

Das Konzept der Optimierung wird im Entwicklungsprojektprozess immer erwähnt. Dieser Artikel ist eine Erkundungsreise durch die Praxis der MySQL-Datenoptimierung. Er stellt kurz die Gründe, Methoden, Methoden zur Partitionstabellenverwaltung und eine einfache Praxis der Partitionierung vor.
Teilen und erobern Sie beim Betrieb von Big Data die Datentabelle und teilen Sie eine Tabelle mit einer großen Datenmenge In eine kleinere Betriebseinheit wird jede Betriebseinheit einen eigenen Namen haben. Gleichzeitig ist Partitionierung für Programmentwickler dasselbe wie keine Partitionierung. Im Allgemeinen ist die MySQL-Partitionierung für Programmanwendungen transparent und lediglich eine Neuanordnung von Daten durch die Datenbank.
Partitionsfunktion:
(1) Leistung verbessern.
Der ultimative Zweck der Partitionierung besteht darin, die Leistung zu verbessern. Nach Abschluss der Partitionierung generiert MySQL spezifische Datendateien und Indexdateien für jede Partition und ruft beim Abrufen bestimmte Teildaten ab Datenbank besser implementieren und pflegen. Dies liegt daran, dass partitionierte Tabellen unterschiedlichen physischen Laufwerken zugewiesen sind, wodurch der physische I/O-Konflikt der Partition beim gleichzeitigen Zugriff auf mehrere Partitionen reduziert wird.
(2) Einfach zu verwalten.
Nach der Partitionierung können die Verwaltungsdaten die entsprechende Partition direkt verwalten. Die Bedienung ist einfach. Wenn die Daten Millionen erreichen, ist die direkte Bedienung der Partition weitaus direkter als die Bedienung der Datentabelle.
(3) Fehlertoleranz
Wenn nach Abschluss der Partitionierung eine Partition zerstört wird, werden andere Daten zerstört nicht beeinträchtigt werden.
Die Partitionierungsmethoden von MySQL umfassen: RANGE-Partition, LIST-Partition, HASH-Partition und KEY-Partition.
RANGE-Partitionierung: Die Partitionsverwaltung erfolgt basierend auf dem Wert eines bestimmten Felds. Es wird beim direkten Erstellen einer Tabelle partitioniert. Beispiel:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date, salary int ) partition by range(salary) ( partition p1 values less than (1000), partition p2 values less than (2000), partition p3 values less than maxvalue );
LIST-Partition: Ähnlich wie die RANG-Partition, der Unterschied besteht darin, dass die Listenpartition ein Hash-Wert ist. Die RANG-Partitionierung basiert auf einem bestimmten Feldbereich. zB:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by list(deptno) ( partition p1 values in (10,15), partition p2 values in (20,25), partition p3 values in (30,35) );
HASH-Partitionierung: stellt sicher, dass die Daten gleichmäßig in den Partitionen vorab festgelegter Bibliographien verteilt sind Partitionen werden basierend auf den Spaltenwerten und der Anzahl der Partitionen angegeben. Beispiel:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by hash(year(birthdate)) partitions 4;
KEY-Partition: ähnlich der HASH-Partition, anders als die KEY-Partition, die nur die Berechnung einer oder mehrerer Spalten unterstützt , MySQL Der Server stellt eine eigene Hash-Funktion bereit, die eine oder mehrere Spalten mit ganzzahligen Werten enthalten muss. Beispiel:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by key(birthdate) partitions 4;
Partition löschen:
alter table emp drop partition p1;
Hash- oder Schlüsselpartitionen können nicht gelöscht werden.
Mehrere Partitionen auf einmal löschen, ändern Tabelle emp löschen Partition p1,p2;
Partition hinzufügen:
alter table emp add Partition (Partition p3 Werte kleiner als (4000));
alter table empl add Partition ( Partition p3 Werte in (40));
Partition neu organisieren:
Das Schlüsselwort Reorganizepartition kann einige oder alle Partitionen der Tabelle ändern, ohne dass Daten verloren gehen. Der Gesamtumfang der Partition sollte vor und nach der Zerlegung konsistent sein.
ändern Tabellete
Partition p1 in< umorganisieren 🎜>
(
Partition p1 Werte kleiner als (100) ,
Partition p3 Werte kleiner als (1000)
); ----Kein Datenverlust
Partitionen zusammenführen:
Partitionen zusammenführen: 2 Partitionen zu einer zusammenführen.
ändern Tabelle te
Partition p1,p3 umorganisieren in
(Partition p1 Werte kleiner als (1000));
----Kein Datenverlust
Hash-Partitionstabelle neu definieren:
Ändern Tabelle emp-Partition durch Hash-(Gehalts-)Partitionen 7;
---- Es gehen keine Daten verloren
Bereichspartitionstabelle neu definieren:
Ändern Tabelle emp-PartitionnachBereich(Gehalt)
(
Partition p1 Werte weniger als (2000),
Partition p2 Werte kleiner als (4000 )
); ----Kein Datenverlust
Alle Partitionen der Tabelle löschen:
Alter table emp removepartitioning;--Kein Datenverlust
Erstellen Sie die Partition neu:
Dies hat den gleichen Effekt, als würden Sie zuerst alle in der Partition gespeicherten Datensätze löschen und sie dann wieder einfügen . Es kann zum Defragmentieren von Partitionen verwendet werden.
ALTER TABLE emp rebuild partitionp1,p2;
Partitionierung optimieren:
Wenn eine große Anzahl von Zeilen aus einer Partition gelöscht wird oder wenn eine Variable If Die Länge der Zeile (d. h. es gibt Spalten vom Typ VARCHAR, BLOB oder TEXT) wurde viele Male geändert. Sie können „ALTER TABLE ... OPTIMIZE PARTITION“ verwenden, um ungenutzten Speicherplatz zurückzugewinnen und die Partitionsdatendatei zu defragmentieren.
ALTER TABLE emp optimize partition p1,p2;
Analysepartition:
Lesen und speichern Sie die Schlüsselverteilung der Partition.
ALTER TABLE emp analyzepartition p1,p2;
Partition reparieren:
Die beschädigte Partition reparieren Partition.
ALTER TABLE emp Repairpartition p1,p2;
Überprüfen von Partitionen:
Partitionen können auf die gleiche Weise überprüft werden wie mit CHECK TABLE für eine nicht- partitionierte Tabelle.
ALTER TABLE emp CHECK Partition p1,p2;
这个命令可以告诉你表emp的分区p1,p2中的数据或索引是否已经被破坏。如果发生了这种情况,使用“ALTER TABLE ... REPAIR PARTITION”来修补该分区。
1. 创建分区表和不分区表:
-- 创建分区表 CREATE TABLE part_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null) PARTITION BY RANGE(year(c3)) (PARTITION p0 VALUES LESS THAN (1995), PARTITION p1 VALUES LESS THAN (1996) , PARTITION p2 VALUES LESS THAN (1997) , PARTITION p3 VALUES LESS THAN (1998) , PARTITION p4 VALUES LESS THAN (1999) , PARTITION p5 VALUES LESS THAN (2000) , PARTITION p6 VALUES LESS THAN (2001) , PARTITION p7 VALUES LESS THAN (2002) , PARTITION p8 VALUES LESS THAN (2003) , PARTITION p9 VALUES LESS THAN (2004) , PARTITION p10 VALUES LESS THAN (2010), PARTITION p11 VALUES LESS THAN (MAXVALUE) );
-- 创建没有分区表 CREATE TABLE nopart_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null)
2. 创建大数据操作环境。为了测试结果的准确度提高,需要表中存在大数据,通过以下事务可在数据表中创建800万条数据:
-- 创建生成数据事物
CREATE PROCEDURE load_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,'testingpartitions',adddate('1995-01-01',(rand(v)*36520)mod 3652));
set v = v + 1;
end while;
end; 执行事务:call load_part_tab(); ,因为执行此事务执行的时间很长,我只在表中插入了283304条数据。
创建完成一张表后,可以将该表的数据复制到未分区表,这样执行速度会很快:
insert into test.nopart_tab select * from test.part_tab
3. 查看分区表分区结构:
-- 查询分区情况 select partition_name part, partition_expression expr, partition_description descr, table_rows from information_schema.partitions where table_schema = schema() and table_name='part_tab';
执行结果:
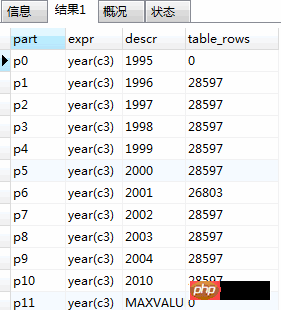
3. 测试速度:
执行分区表查询语句:
select count(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

