

Detaillierte Einführung in die Bereichspartition der MySQL-Partition

Mit der Entwicklung des Internets gibt es in allen Aspekten immer mehr Daten, was sich an der wachsenden Nachfrage nach Big Data in den letzten zwei Jahren zeigt.
Obwohl das Projekt, das wir durchführen, kein großes Projekt ist, gibt es aufgrund des Geschäftsvolumens ziemlich viele Daten.
Wenn zu viele Daten vorhanden sind, können Leistungsprobleme auftreten. Um dieses Problem zu lösen, denken wir normalerweise einfach an Clustering, Sharding usw.
Aber irgendwann ist es nicht mehr notwendig, Cluster oder Sharding zu verwenden, und die Datenpartitionierung kann auch entsprechend verwendet werden.
Was ist eine Partition?
Wenn MySQL die Partitionsfunktion nicht aktiviert, wird der Inhalt einer einzelnen Tabelle in der Datenbank in Form einer einzelnen Datei im Dateisystem gespeichert. Wenn die Partitionierungsfunktion aktiviert ist, teilt MySQL den Inhalt einer einzelnen Tabelle in mehrere Dateien auf und speichert sie gemäß benutzerdefinierten Regeln im Dateisystem. Die Partitionierung ist in horizontale Partitionierung und vertikale Partitionierung unterteilt. Bei der horizontalen Partitionierung werden Tabellendaten zeilenweise in verschiedene Datendateien unterteilt, während bei der vertikalen Partitionierung Tabellendaten spaltenweise in verschiedene Datendateien unterteilt werden. Sharding muss den Prinzipien der Vollständigkeit, Rekonfigurierbarkeit und Disjunktheit folgen. Vollständigkeit bedeutet, dass alle Daten einem Fragment zugeordnet werden müssen. Rekonfigurierbarkeit bedeutet, dass alle Shard-Daten in globale Daten rekonstruiert werden können müssen. Disjunktheit bedeutet, dass es keine Duplizierung von Daten auf verschiedenen Shards gibt (es sei denn, Sie machen sie absichtlich redundant).
Wahrscheinlich aus verschiedenen Gründen verwendet die von uns verwendete Tabelle eine Bereichspartitionierung. Die Datenbank wird von anderen verwaltet, aber da diese Tabelle verwendet wird, habe ich mir die Zeit genommen, dies zu tun.
Soweit ich weiß, müssen Sie beim Erstellen der Tabellenstruktur die Anweisung zum Erstellen einer Partition verwenden, wenn Sie Partitionierung verwenden möchten, und diese kann später nicht mehr geändert werden.
Zum Beispiel erstelle ich eine einfache Emp-Tabelle mit drei Feldern: ID, Name und Alter und partitioniere sie dann basierend auf der ID. Die korrekte Anweisung zur Tabellenerstellung lautet im Wesentlichen wie folgt:
CREATE TABLE emp( id INT NOT NULL, NAME VARCHAR(20), age INT) PARTITION BY RANGE(ID)( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION pmax VALUES LESS THAN maxvalue );
Hier stelle ich die Daten der gesamten Tabelle so ein, dass sie in drei Bereiche unterteilt werden. Der Bereich mit einer ID von weniger als 6 ist ein Bereich und der Bereich Name ist p0; die ID liegt zwischen 6 und 11. Gehört zu einer Zone, ist der Zonenname p1, dann haben alle Zonen mit einer ID größer als 11 den Zonennamen pmax.
Organisieren Sie eine Syntax im Wesentlichen wie folgt:
create table tablename( 字段名 数据类型...) partition by range(分区依赖的字段名)( partition 分取名 values less than (分区条件的值),...)
Hier ist zu beachten, dass die letzte Zeile im Beispiel pmax-Werte kleiner als maxvalue aufteilt, in diesem Satz nur pmax, der den Partitionsnamen darstellt, kann beliebig abgerufen werden, die restlichen Wörter können nicht geändert werden und maxvalue stellt den Maximalwert der obigen Partitionsbedingung dar.
Dadurch wird sichergestellt, dass alle Daten normal in der Datenbank gespeichert werden können. Andernfalls werden die Daten mit einer ID größer oder gleich 11 nicht in der Datenbank gespeichert und es wird ein Fehler gemeldet.
