

【MySQL】Logische MySQL-Architektur

Wenn Sie in Ihrem Kopf ein Architekturdiagramm erstellen können, das zeigt, wie die verschiedenen Komponenten von MySQL zusammenarbeiten, wird Ihnen das dabei helfen, den MySQL-Server besser zu verstehen.
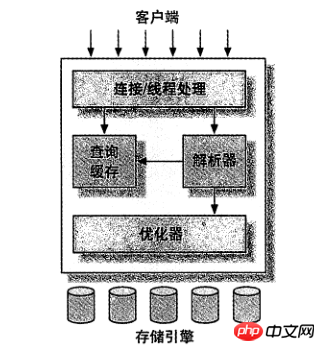
Der Top-Level-Dienst gibt es nicht nur bei MySQL, die meisten netzwerkbasierten Client/Server-Tools haben eine ähnliche Architektur. Wie Verbindungsverarbeitung, Autorisierungsauthentifizierung, Sicherheit usw.
Die Second-Layer-Architektur ist der interessantere Teil von MySQL. Die meisten Kerndienstfunktionen von MySQL befinden sich in dieser Ebene, einschließlich Abfrageanalyse, Analyse, Optimierung, Caching und allen integrierten Funktionen (z. B. Datum, Uhrzeit, Mathematik und Verschlüsselungsfunktionen). Alle speicherübergreifenden Engine-Funktionen sind vorhanden diese Ebene Implementierung: gespeicherte Prozeduren, Trigger, Ansichten usw.
Die dritte Schicht enthält die Speicher-Engine. Die Speicher-Engine ist für das Speichern und Abrufen von Daten in MySQL verantwortlich. Wie verschiedene Dateisysteme unter GNU/Linux hat jede Speicher-Engine ihre Vor- und Nachteile. Der Server kommuniziert über APIs mit der Speicher-Engine. Diese Schnittstellen schirmen die Unterschiede zwischen verschiedenen Speicher-Engines ab und machen diese Unterschiede für den Abfrageprozess der oberen Ebene transparent. Die Storage-Engine-API enthält mehr als ein Dutzend Low-Level-Funktionen zum Ausführen von Vorgängen wie „Starten einer Transaktion“ oder „Extrahieren einer Datensatzzeile basierend auf dem Primärschlüssel“. Aber die Speicher-Engine analysiert SQL nicht (Hinweis: InnoDB ist eine Ausnahme, es analysiert Fremdschlüsseldefinitionen, da der MySQL-Server selbst diese Funktion nicht implementiert), und verschiedene Speicher-Engines kommunizieren nicht miteinander, sondern antworten einfach an die Serveranforderung der oberen Schicht.
Verbindungsverwaltung und -sicherheit
Jede Client-Verbindung verfügt über einen Thread im Serverprozess. Die Abfrage für diese Verbindung wird nur in diesem separaten Thread ausgeführt, der nur abwechselnd ausgeführt werden kann ein bestimmter CPU-Kern oder eine bestimmte CPU. Der Server ist für das Zwischenspeichern von Threads verantwortlich, sodass nicht für jede neue Verbindung Threads erstellt oder zerstört werden müssen. (Hinweis: MySQL 5.5 oder höher bietet eine API, die das Thread-Pool-Plug-in unterstützt, das eine kleine Anzahl von Threads im Pool verwenden kann, um eine große Anzahl von Verbindungen zu bedienen.)
Wenn ein Client (Anwendung) eine Verbindung zum MySQL-Server herstellt, muss der Server ihn authentifizieren. Die Authentifizierung basiert auf Benutzername, ursprünglichen Hostinformationen und Passwort. Wenn Sie eine Secure Socket (SSL)-Verbindung verwenden, können Sie auch die X.509-Zertifikatauthentifizierung verwenden. Sobald der Client erfolgreich eine Verbindung hergestellt hat, überprüft der Server weiterhin, ob der Client über die Berechtigung für eine bestimmte Abfrage verfügt (z. B. ob der Client eine SELECT-Anweisung für die Ländertabelle der Weltdatenbank ausführen darf).
Optimierung und Ausführung
MySQL analysiert die Abfrage und erstellt eine interne Datenstruktur (Analysebaum) und führt dann verschiedene Optimierungen daran durch, einschließlich des Umschreibens der Abfrage und der Bestimmung der Lesereihenfolge der Tabelle sowie die Auswahl geeigneter Indizes usw. Durch spezielle Keyword-Hinweise können Nutzer Einfluss auf die Entscheidungsfindung des Optimierers nehmen. Sie können den Optimierer auch auffordern, verschiedene Faktoren im Optimierungsprozess zu erläutern, damit Benutzer wissen, wie der Server Optimierungsentscheidungen trifft, und eine Referenzbasislinie bereitstellen, um Benutzern die Rekonstruktion von Abfragen und Schemata sowie die Änderung zugehöriger Konfigurationen zu erleichtern, um die Anwendung zu erstellen möglichst effizient laufen.
Dem Optimierer ist es egal, welche Speicher-Engine verwendet wird, aber die Speicher-Engine hat Einfluss auf die Optimierung von Abfragen. Der Optimierer fordert die Speicher-Engine auf, Kapazitäts- oder Kosteninformationen zu einem bestimmten Vorgang sowie statistische Informationen zu Tabellendaten usw. bereitzustellen. Beispielsweise können bestimmte Indizes bestimmter Speicher-Engines für bestimmte Abfragen optimiert werden.
Bei SELECT-Anweisungen überprüft der Server vor dem Parsen der Abfrage zunächst den Abfragecache (Abfragecache). Wenn die entsprechende Abfrage darin gefunden werden kann, muss der Server nicht den gesamten Abfragevorgang durchführen Beim Parsen, Optimieren und Ausführen wird die Ergebnismenge im Abfragecache direkt zurückgegeben.
