

In diesem Artikel werden drei Möglichkeiten zum Parsen von XML auf der Android-Plattform vorgestellt.
XML wird häufig in verschiedenen Entwicklungen verwendet, und Android ist keine Ausnahme. Da das Lesen und Schreiben von XML eine wichtige Rolle beim Transport von Daten spielt, ist es zu einer wichtigen Fähigkeit in der Android-Entwicklung geworden.
In Android sind die gängigen XML-Parser DOM-Parser, SAX-Parser und PULL-Parser. Im Folgenden werde ich sie einzeln im Detail vorstellen.
Erster Weg: DOM-Parser:
DOM ist eine Sammlung von Knoten oder Informationsfragmente basierend auf einer Baumstruktur, sodass Entwickler die DOM-API verwenden können, um den XML-Baum zu durchqueren und die erforderlichen Daten abzurufen. Die Analyse dieser Struktur erfordert normalerweise das Laden des gesamten Dokuments und den Aufbau einer Baumstruktur, bevor Knoteninformationen abgerufen und aktualisiert werden können. Android unterstützt die DOM-Analyse vollständig. Mithilfe von Objekten im DOM können XML-Dokumente gelesen, durchsucht, geändert, hinzugefügt und gelöscht werden.
So funktioniert DOM: Wenn Sie DOM zum Betreiben von XML-Dateien verwenden, müssen Sie zunächst die Datei analysieren und die Datei in unabhängige Elemente, Attribute und Kommentare unterteilen usw. und stellen Sie dann die XML-Datei im Speicher in Form eines Knotenbaums dar. Sie können über den Knotenbaum auf den Inhalt des Dokuments zugreifen und das Dokument nach Bedarf ändern – so funktioniert das DOM.
Die DOM-Implementierung definiert zunächst eine Reihe von Schnittstellen für die Analyse von XML-Dokumenten. Der Parser liest das gesamte Dokument und erstellt dann eine speicherresidente Baumstruktur Code kann dann die DOM-Schnittstelle verwenden, um die gesamte Baumstruktur zu manipulieren.
Da das DOM in einer Baumstruktur im Speicher gespeichert ist, ist die Effizienz beim Abrufen und Aktualisieren höher. Bei besonders großen Dokumenten ist das Parsen und Laden des gesamten Dokuments jedoch ressourcenintensiv. Wenn der Inhalt der XML-Datei relativ klein ist, ist es natürlich möglich, DOM zu verwenden.
Häufig verwendete DoM-Schnittstellen und -Klassen:
Dokument: Diese Schnittstelle definiert eine Reihe von Analysen und Erstellungen von DOM Dokumente Methode, die die Wurzel des Dokumentenbaums und die Grundlage für den Betrieb des DOM darstellt.
Element: Diese Schnittstelle erbt die Node-Schnittstelle und stellt Methoden zum Abrufen und Ändern von XML-Elementnamen und -Attributen bereit.
Knoten: Diese Schnittstelle stellt Methoden zum Verarbeiten und Abrufen von Knoten- und untergeordneten Knotenwerten bereit.
NodeList: Stellt Methoden bereit, um die Anzahl der Knoten und den aktuellen Knoten zu ermitteln. Dadurch ist ein iterativer Zugriff auf einzelne Knoten möglich.
DOMParser: Diese Klasse ist die DOM-Parser-Klasse in Apaches Xerces, die XML-Dateien direkt analysieren kann.
Das Folgende ist der DOM-Parsing-Prozess:

