
 Backend-Entwicklung
C#.Net-Tutorial
Detaillierte Einführung in die Richtlinien für das Ausnahmedesign in .net und anderen Architekturen
Backend-Entwicklung
C#.Net-Tutorial
Detaillierte Einführung in die Richtlinien für das Ausnahmedesign in .net und anderen Architekturen
Detaillierte Einführung in die Richtlinien für das Ausnahmedesign in .net und anderen Architekturen

Frontline
Richtlinien zum Ausnahmedesign finden Sie in Microsoft MSDN, kombinieren Sie Ihr eigenes Verständnis und den Umgang mit Ausnahmefehlern in der vergangenen Entwicklung und fassen Sie die Software zusammen Entwicklungsarchitektur, wie man eine Reihe von Ausnahmefehlerkriterien besser entwerfen kann.
Einführung in die Richtlinien
Konzept des Ausführungsfehlers
Die Bedeutung von Ausführungsfehler: Ein Ausführungsfehler tritt immer dann auf, wenn ein Mitglied nicht tun kann, was es tun soll wurde entwickelt (was der Mitgliedsname andeutet). Wenn die OpenFile-Methode beispielsweise kein geöffnetes Dateihandle an den Aufrufer zurückgeben kann, wird dies als Ausführungsfehler betrachtet.
Übersetzung:
Die Bedeutung eines Betriebsfehlers: Immer wenn ein Mitgliedsmodul seine erwartete Aufgabe nicht erfüllen kann, spricht man von einem Betriebsfehler. Beispielsweise kann die OpenFile-Methode kein Handle für die geöffnete Datei an den Aufrufer zurückgeben, was einen Vorgangsfehler darstellt.
Behandeln von Ausnahmen im Framework
Im Framework werden Ausnahmen für alle Fehlerbedingungen verwendet, einschließlich Ausführungsfehler.
Übersetzung:
Im Framework werden Ausnahmen verwendet, um alle Fehlerbedingungen, einschließlich Ausführungsfehler, zu behandeln.
Zusammenfassende Richtlinien
Welche Methoden beim Entwerfen von Ausnahmen verboten werden sollten, welche bedenkenlos durchgeführt werden sollten und welche berücksichtigt werden sollten, sind in der folgenden Tabelle aufgeführt.
| 编号 | 方法 | 做法 |
|---|---|---|
| 1 | 返回错误代码 | 禁止 |
| 2 | 执行错误,要抛出异常;如OpenFile()未返回文件句柄 | 建议 |
| 3 | 假如代码再继续执行就变得不安全时,考虑是调用System.Environment.FailFast终止进程还是抛异常。 | 考虑 |
| 4 | 如果有可能的话,在正常的控制流处,抛异常,见下面的分析 | 禁止 |
| 5 | 抛异常对性能的影响。 | 考虑 |
| 6 | 协定中纳入异常处理部分 | 建议 |
| 7 | 将异常作为返回值返回 | 禁止 |
| 8 | 使用异常生成器方法,为避免代码膨胀, 用helper方法创建异常和属性. | 考虑 |
| 9 | 异常筛选器中抛出异常. | 禁止 |
| 10 | 从finally 块中显示地抛出异常 | 禁止 |
Erklärung zu Punkt 4:
Berücksichtigen Sie beim täglichen Codieren das Tester-Macher-Muster für Mitglieder, das in häufigen Szenarien Ausnahmen auslösen kann, um damit verbundene Leistungsprobleme zu vermeiden zu Ausnahmen. Das Tester-Macher-Muster unterteilt einen Aufruf, der Ausnahmen auslösen kann: einen Tester und einen Macher. Der Tester führt einen Test für den Zustand durch, der dazu führen kann, dass der Macher eine Ausnahme auslöst test wird direkt vor dem Code eingefügt, der die Ausnahme auslöst, und schützt so vor der Ausnahme. Beispielcode von http://www.php.cn/
Referenz:
Tester und Doer führen jeweils ihre eigenen Aufgaben aus, wodurch das Auslösen von Ausnahmen perfekt reduziert und die Leistung verbessert wird.
