=utf-8 -*- # @Author pythontab import urllib.request url = "http://www.pythontab.com" html = urllib.request.urlopen(url).read() print(html)
Aber... einige Websites können nicht gecrawlt werden und verfügen über Anti-Sammeleinstellungen, daher müssen wir die Methode ändern
Python2 Mittel (die neueste stabile Version python2.7)
#! /usr/bin/env python
# -*- coding=utf-8 -*-
# @Author pythontab.com
import urllib2
url="http://pythontab.com"
req_header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept':'text/html;q=0.9,*/*;q=0.8',
'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding':'gzip',
'Connection':'close',
'Referer':None #注意如果依然不能抓取的话,这里可以设置抓取网站的host
}
req_timeout = 5
req = urllib2.Request(url,None,req_header)
resp = urllib2.urlopen(req,None,req_timeout)
html = resp.read()
print(html)python3 Mittel (die neueste stabile Version python3.3)
#! /usr/bin/env python
# -*- coding=utf-8 -*-
# @Author pythontab
import urllib.request
url = "http://www.pythontab.com"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept':'text/html;q=0.9,*/*;q=0.8',
'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding':'gzip',
'Connection':'close',
'Referer':None #注意如果依然不能抓取,这里可以设置抓取网站的host
}
opener = urllib.request.build_opener()
opener.addheaders = [headers]
data = opener.open(url).read()
print(data)
Heißer Artikel

Hot-Tools-Tags

Heißer Artikel

Heiße Artikel -Tags

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie ändere ich den Browser auf die Computerversion der Seite? Wie stelle ich den mobilen Browser auf die Computerversion der Seite ein?
Mar 20, 2024 pm 04:31 PM
Wie ändere ich den Browser auf die Computerversion der Seite? Wie stelle ich den mobilen Browser auf die Computerversion der Seite ein?
Mar 20, 2024 pm 04:31 PM
Wie ändere ich den Browser auf die Computerversion der Seite? Wie stelle ich den mobilen Browser auf die Computerversion der Seite ein?
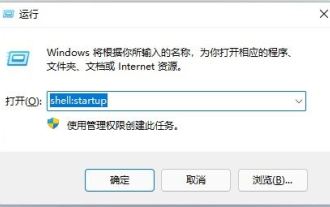 Wie stelle ich den Browser so ein, dass er beim Booten automatisch startet?
Jun 12, 2024 pm 07:58 PM
Wie stelle ich den Browser so ein, dass er beim Booten automatisch startet?
Jun 12, 2024 pm 07:58 PM
Wie stelle ich den Browser so ein, dass er beim Booten automatisch startet?
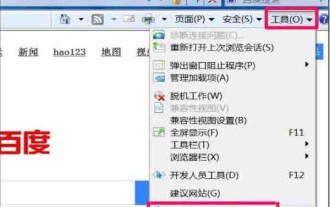 Schritte zur Lösung des Problems, dass der Win7-Systembrowser die Webseite immer automatisch öffnet
Mar 26, 2024 pm 09:30 PM
Schritte zur Lösung des Problems, dass der Win7-Systembrowser die Webseite immer automatisch öffnet
Mar 26, 2024 pm 09:30 PM
Schritte zur Lösung des Problems, dass der Win7-Systembrowser die Webseite immer automatisch öffnet
 Sesame Open Door Offizielle Website Sesam Open Door App Neueintrittswebsite
Feb 28, 2025 am 11:18 AM
Sesame Open Door Offizielle Website Sesam Open Door App Neueintrittswebsite
Feb 28, 2025 am 11:18 AM
Sesame Open Door Offizielle Website Sesam Open Door App Neueintrittswebsite
 Löschen Sie die Google Chrome-Registrierung und bereinigen Sie die verbleibenden Rückstände bei der Deinstallation von Google Chrome
Jun 19, 2024 am 11:09 AM
Löschen Sie die Google Chrome-Registrierung und bereinigen Sie die verbleibenden Rückstände bei der Deinstallation von Google Chrome
Jun 19, 2024 am 11:09 AM
Löschen Sie die Google Chrome-Registrierung und bereinigen Sie die verbleibenden Rückstände bei der Deinstallation von Google Chrome
 Die neueste Version von Sesame Open Door Offizielle Website Eingang Gate.io offizielle Website Linkadresse Eingang Eingang
Feb 28, 2025 am 11:21 AM
Die neueste Version von Sesame Open Door Offizielle Website Eingang Gate.io offizielle Website Linkadresse Eingang Eingang
Feb 28, 2025 am 11:21 AM
Die neueste Version von Sesame Open Door Offizielle Website Eingang Gate.io offizielle Website Linkadresse Eingang Eingang
 Gate.io Sesam -Tür herunterladen Chinesisches Tutorial
Feb 28, 2025 am 10:54 AM
Gate.io Sesam -Tür herunterladen Chinesisches Tutorial
Feb 28, 2025 am 10:54 AM
Gate.io Sesam -Tür herunterladen Chinesisches Tutorial
 Gründe und Lösungen für eine langsame Browser-Netzwerkgeschwindigkeit (Untersuchung der Gründe für eine langsame Browser-Netzwerkgeschwindigkeit)
Apr 25, 2024 pm 03:49 PM
Gründe und Lösungen für eine langsame Browser-Netzwerkgeschwindigkeit (Untersuchung der Gründe für eine langsame Browser-Netzwerkgeschwindigkeit)
Apr 25, 2024 pm 03:49 PM
Gründe und Lösungen für eine langsame Browser-Netzwerkgeschwindigkeit (Untersuchung der Gründe für eine langsame Browser-Netzwerkgeschwindigkeit)
