

Ausführliche Erläuterung der MySQL-Indizes und -Strukturen

B-Baum
B-Baum wird auch als ausgeglichener Mehrpfad-Suchbaum (nicht binär) bezeichnet Reduzieren Sie den Zwischenvorgang, der beim Aufzeichnen auftritt, und beschleunigen Sie so den Zugriff.
Schlüsselwert des linken untergeordneten Knotens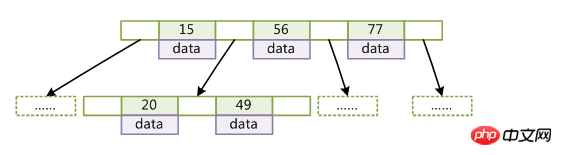
(Schlüssel ist der Schlüsselwert des Datensatzes. Für verschiedene Datensätze unterscheidet sich der Schlüssel voneinander; Daten sind die Daten im Datensatz mit Ausnahme des Schlüssels)
B +Baum
B+Tree ist ein verbesserter B-Baum. 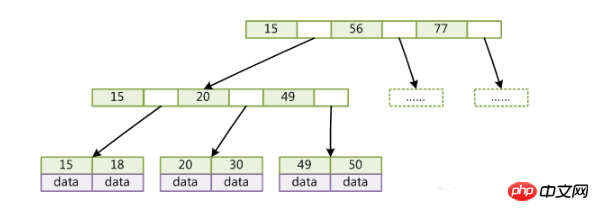
(Schlüssel ist der Schlüsselwert des Datensatzes. Für verschiedene Datensätze unterscheidet sich der Schlüssel voneinander; Daten sind die Daten im Datensatz mit Ausnahme des Schlüssels)
Kompatibel mit B-Tree Im Vergleich zu B+Tree gibt es folgende Unterschiede:
Die Obergrenze des Zeigers jedes Knotens beträgt 2d statt 2d+1.
Interne Knoten speichern keine Daten, nur Schlüssel speichern keine Zeiger.
Warum verwendet die Datenbank dann B-Tree?
Die mechanische Festplatte des Computers. Um die Wartezeit für mechanische Bewegungen zu amortisieren, greift die Festplatte auf mehrere zu Nicht eins, eine solche Informationseinheit, die gleichzeitig gelesen wird, ist eine Seite. Wir können die Anzahl der gelesenen oder geschriebenen Seiten als Hauptnäherungswert für die Gesamtzeit des Festplattenzugriffs verwenden . B-Tree-Algorithmen müssen zu jedem Zeitpunkt nur eine bestimmte Anzahl von Seiten im Speicher behalten. Das Design von B-Tree berücksichtigt das Vorlesen der Festplatte. Ein B-Tree-Knoten ist normalerweise so groß wie eine vollständige Festplattenseite (Seite), und die Größe der Festplattenseite begrenzt die untergeordneten Elemente, die ein B-Tree enthält. Der Baumknoten kann die Anzahl (Verzweigungsfaktor) enthalten. Dies hängt natürlich auch von der Größe eines Schlüsselworts im Verhältnis zu einer Seite ab.
Um E/A-Vorgänge zu minimieren, werden Festplattenlesevorgänge jedes Mal im Voraus gelesen, und die Größe ist normalerweise ein ganzzahliges Vielfaches der Seite. Selbst wenn nur ein Byte gelesen werden muss, liest die Festplatte eine Datenseite (normalerweise 4 KB) und legt sie in Seiteneinheiten im Speicher ab. Denn das Lokalitätsprinzip besagt, dass bei der üblichen Nutzung eines Datenelements auch unmittelbar benachbarte Daten genutzt werden. B-Baum: Wenn für einen Abruf der Zugriff auf 4 Knoten erforderlich ist, verwendet der Datenbanksystemdesigner das Prinzip des Festplatten-Vorauslesens, um die Größe des Knotens als eine Seite zu entwerfen, sodass für das Lesen eines Knotens nur ein I erforderlich ist /O-Vorgang: Um diesen Abrufvorgang abzuschließen, sind bis zu 3 E/As erforderlich (der Stammknoten befindet sich im Speicher).Je kleiner der Datensatz, desto mehr Daten werden in jedem Knoten gespeichert, desto kleiner ist die Höhe des Baums, desto weniger E/A-Vorgänge und desto höher ist die Abrufeffizienz.
