

Java-Verbesserungskapitel (33) ----- Kartenzusammenfassung

Zuvor stellte LZ die Implementierungsmethoden von HashMap, HashTable und TreeMap ausführlich vor und erläuterte sie unter drei Aspekten: Datenstruktur, Implementierungsprinzip und Quellcodeanalyse. Sie sollten diese besser verstehen Im Folgenden gibt LZ eine kurze Zusammenfassung der Karte.
Empfohlene Lektüre:
Java Improvement Chapter (Teil 2) 3) —-HashMap
>
Java-Verbesserungskapitel (26)-----hashCode
Java-Verbesserungskapitel (27) – TreeMap1. Übersicht über die Karte
Schauen Sie sich zunächst das Strukturdiagramm von Map an

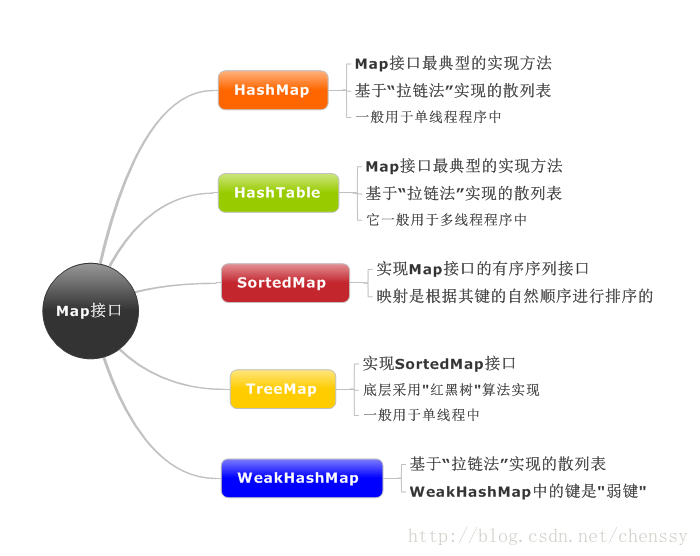
Karte: Abstrakte Schnittstelle für „Schlüssel-Wert“-Zuordnung. Die Karte enthält keine doppelten Schlüssel, ein Schlüssel entspricht einem Wert.
SortedMap: Geordnete Schlüssel-Wert-Paar-Schnittstelle, die die Map-Schnittstelle erbt.
NavigableMap: erbt SortedMap und verfügt über eine Navigationsmethode, die die nächstgelegene Übereinstimmung für eine bestimmte Suchzielschnittstelle zurückgibt .
AbstractMap: implementiert die meisten funktionalen Schnittstellen in Map. Es reduziert die wiederholte Codierung der „Map-Implementierungsklasse“.
Wörterbuch: Die abstrakte übergeordnete Klasse jeder Klasse, die Schlüssel entsprechenden Werten zuordnet. Derzeit durch die Kartenschnittstelle ersetzt.
TreeMap: Geordnete Hash-Tabelle, implementiert die SortedMap-Schnittstelle und die untere Ebene wird durch ein Rot implementiert -Schwarzer Baum.
HashMap: ist eine Hash-Tabelle, die auf Basis der „Zipper-Methode“ implementiert ist. Die unterste Ebene wird mit „Array + verknüpfte Liste“ implementiert.
WeakHashMap: Eine auf der „Zipper-Methode“ implementierte Hash-Tabelle.
HashTable: Eine auf der „Zipper-Methode“ implementierte Hash-Tabelle.