Nachdem die Tabellenstruktur erstellt wurde, habe ich einige Daten in die Tabelle eingefügt, um zu testen, ob die Partitionierung erfolgreich war. Die Anweisung lautet wie folgt:
INSERT INTO emp VALUES(1,'test1',22);INSERT INTO emp VALUES(2,'test2',25);INSERT INTO emp VALUES(3,'test3',27); INSERT INTO emp VALUES(4,'test4',20);INSERT INTO emp VALUES(5,'test5',22);INSERT INTO emp VALUES(6,'test6',25); INSERT INTO emp VALUES(7,'test7',27);INSERT INTO emp VALUES(8,'test8',20);INSERT INTO emp VALUES(9,'test9',22); INSERT INTO emp VALUES(10,'test10',25);INSERT INTO emp VALUES(11,'test11',27);INSERT INTO emp VALUES(12,'test12',20); INSERT INTO emp VALUES(13,'test13',22);INSERT INTO emp VALUES(14,'test14',25);INSERT INTO emp VALUES(15,'test15',27); INSERT INTO emp VALUES(16,'test16',20);INSERT INTO emp VALUES(17,'test17',30);INSERT INTO emp VALUES(18,'test18',40); INSERT INTO emp VALUES(19,'test19',20);
Nach dem Einfügen der Daten Überprüfen Sie nach Abschluss, ob sie der ID entsprechen. Die Daten werden in der entsprechenden Partition gespeichert. Mit dem Befehl können Sie die Partition wie folgt abfragen:
SELECT partition_name,partition_expression,partition_description,table_rows FROM information_schema.PARTITIONS WHERE table_schema = SCHEMA() AND table_name='emp'
Das Abfrageergebnis ist wie in der Abbildung dargestellt : 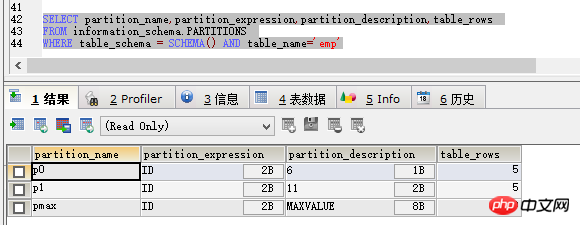
Es ist ersichtlich, dass „partition_name“ der Partitionsname ist, „partition_expression“ ist das Feld, von dem die Partition abhängt, „partition_description“ kann als Zustand der Partition verstanden werden und „table_rows“ stellt die aktuelle Datenmenge dar in der Partition.
Aus den obigen Daten geht hervor, dass die Partitionierung erfolgreich ist. Obwohl die obige Partitionierung das Problem der Nichteinfügung vermeiden kann, ist ein neues Problem aufgetreten.
Das heißt, die Daten im letzten pmax-Bereich können sehr groß sein. Infolgedessen sind die Daten ungleichmäßig und unverhältnismäßig, was zu Leistungsproblemen beim Abfragen der Daten im letzten Bereich führen kann. Daher gibt es ungefähr drei Lösungen:
Erstens: Wenn Sie die Partitionsfelddaten, wie hier die ID, steuern können, wenn Sie genau wissen können, wann und welchen Wert sie haben werden, können Sie dies nicht tun Verwenden Sie dieses pmax zu Beginn, fügen Sie jedoch regelmäßig Partitionen hinzu. Wenn hier beispielsweise p0 und p1 vorhanden sind, können Sie p2, p3 oder sogar mehr hinzufügen, wenn die ID kurz vor dem Erreichen von 11 steht. Beispiele für Anweisungen zum Hinzufügen von Partitionen sind wie folgt:
ALTER TABLE emp ADD PARTITION(PARTITION p2 VALUES LESS THAN (16))
Die Syntax lautet:
alter table tablename add partition(partition 分区名 values lessthan (分区条件))
Die obige Methode kann das Problem unverhältnismäßiger Daten lösen, birgt jedoch auch versteckte Gefahren. Das heißt, wenn Sie vergessen, nachfolgende Partitionen hinzuzufügen, oder wenn die Feldwerte, von denen die Partitionen abhängen, die Erwartungen übertreffen, kann es zu dem Problem kommen, dass die Daten nicht in der Datenbank gespeichert werden können. Auf diese Weise gibt es zwei Möglichkeiten, das Problem zu lösen:
Erstens können Sie den Transaktionsmechanismus und die gespeicherten Prozeduren von MySQL verwenden, um eine geplante MySQL-Aufgabe zu erstellen, und dann das Datenbanksystem zu einem bestimmten Zeitpunkt dazu bringen, Partitionen hinzuzufügen. Auf diese Weise treten die in der ersten Methode genannten Probleme grundsätzlich nicht auf. Diese Methode erfordert jedoch ein gewisses Verständnis von MySQL-Transaktionen und gespeicherten Prozeduren und ist schwierig zu bedienen.
Ich kenne diese Methode, habe sie aber noch nicht implementiert. Ich werde später relevante Beispiele nennen, nachdem ich mehr über Transaktionen und gespeicherte Prozeduren erfahren habe.