Macher: Wenn die obige Statusüberwachung gut ist, kann sie von DoProcess() verarbeitet werden. Wenn sie falsch ist und DoProcess() die DoCheck()-Logik enthält, wird eine Ausnahme ausgelöst, aber nach dieser Trennung wird DoProcess ausgelöst ( ) löst keine Ausnahme aus!
if(DoCheck()==true)//这是Tester:状态监测
DoProcess();Häufige Ausnahmen und Handhabungsmethoden in der Softwareentwicklung (Selbstzusammenfassung)
1 Es wird empfohlen, die von der UI-Ebene bereitgestellte Betriebsschnittstelle in einem Versuch zu umschließen {}catch{}-Block , die im Catch ausgelöste Ausnahme wird auf die Festplatte geschrieben.
2 Wenn ein Timer in der UI-Ebene verwendet wird, wenn eine Ausnahme in der Rückruffunktion des Zählers auftritt, muss der Timer gestoppt werden, um zu verhindern, dass das Fehlerprotokoll in den geschrieben wird Datei.
3 Es wird empfohlen, den try{}catch{}-Block nicht in die unterste Ebene einzuschließen. Es wird empfohlen, throw zu verwenden, um eine Ausnahme direkt auszulösen, da try{} und Catch{}-Blöcke werden in die UI-Ebene eingeschlossen, sodass kein Schreiben in diese Ebenen erforderlich ist.
4 throw unterbricht zukünftige Vorgänge direkt und springt zu den äußeren Paketen des Stapels, try{} und Catch{}, also der UI-Ebene. Es ist im Allgemeinen so Es wird empfohlen, dass Funktionen keine Fehlercodes zurückgeben.
5 Bei der Verarbeitung stapelimportierter Daten ist eine lokale Ausnahme aufgetreten. Excel importiert Personal, Ausrüstung, Pläne, Materialien, Prozesse usw. Wenn eine bestimmte Datenzeile gegen die Regeln verstößt, wird zu diesem Zeitpunkt nicht empfohlen, eine Ausnahme auszulösen, da eine einmal ausgelöste Ausnahme bedeutet, dass die Daten in der Die folgenden Zeilen können nicht importiert werden und die importierten Daten werden zu fehlerhaften Daten.
Im Allgemeinen gibt es zwei Ansätze: Unzulässige Daten erscheinen in einer bestimmten Zeile und werden in der Protokolldatei aufgezeichnet. Später wird anhand dieser Datei festgestellt, dass die Daten nicht importiert wurden, und diese können dann separat verarbeitet werden ; Überprüfen Sie vor dem Import direkt, ob die Daten in allen Zeilen zulässig sind, und importieren Sie sie nacheinander . Andernfalls wird eine Eingabeaufforderung angezeigt und es werden keine Daten in die Datenbank geschrieben. Letzteres Vorgehen wird generell empfohlen. Dieser Ansatz wird als Tester-Doer-Ausnahmemodus bezeichnet und wird auch von Microsoft empfohlen.
6 Bei der Verarbeitung der Dashboard-Anzeigedaten ist lokal eine Ausnahme aufgetreten. Dieser Verarbeitungsmodus unterscheidet sich von 5. Wenn zu diesem Zeitpunkt eine Ausnahme auftritt, wird im Allgemeinen häufig die frühere Methode von 5 angewendet: zeigt die korrekten Daten an und die illegalen Daten werden zur Überprüfung in das Protokoll geschrieben ; Es ist jedoch auch möglich, dass, wenn die Hauptdaten in der angezeigten Schnittstelle nicht vorhanden sind, direkt eine Ausnahme ausgelöst, in das Protokoll geschrieben und über das Protokoll gelöst wird. Daher sollte die Verarbeitung entsprechend dem Schweregrad der Anomalie der Daten erfolgen.
7 Versuchen Sie anhand von Entwicklungsdokumenten, Protokollen und Analysen den Grund zu finden, warum eine bestimmte Funktion nicht implementiert ist. Bewahren Sie zunächst die Entwicklungsunterlagen auf und prüfen Sie, ob die aktuellen Nutzeranforderungen mit denen in den Entwicklungsunterlagen übereinstimmen. Wenn sie konsistent sind, wird die Rolle des Protokolls zu diesem Zeitpunkt angezeigt. Beispielsweise ist ein Kreisdiagramm vorhanden, das den Abschluss aller Prozesse innerhalb einer Woche zusammenfasst Wenn ein Prozess aktiviert ist, bedeutet dies nicht, dass ein Prozess nicht gefunden wird. Wenn der Prozess in das Protokoll geschrieben wird, wird die Ursache gefunden. Daher sollte diese Art von Problem ebenfalls in das Protokoll geschrieben werden. Obwohl es sich nicht um einen Fehler handelt, kann es als Ausnahme klassifiziert werden.