B+Baum: Nicht-Blattknoten speichern nur Schlüssel, wodurch die Größe von Nicht-Blattknoten erheblich reduziert wird, sodass jeder Knoten mehr Datensätze speichern kann.Der Baum ist kürzer und erfordert weniger E/A . B+Tree hat also eine bessere Leistung.
Was ist ein Index?Ein Index ist einfach eine Datenstruktur. Die Kosten für die IndizierungDie Indizierung hat auch ihren Preis: Die Indexdatei selbst verbraucht Speicherplatz und der Index erhöht die Belastung durch das Einfügen, Löschen und Ändern von Datensätzen Außerdem werden Ressourcen verbraucht, um Indizes zu verwalten, sodass mehr Indizes nicht immer besser sind. Im Allgemeinen wird die Erstellung eines Index unter zwei Umständen nicht empfohlen.Der erste Fall besteht darin, dass die Tabellendatensätze relativ klein sind.
Der andere Fall, in dem die Erstellung eines Index nicht empfohlen wird, besteht darin, dass der Index selektiv ist niedrig. Die sogenannte Indexselektivität bezieht sich auf das Verhältnis eindeutiger Indexwerte (auch Kardinalität genannt) zur Anzahl der Tabellendatensätze (#T)
2. Eindeutiger Index
3. Primärschlüsselindex
4. Kombinierter Index
B+Tree wird in MySQL häufig als Index verwendet Die Implementierung unterscheidet sich je nach Clustered-Index und Nicht-Clustered-Index.
Clustered-Index und Nicht-Clustered-Index
Der sogenannte Clustered-Index bedeutet, dass die Hauptindexdatei und die Datendatei dieselbe Datei sind, die hauptsächlich in der Innodb-Speicher-Engine verwendet wird. In dieser Indeximplementierung sind die Daten auf den Blattknoten von B+Tree die Daten selbst und der Schlüssel ist der Primärschlüssel. Wie unten gezeigt: 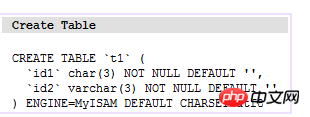
(t1-Tabelle) 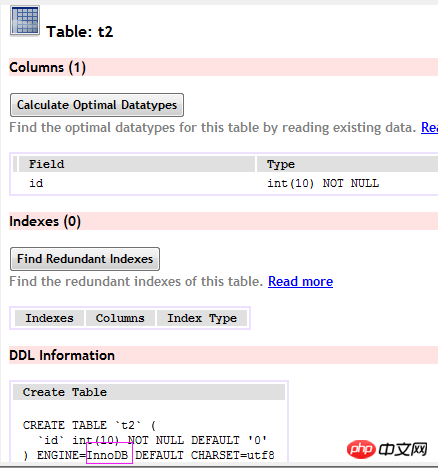
(t2-Tabelle) 
(Datei, die der Datenbank entspricht)
Weil von InnoDB Die Datendateien selbst müssen nach Primärschlüssel aggregiert werden, daher erfordert InnoDB, dass die Tabelle einen Primärschlüssel haben muss (MyISAM hat möglicherweise keinen, wenn nicht explizit angegeben, wählt das MySQL-System automatisch eine Spalte aus, die die eindeutig identifizieren kann). Wenn keine solche Spalte vorhanden ist, generiert MySQL automatisch ein implizites Feld als Primärschlüssel für die InnoDB-Tabelle. Die Länge dieses Felds beträgt 6 Bytes und der Typ ist lang.
Die Hauptunterschiede zwischen MyISAM- und InnoDB-Datenspeicher-Engines in der MySQL-Datenbank
:
MyISAM ist nicht transaktionssicher, während InnoDB transaktionssicher ist.