Wenn Sie in Ihrem Kopf ein Architekturdiagramm erstellen können, das zeigt, wie die verschiedenen Komponenten von MySQL zusammenarbeiten, wird es Ihnen helfen, den MySQL-Server tiefgreifend zu verstehen.
Der Top-Level-Dienst gibt es nicht nur bei MySQL, die meisten netzwerkbasierten Client/Server-Tools haben eine ähnliche Architektur. Wie Verbindungsverarbeitung, Autorisierungsauthentifizierung, Sicherheit usw.
Die Second-Layer-Architektur ist der interessantere Teil von MySQL. Die meisten Kerndienstfunktionen von MySQL befinden sich in dieser Ebene, einschließlich Abfrageanalyse, Analyse, Optimierung, Caching und allen integrierten Funktionen (z. B. Datum, Uhrzeit, Mathematik und Verschlüsselungsfunktionen). Alle speicherübergreifenden Engine-Funktionen sind vorhanden diese Ebene Implementierung: gespeicherte Prozeduren, Trigger, Ansichten usw.
Die dritte Schicht enthält die Speicher-Engine. Die Speicher-Engine ist für das Speichern und Abrufen von Daten in MySQL verantwortlich. Wie verschiedene Dateisysteme unter GNU/Linux hat jede Speicher-Engine ihre Vor- und Nachteile. Der Server kommuniziert über APIs mit der Speicher-Engine. Diese Schnittstellen schirmen die Unterschiede zwischen verschiedenen Speicher-Engines ab und machen diese Unterschiede für den Abfrageprozess der oberen Ebene transparent. Die Storage-Engine-API enthält mehr als ein Dutzend Low-Level-Funktionen zum Ausführen von Vorgängen wie „Starten einer Transaktion“ oder „Extrahieren einer Datensatzzeile basierend auf dem Primärschlüssel“. Aber die Speicher-Engine analysiert SQL nicht (Hinweis: InnoDB ist eine Ausnahme, es analysiert Fremdschlüsseldefinitionen, da der MySQL-Server selbst diese Funktion nicht implementiert), und verschiedene Speicher-Engines kommunizieren nicht miteinander, sondern antworten einfach an die Serveranfrage der oberen Schicht.
Verbindungsverwaltung und -sicherheit
Jede Client-Verbindung verfügt über einen Thread im Serverprozess. Die Abfrage für diese Verbindung wird nur in diesem separaten Thread ausgeführt, der nur abwechselnd ausgeführt werden kann ein bestimmter CPU-Kern oder eine bestimmte CPU. Der Server ist für das Zwischenspeichern von Threads verantwortlich, sodass nicht für jede neue Verbindung Threads erstellt oder zerstört werden müssen. (Hinweis: MySQL 5.5 oder höher bietet eine API, die das Thread-Pool-Plug-in unterstützt, das eine kleine Anzahl von Threads im Pool verwenden kann, um eine große Anzahl von Verbindungen zu bedienen.)
Wenn ein Client (eine Anwendung) eine Verbindung zum MySQL-Server herstellt, muss der Server ihn authentifizieren. Die Authentifizierung basiert auf Benutzername, ursprünglichen Hostinformationen und Passwort. Wenn Sie eine Secure Socket (SSL)-Verbindung verwenden, können Sie auch die X.509-Zertifikatauthentifizierung verwenden. Sobald der Client erfolgreich eine Verbindung hergestellt hat, überprüft der Server weiterhin, ob der Client über die Berechtigung für eine bestimmte Abfrage verfügt (z. B. ob der Client eine SELECT-Anweisung für die Ländertabelle der Weltdatenbank ausführen darf).
Optimierung und Ausführung
MySQL analysiert die Abfrage und erstellt eine interne Datenstruktur (Analysebaum) und führt dann verschiedene Optimierungen daran durch, einschließlich des Umschreibens der Abfrage und der Bestimmung der Lesereihenfolge der Tabelle sowie die Auswahl geeigneter Indizes usw. Durch spezielle Keyword-Hinweise können Nutzer Einfluss auf die Entscheidungsfindung des Optimierers nehmen. Sie können den Optimierer auch auffordern, verschiedene Faktoren im Optimierungsprozess zu erläutern, damit Benutzer wissen, wie der Server Optimierungsentscheidungen trifft, und eine Referenzbasislinie bereitstellen, um Benutzern die Rekonstruktion von Abfragen und Schemata sowie die Änderung zugehöriger Konfigurationen zu erleichtern, um die Anwendung zu erstellen möglichst effizient laufen.
Dem Optimierer ist es egal, welche Speicher-Engine verwendet wird, aber die Speicher-Engine hat einen Einfluss auf die Optimierung von Abfragen. Der Optimierer fordert die Speicher-Engine auf, Kapazitäts- oder Kosteninformationen zu einem bestimmten Vorgang sowie statistische Informationen zu Tabellendaten usw. bereitzustellen. Beispielsweise können bestimmte Indizes bestimmter Speicher-Engines für bestimmte Abfragen optimiert werden.
Bei SELECT-Anweisungen überprüft der Server vor dem Parsen der Abfrage zunächst den Abfragecache (Abfragecache). Wenn die entsprechende Abfrage darin gefunden werden kann, muss der Server nicht den gesamten Abfragevorgang durchführen Beim Parsen, Optimieren und Ausführen wird die Ergebnismenge im Abfragecache direkt zurückgegeben.
Das Obige ist der Inhalt der logischen Architektur von [MySQL] MySQL. Weitere verwandte Inhalte finden Sie auf der chinesischen PHP-Website (www.php.cn).

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