8 Die Funktion gibt ein Objekt zurück, dessen Methoden und Eigenschaften von der nachfolgenden Logik referenziert werden. Das ist unvermeidlich! Und die Implementierung der meisten Funktionen hängt davon ab. Da auf das zurückgegebene Objekt später verwiesen wird, wird empfohlen, einen Nullvergleich durchzuführen. Wenn es null ist, wird eine Meldung angezeigt, oder es wird direkt eine Ausnahme ausgelöst Die UI-Ebene schreibt es je nach Situation nach der Verarbeitung in das Protokoll.
Das Obige ist eine detaillierte Einführung in die Exception-Designrichtlinien in .net und anderen Architekturen. Weitere verwandte Inhalte finden Sie in PHP Chinesische Website (www.php.cn)!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Vergleichende Analyse von Deep-Learning-Architekturen
May 17, 2023 pm 04:34 PM
Vergleichende Analyse von Deep-Learning-Architekturen
May 17, 2023 pm 04:34 PM
Das Konzept des Deep Learning stammt aus der Erforschung künstlicher neuronaler Netze. Ein mehrschichtiges Perzeptron, das mehrere verborgene Schichten enthält, ist eine Deep-Learning-Struktur. Deep Learning kombiniert Funktionen auf niedriger Ebene, um abstraktere Darstellungen auf hoher Ebene zu bilden, um Kategorien oder Merkmale von Daten darzustellen. Es ist in der Lage, verteilte Merkmalsdarstellungen von Daten zu erkennen. Deep Learning ist eine Form des maschinellen Lernens, und maschinelles Lernen ist der einzige Weg, künstliche Intelligenz zu erreichen. Was sind also die Unterschiede zwischen verschiedenen Deep-Learning-Systemarchitekturen? 1. Vollständig verbundenes Netzwerk (FCN) Ein vollständig verbundenes Netzwerk (FCN) besteht aus einer Reihe vollständig verbundener Schichten, wobei jedes Neuron in jeder Schicht mit jedem Neuron in einer anderen Schicht verbunden ist. Sein Hauptvorteil besteht darin, dass es „strukturunabhängig“ ist, d. h. es sind keine besonderen Annahmen über die Eingabe erforderlich. Obwohl dieser strukturelle Agnostiker das Ganze abschließt
 Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Vor einiger Zeit löste ein Tweet, der auf die Inkonsistenz zwischen dem Transformer-Architekturdiagramm und dem Code im Papier „AttentionIsAllYouNeed“ des Google Brain-Teams hinwies, viele Diskussionen aus. Manche Leute halten Sebastians Entdeckung für einen unbeabsichtigten Fehler, aber sie ist auch überraschend. Angesichts der Popularität des Transformer-Papiers hätte diese Inkonsistenz schließlich tausendmal erwähnt werden müssen. Sebastian Raschka antwortete auf Kommentare von Internetnutzern, dass der „originellste“ Code zwar mit dem Architekturdiagramm übereinstimme, die 2017 eingereichte Codeversion jedoch geändert, das Architekturdiagramm jedoch nicht gleichzeitig aktualisiert worden sei. Dies ist auch die Ursache für „inkonsistente“ Diskussionen.
 Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Deep-Learning-Modelle für Sehaufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einem einzelnen visuellen Bereich (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert. Im Allgemeinen muss eine Anwendung, die Vision-Aufgaben für mehrere Domänen ausführt, mehrere Modelle für jede einzelne Domäne erstellen und diese unabhängig voneinander trainieren. Während der Inferenz verarbeitet jedes Modell eine bestimmte Domäne. Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet. Darüber hinaus können MDL-Modelle auch Single-Modelle übertreffen
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
 Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA basiert auf der JPA-Architektur und interagiert mit der Datenbank über Mapping, ORM und Transaktionsmanagement. Sein Repository bietet CRUD-Operationen und abgeleitete Abfragen vereinfachen den Datenbankzugriff. Darüber hinaus nutzt es Lazy Loading, um Daten nur bei Bedarf abzurufen und so die Leistung zu verbessern.