Die Granularität von MyISAM-Sperren erfolgt auf Tabellenebene, während InnoDB Sperren auf Zeilenebene unterstützt.
MyISAM unterstützt den Volltexttypindex, InnoDB unterstützt jedoch keinen Volltextindex.
MyISAM ist relativ einfach und daher hinsichtlich der Effizienz besser als InnoDB. Kleine Anwendungen können die Verwendung von MyISAM in Betracht ziehen.
MyISAM-Tabellen werden in Form von Dateien gespeichert. Die Verwendung von MyISAM-Speicher bei der plattformübergreifenden Datenübertragung erspart Ihnen viel Ärger.
InnoDB-Tabellen sind sicherer als MyISAM-Tabellen. Sie können nicht-transaktionale Tabellen in transaktionale Tabellen umwandeln (alter table tablename type=innodb) und dabei sicherstellen, dass keine Daten verloren gehen.
Anwendungsszenario:
MyISAM verwaltet nicht-transaktionale Tabellen. Es bietet Hochgeschwindigkeitsspeicherung und -abruf sowie Volltextsuchfunktionen. Wenn Ihre Anwendung eine große Anzahl von SELECT-Abfragen ausführen muss, ist MyISAM die bessere Wahl.
InnoDB wird für Transaktionsverarbeitungsanwendungen verwendet und verfügt über zahlreiche Funktionen, einschließlich ACID-Transaktionsunterstützung. Wenn Ihre Anwendung eine große Anzahl von INSERT- oder UPDATE-Vorgängen ausführen muss, sollten Sie InnoDB verwenden, was die Leistung gleichzeitiger Mehrbenutzer-Vorgänge verbessern kann.
Ergänzung
Hauptspeicherspeicher
Abrufvorgang
Wenn das System den Hauptspeicher lesen muss, wird das Adresssignal auf den Adressbus gelegt und an den weitergeleitet Hauptspeicher Nachdem der Hauptspeicher das Adresssignal gelesen hat, analysiert er das Signal, lokalisiert die angegebene Speichereinheit und legt dann die Daten dieser Speichereinheit auf den Datenbus, damit andere Komponenten sie lesen können.
Der Vorgang des Schreibens in den Hauptspeicher ist ähnlich. Das System platziert die Geräteadresse und die zu schreibenden Daten auf dem Adressbus bzw. dem Datenbus. Der Hauptspeicher liest den Inhalt der beiden Busse und führt entsprechende Schreibvorgänge aus.
Hier ist zu erkennen, dass die Zeit des Hauptspeicherzugriffs nur linear mit der Anzahl der Zugriffe zusammenhängt. Da keine mechanische Operation erfolgt, hat die „Entfernung“ der Daten, auf die zweimal zugegriffen wird, keinen Einfluss auf die Zeit. Zum Beispiel zuerst abrufen Der Zeitaufwand für das Abrufen von A0 und dann für A1 ist derselbe wie für das Abrufen von A0 und dann für D3
Prinzip des Festplattenzugriffs
Wenn Daten von der Festplatte gelesen werden müssen, wird die Das System leitet die logische Datenadresse an die Festplatte weiter. Die Steuerschaltung der Festplatte übersetzt die logische Adresse gemäß der Adressierungslogik in eine physische Adresse, d. h. sie bestimmt, auf welcher Spur und in welchem Sektor sich die zu lesenden Daten befinden. Um die Daten in diesem Sektor zu lesen, muss der Magnetkopf über diesem Sektor platziert werden. Dazu muss sich der Magnetkopf bewegen, um ihn an der entsprechenden Spur auszurichten. Dieser Vorgang wird als Suchen bezeichnet wird als Suchzeit bezeichnet. Der Zielsektor wird unter dem Kopf gedreht. Die für diesen Vorgang aufgewendete Zeit wird als Rotationszeit bezeichnet.
Das Obige ist eine ausführliche und detaillierte Erklärung des MySQL-Index und der Struktur. Weitere verwandte Inhalte finden Sie auf der chinesischen PHP-Website (www.php.cn)!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