Zusätzlich zu der oben beschriebenen Methode für geplante Aufgaben gibt es eine andere Möglichkeit, die Partition aufzuteilen: Verwenden Sie die Tabellenstruktur, die zuvor die pmax-Partition hatte, und teilen Sie sie dann mit der Split-Partition-Anweisung in pmax auf. Ein Beispiel ist wie folgt:
ALTER TABLE emp REORGANIZE PARTITION pmax INTO( PARTITION p2 VALUES LESS THAN (16), PARTITION pmax VALUES LESS THAN maxvalue )
然后我们再用查询分区情况的语句查询,便可以看到结果变成这样: 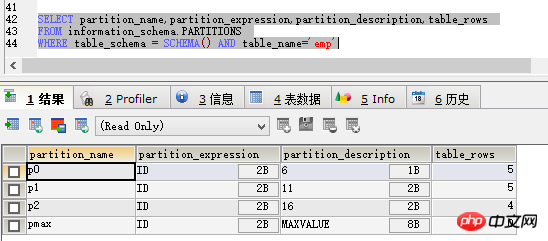
很显然,多出来了一个p2分区,拆分成功的同事不影响其他的功能。
那么这里分区拆分的语法整理如下:
alter table tablename reorganize partition 要拆分的分区名 into( partition 拆分后的分区名1 values less than (条件), partition 拆分后的分区名2 values lessthan (条件),...)
好了,到这里基本上算是完成了,但是我们知道数据库一般的操作都是增删改查,我们这里已经有了增改查,却自然也不能少了删。
按理说正常的生产环境的数据库应该是不能随意删除数据的,但是并不代表就不能删,反而有的时候还必须要删。
就比如我们项目中那个库,由于数据量太大,即便是分区了也依旧会在大量数据的情况下变慢。而与此同时,我们是按时间分区的,实际使用过程中只需要用到几天的数据,那么实际上很早以前的数据是可以删除不要的,或者说备份以后删除这个表的,这样就需要用到删除语句。
当然了,删除可以用delete,但是这样的话分区信息还在库中,实际上也是没必要要的,完全可以直接删除分区,因为删除分区的时候也同时会删除这个区内的所有数据。
示例之前我们先查一下之前插入的所有数据,如图: 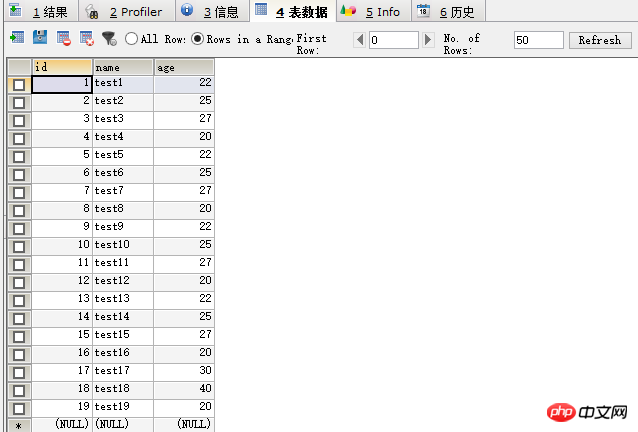
这里示例删除p0分区代码如下:
ALTER TABLE emp DROP PARTITION p0
然后先用查询分区的代码看一下,如图 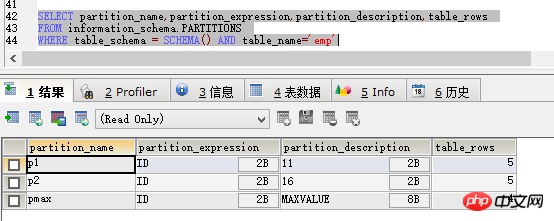
可以看到p0区不见了,在select * 一下,如图: 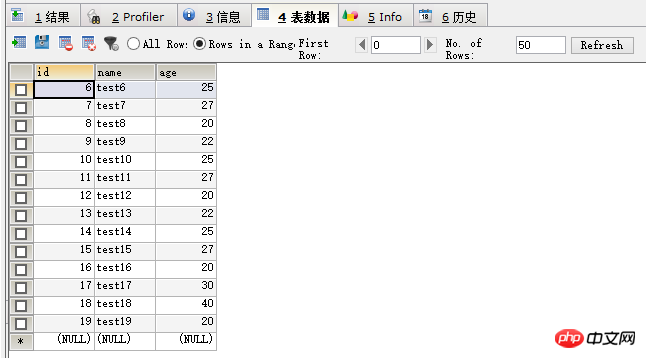
可以看到id小于6的数据已经没有了,数据删除成功。
以上就是mysql分区之range分区的详细介绍的内容,更多相关内容请关注PHP中文网(www.php.cn)!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Eine effektive Überwachung von Redis -Datenbanken ist entscheidend für die Aufrechterhaltung einer optimalen Leistung, die Identifizierung potenzieller Engpässe und die Gewährleistung der Zuverlässigkeit des Gesamtsystems. Redis Exporteur Service ist ein leistungsstarkes Dienstprogramm zur Überwachung von Redis -Datenbanken mithilfe von Prometheus. In diesem Tutorial führt Sie die vollständige Setup und Konfiguration des Redis -Exporteur -Dienstes, um sicherzustellen, dass Sie nahtlos Überwachungslösungen erstellen. Durch das Studium dieses Tutorials erhalten Sie voll funktionsfähige Überwachungseinstellungen
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