执行未分区表查询语句:
select count(*) from nopart_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

从时间对比可以看出,同样的查询语句,分区表执行速度在20ms左右,未分区表在175ms左右,执行速度相差8倍左右,因此得出结论:分区表的执行速度要比未分区表执行速度快。
1. MySQL分区处理NULL值的方式
如果分区键所在列没有notnull约束。
如果是range分区表,那么null行将被保存在范围最小的分区。
如果是list分区表,那么null行将被保存到list为0的分区。
在按HASH和KEY分区的情况下,任何产生NULL值的表达式mysql都视同它的返回值为0。
为了避免这种情况的产生,建议分区键设置成NOT NULL。
2. Der Partitionsschlüssel muss vom Typ INT sein oder den Typ INT über einen Ausdruck zurückgeben, der NULL sein kann. Die einzige Ausnahme besteht darin, dass Sie beim Partitionstyp KEY-Partitionierung andere Spaltentypen als Partitionsschlüssel verwenden können (außer BLOB- oder TEXT-Spalten).
3. Erstellen Sie einen Index für den Partitionsschlüssel der Partitionstabelle, dann wird dieser Index auch partitioniert. Es gibt keinen globalen Index Index für den Partitionsschlüssel.
4. Nur RANG- und LIST-Partitionen können unterpartitioniert werden, HASH- und KEY-Partitionen können nicht unterpartitioniert werden.
5. Temporäre Tabellen können nicht partitioniert werden.
Das Obige ist der Inhalt des MySQL-Optimierungsexperiments (1) – Partition. Weitere verwandte Inhalte finden Sie auf der chinesischen PHP-Website (www.php.cn)!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Mobile Festplattenpartitionssoftware
Mobile Festplattenpartitionssoftware
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