Die Zusammenfassung lautet wie folgt:
Der Unterschied zwischen ihnen:
Für uns Programmierer müssen wir es verstehen. Hash-Mapping-Technologie ist eine sehr einfache Technologie, die Elemente Arrays zuordnet. Da die Hash-Map ein Array-Ergebnis verwendet, muss ein Indexierungsmechanismus vorhanden sein, um den Zugriff auf das Array durch einen beliebigen Schlüssel zu bestimmen. Dieser Mechanismus kann eine Ganzzahl bereitstellen, die kleiner als die Größe des Arrays ist. In Java müssen wir uns nicht darum kümmern, eine solche Ganzzahl zu finden, da jedes Objekt über eine hashCode-Methode verfügen muss, die einen Ganzzahlwert zurückgibt. Wir müssen ihn lediglich in eine Ganzzahl umwandeln und den Wert dann durch das Array Just dividieren Nehmen Sie den Rest von der Größe. Wie folgt: Der Index der Position repräsentiert die Position des Knotens im Array. Die folgende Abbildung ist das Grundprinzipdiagramm der Hash-Zuordnung: Die Put-Methode von HashMap zeigt die Grundidee des Hash-Mappings. Wenn wir uns andere Maps ansehen, stellen wir tatsächlich fest, dass die Prinzipien ähnlich sind! Die Größe beträgt nur 1 und alle Elemente werden dieser Position zugeordnet (0 ), wodurch eine längere verknüpfte Liste entsteht. Da wir beim Aktualisieren und Zugreifen eine lineare Suche in dieser verknüpften Liste durchführen müssen, verringert dies zwangsläufig die Effizienz. Wir gehen davon aus, dass bei einem sehr großen Array und nur einem Element an jeder Position in der verknüpften Liste das Objekt beim Zugriff durch Berechnen seines Indexwerts ermittelt wird. Dies verbessert zwar die Effizienz unserer Suche, verursacht jedoch Verschwendung Kontrolle. Zugegebenermaßen sind diese beiden Methoden zwar extrem, liefern uns aber eine Optimierungsidee: Verwenden Sie ein größeres Array, damit die Elemente gleichmäßig verteilt werden können. Es gibt zwei Faktoren in Map, die sich auf die Effizienz auswirken. Der eine ist die anfängliche Größe des Containers und der andere ist der Auslastungsfaktor. Als „Bucket“ die Anzahl der verfügbaren Buckets (d. h. die Größe). Die Größe des internen Arrays wird als Kapazität bezeichnet. Damit das Map-Objekt effektiv eine beliebige Anzahl von Elementen verarbeiten kann, haben wir die Map so gestaltet, dass sie ihre Größe selbst anpassen kann. Wir wissen, dass die Größe des Containers selbst geändert wird, wenn die Elemente in der Karte eine bestimmte Menge erreichen. Dieser Größenänderungsprozess ist jedoch sehr kostspielig. Bei der Größenänderung müssen alle ursprünglichen Elemente in das neue Array eingefügt werden. Wir kennen index = hash(key) % Länge. Dies kann dazu führen, dass die ursprünglichen in Konflikt stehenden Schlüssel nicht mehr in Konflikt geraten und die nicht in Konflikt stehenden Schlüssel jetzt in Konflikt geraten. Der Prozess der Neuberechnung, Anpassung und Einfügung ist sehr teuer und ineffizient. Also, Wenn wir beginnen, die erwartete Größe der Karte zu kennen und die Karte groß genug zu ändern, können wir die Notwendigkeit einer Größenänderung erheblich reduzieren oder sogar eliminieren, was höchstwahrscheinlich die Geschwindigkeit verbessern wird. Das Folgende ist der Prozess der HashMap-Anpassung der Containergröße. Anhand des folgenden Codes können wir die Komplexität seines Erweiterungsprozesses erkennen: 为了确认何时需要调整Map容器,Map使用了一个额外的参数并且粗略计算存储容器的密度。在Map调整大小之前,使用”负载因子”来指示Map将会承担的“负载量”,也就是它的负载程度,当容器中元素的数量达到了这个“负载量”,则Map将会进行扩容操作。负载因子、容量、Map大小之间的关系如下:负载因子 * 容量 > map大小 ----->调整Map大小。 例如:如果负载因子大小为0.75(HashMap的默认值),默认容量为11,则 11 * 0.75 = 8.25 = 8,所以当我们容器中插入第八个元素的时候,Map就会调整大小。 负载因子本身就是在控件和时间之间的折衷。当我使用较小的负载因子时,虽然降低了冲突的可能性,使得单个链表的长度减小了,加快了访问和更新的速度,但是它占用了更多的控件,使得数组中的大部分控件没有得到利用,元素分布比较稀疏,同时由于Map频繁的调整大小,可能会降低性能。但是如果负载因子过大,会使得元素分布比较紧凑,导致产生冲突的可能性加大,从而访问、更新速度较慢。所以我们一般推荐不更改负载因子的值,采用默认值0.75. 推荐阅读:
java提高篇(二三)—–HashMap java提高篇(二五)—–HashTable Java提高篇(二六)-----hashCode Java提高篇(二七)—–TreeMap
以上就是Java提高篇(三三)-----Map总结的内容,更多相关内容请关注PHP中文网(www.php.cn)!