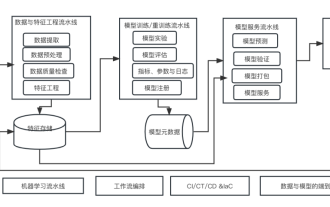 Zehn Elemente der Systemarchitektur für maschinelles Lernen
Apr 13, 2023 pm 11:37 PM
Zehn Elemente der Systemarchitektur für maschinelles Lernen
Apr 13, 2023 pm 11:37 PM
Dies ist eine Ära der Stärkung der KI, und maschinelles Lernen ist ein wichtiges technisches Mittel zur Verwirklichung von KI. Gibt es also eine universelle Systemarchitektur für maschinelles Lernen? Im kognitiven Bereich erfahrener Programmierer ist „Alles“ nichts, insbesondere für die Systemarchitektur. Es ist jedoch möglich, eine skalierbare und zuverlässige Systemarchitektur für maschinelles Lernen aufzubauen, sofern diese auf die meisten auf maschinellem Lernen basierenden Systeme oder Anwendungsfälle anwendbar ist. Aus Sicht des Lebenszyklus des maschinellen Lernens deckt diese sogenannte universelle Architektur wichtige Phasen des maschinellen Lernens ab, von der Entwicklung von Modellen für maschinelles Lernen bis hin zur Bereitstellung von Schulungssystemen und Servicesystemen in Produktionsumgebungen. Wir können versuchen, eine solche Systemarchitektur für maschinelles Lernen anhand der Dimensionen von 10 Elementen zu beschreiben. 1.
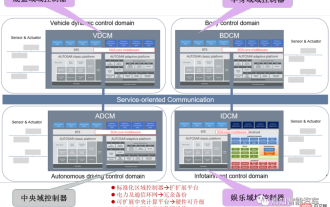 Software-Architekturdesign und Software- und Hardware-Entkopplungsmethodik in SOA
Apr 08, 2023 pm 11:21 PM
Software-Architekturdesign und Software- und Hardware-Entkopplungsmethodik in SOA
Apr 08, 2023 pm 11:21 PM
Für die nächste Generation zentralisierter elektronischer und elektrischer Architektur ist die Verwendung einer zentralen + zonalen zentralen Recheneinheit und eines regionalen Controller-Layouts für verschiedene OEMs oder Tier-1-Player zu einer unverzichtbaren Option geworden. In Bezug auf die Architektur der zentralen Recheneinheit gibt es drei Möglichkeiten: Trennung SOC, Hardware-Isolation, Software-Virtualisierung. Die zentralisierte zentrale Recheneinheit wird die Kerngeschäftsfunktionen der drei Hauptbereiche autonomes Fahren, intelligentes Cockpit und Fahrzeugsteuerung integrieren. Der standardisierte regionale Controller hat drei Hauptaufgaben: Stromverteilung, Datendienste und regionales Gateway. Daher wird die zentrale Recheneinheit einen Hochdurchsatz-Ethernet-Switch integrieren. Da der Integrationsgrad des gesamten Fahrzeugs immer höher wird, werden immer mehr Steuergerätefunktionen langsam in die Regionalsteuerung übernommen. Und Plattformisierung
 Wie steil ist die Lernkurve der Golang-Framework-Architektur?
Jun 05, 2024 pm 06:59 PM
Wie steil ist die Lernkurve der Golang-Framework-Architektur?
Jun 05, 2024 pm 06:59 PM
Die Lernkurve der Go-Framework-Architektur hängt von der Vertrautheit mit der Go-Sprache und der Backend-Entwicklung sowie der Komplexität des gewählten Frameworks ab: einem guten Verständnis der Grundlagen der Go-Sprache. Es ist hilfreich, Erfahrung in der Backend-Entwicklung zu haben. Frameworks mit unterschiedlicher Komplexität führen zu unterschiedlichen Lernkurven.