2. Internes Hashing: Hash-Mapping-Technologie
int hashValue = Maths.abs(obj.hashCode()) % size;
----------HashMap------------
//计算hash值
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//计算key的索引位置
static int indexFor(int h, int length) {
return h & (length-1);
}
-----HashTable--------------
int index = (hash & 0x7FFFFFFF) % tab.length; //确认该key的索引位置
In dieser Abbildung dienen die Schritte 1 bis 4 dazu, das Element zu finden An der Array-Position dienen die Schritte 5 bis 8 zum Einfügen des Elements in das Array. Während des Einfügevorgangs kann es zu etwas Frustration kommen. Es können mehrere Elemente mit demselben Hashwert vorhanden sein, daher erhalten sie dieselbe Indexposition, was bedeutet, dass mehrere Elemente derselben Position zugeordnet werden. Dieser Vorgang wird als „Konflikt“ bezeichnet. Die Lösung des Konflikts besteht darin, eine verknüpfte Liste an der Indexposition einzufügen und das Element einfach zu dieser verknüpften Liste hinzuzufügen. Natürlich handelt es sich nicht um eine einfache Einfügung. Der Verarbeitungsprozess in HashMap ist wie folgt: Wenn die verknüpfte Liste null ist, fügen Sie das Element direkt ein Wenn vorhanden, wird der Wert des ursprünglichen Schlüssels überschrieben und der alte Wert zurückgegeben. Andernfalls wird das Element am Anfang der Kette gespeichert (das erste gespeicherte Element wird am Ende der Kette platziert). . Das Folgende ist die Put-Methode von HashMap, die den gesamten Prozess der Berechnung der Indexposition und des Einfügens des Elements an der entsprechenden Position im Detail zeigt: public V put(K key, V value) {
//当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key.hashCode());
//计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length);
//从i出开始迭代 e,判断是否存在相同的key
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
}
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
}3. Kartenoptimierung
void resize(int newCapacity) {
Entry[] oldTable = table; //原始容器
int oldCapacity = oldTable.length; //原始容器大小
if (oldCapacity == MAXIMUM_CAPACITY) { //是否超过最大值:1073741824
threshold = Integer.MAX_VALUE;
return;
}
//新的数组:大小为 oldCapacity * 2
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
/*
* 重新计算阀值 = newCapacity * loadFactor > MAXIMUM_CAPACITY + 1 ?
* newCapacity * loadFactor :MAXIMUM_CAPACITY + 1
*/
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
//将元素插入到新数组中
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}3.2、负载因子
最后

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
 Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Kapseln sind dreidimensionale geometrische Figuren, die aus einem Zylinder und einer Hemisphäre an beiden Enden bestehen. Das Volumen der Kapsel kann berechnet werden, indem das Volumen des Zylinders und das Volumen der Hemisphäre an beiden Enden hinzugefügt werden. In diesem Tutorial wird erörtert, wie das Volumen einer bestimmten Kapsel in Java mit verschiedenen Methoden berechnet wird. Kapselvolumenformel Die Formel für das Kapselvolumen lautet wie folgt: Kapselvolumen = zylindrisches Volumenvolumen Zwei Hemisphäre Volumen In, R: Der Radius der Hemisphäre. H: Die Höhe des Zylinders (ohne die Hemisphäre). Beispiel 1 eingeben Radius = 5 Einheiten Höhe = 10 Einheiten Ausgabe Volumen = 1570,8 Kubikeinheiten erklären Berechnen Sie das Volumen mithilfe der Formel: Volumen = π × R2 × H (4
 Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Java ist eine beliebte Programmiersprache, die sowohl von Anfängern als auch von erfahrenen Entwicklern erlernt werden kann. Dieses Tutorial beginnt mit grundlegenden Konzepten und geht dann weiter zu fortgeschrittenen Themen. Nach der Installation des Java Development Kit können Sie das Programmieren üben, indem Sie ein einfaches „Hello, World!“-Programm erstellen. Nachdem Sie den Code verstanden haben, verwenden Sie die Eingabeaufforderung, um das Programm zu kompilieren und auszuführen. Auf der Konsole wird „Hello, World!“ ausgegeben. Mit dem Erlernen von Java beginnt Ihre Programmierreise, und wenn Sie Ihre Kenntnisse vertiefen, können Sie komplexere Anwendungen erstellen.