Zweiter Weg: SAX-Parser:
SAX (Simple API for XML) ist ein ereignisgesteuerter Parser Die Streaming-Parsing-Methode des Parsers besteht darin, nacheinander vom Anfang der Datei bis zum Ende des Dokuments zu analysieren, ohne anzuhalten oder zurückzuspulen. Sein Kern ist das Ereignisverarbeitungsmodell, das hauptsächlich mit Ereignisquellen und Ereignisprozessoren arbeitet. Wenn die Ereignisquelle ein Ereignis generiert, rufen Sie die entsprechende Verarbeitungsmethode des Ereignisprozessors auf, und ein Ereignis kann verarbeitet werden. Wenn die Ereignisquelle eine bestimmte Methode im Ereignishandler aufruft, muss sie auch die Statusinformationen des entsprechenden Ereignisses an den Ereignishandler übergeben, damit der Ereignishandler sein eigenes Verhalten basierend auf den bereitgestellten Ereignisinformationen entscheiden kann.
Der Vorteil des SAX-Parsers besteht darin, dass er eine hohe Parsing-Geschwindigkeit hat und weniger Speicher beansprucht. Perfekt für den Einsatz in Android-Mobilgeräten.
Das Arbeitsprinzip von SAX: Das Arbeitsprinzip von SAX besteht einfach darin, das Dokument nacheinander zu scannen, wenn der Anfang und das Ende des Dokuments (Dokuments) gescannt werden , die Elemente ( Die Ereignisverarbeitungsfunktion wird benachrichtigt, wenn das Element beginnt und endet, das Dokument endet usw., und die Ereignisverarbeitungsfunktion ergreift entsprechende Aktionen und setzt dann den gleichen Scan bis zum Ende des Dokuments fort.
In der SAX-Schnittstelle ist die Ereignisquelle der XMLReader im Paket org.xml.sax, der das XML-Dokument durch den Parser analysiert( )-Methode und generieren Sie Ereignisse. Der Ereignishandler sind die vier Schnittstellen ContentHander, DTDHander, ErrorHandler und EntityResolver im Paket org.xml.sax. XMLReader stellt die Verbindung mit den vier Schnittstellen ContentHander, DTDHander, ErrorHandler und EntityResolver über die entsprechende Event-Handler-Registrierungsmethode setXXXX() her.
Häufig verwendete SAX-Schnittstellen und -Klassen: Attribute: used Get Anzahl, Name und Wert der Attribute. ContentHandler: Definiert Ereignisse, die mit dem Dokument selbst verknüpft sind (z. B. öffnende und schließende Tags). Die meisten Bewerbungen melden sich für diese Veranstaltungen an. DTDHandler: Definiert Ereignisse, die mit DTD verknüpft sind. Es werden nicht genügend Ereignisse definiert, um die DTD vollständig zu melden. Wenn eine Analyse der DTD erforderlich ist, verwenden Sie den optionalen DeclHandler. DeclHandler ist eine Erweiterung von SAX. Nicht alle Parser unterstützen es. EntityResolver: Definiert Ereignisse, die mit dem Laden von Entitäten verbunden sind. Für diese Veranstaltungen melden sich nur wenige Anmeldungen an. ErrorHandler: Fehlerereignisse definieren. Viele Anwendungen registrieren diese Ereignisse, um Fehler auf ihre eigene Weise zu melden. DefaultHandler: Stellt die Standardimplementierung dieser Schnittstellen bereit. In den meisten Fällen ist es für eine Anwendung einfacher, DefaultHandler zu erweitern und die relevanten Methoden zu überschreiben, als eine Schnittstelle direkt zu implementieren. Einzelheiten finden Sie in der folgenden Tabelle: Wie wir sehen können, benötigen wir XmlReader und DefaultHandler, um XML zu analysieren. Das Folgende ist der SAX-Parsing-Prozess: 
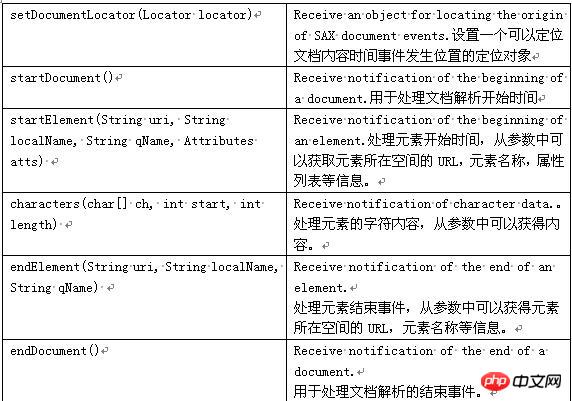

Der dritte Weg: PULL-Parser:
Android bietet nicht Unterstützung für die Java StAX API. Allerdings verfügt Android über einen Pull-Parser, der ähnlich wie StAX funktioniert. Dadurch kann der Anwendungscode des Benutzers Ereignisse vom Parser abrufen, im Gegensatz dazu, dass der SAX-Parser Ereignisse automatisch an Handler weiterleitet.
Der PULL-Parser funktioniert ähnlich wie SAX, beide sind ereignisbasiert. Der Unterschied besteht darin, dass während des PULL-Parsing-Prozesses Zahlen zurückgegeben werden und wir die generierten Ereignisse selbst abrufen und dann entsprechende Operationen ausführen müssen, im Gegensatz zu SAX, wo der Prozessor ein Ereignis auslöst und unseren Code ausführt.
Das Folgende ist der Prozess der PULL-Analyse von XML:
Das Lesen der XML-Deklaration gibt START_DOCUMENT;
zurück
Lesen Sie das Ende von XML und geben Sie END_DOCUMENT zurück;
Lesen Sie das Start-Tag von XML und geben Sie START_TAG zurück
Lesen Sie das End-Tag von XML und geben Sie END_TAG zurück
Lesen Sie den Text von XML und geben Sie TEXT zurück
PULL-Parser ist klein und leicht, hat eine hohe Parsing-Geschwindigkeit, ist einfach und benutzerfreundlich und eignet sich sehr gut für die Verwendung in Android-Mobilgeräten Das Android-System analysiert intern. Der PULL-Parser wird auch für verschiedene XML-Dateien verwendet. Android empfiehlt Entwicklern offiziell die Verwendung der Pull-Parsing-Technologie. Die Pull-Parsing-Technologie ist eine von Dritten entwickelte Open-Source-Technologie und kann auch auf die JavaSE-Entwicklung angewendet werden.
So funktioniert PULL: XML Pull stellt ein Startelement und ein Endelement bereit. Wenn ein Element startet, können wir den Parser aufrufen. nextText extrahiert alle Zeichendaten aus dem XML-Dokument. Wenn die Interpretation eines Dokuments endet, wird automatisch das EndDocument-Ereignis generiert.
Häufig verwendete XML-Pull-Schnittstellen und -Klassen:
XmlPullParser: Der XML-Pull-Parser ist eine Definitionsanalysefunktion, die in der XMLPULL VlAP1-Schnittstelle bereitgestellt wird.
XmlSerializer: Es handelt sich um eine Schnittstelle, die die Reihenfolge von XML-Informationssätzen definiert.
XmlPullParserFactory: Diese Klasse wird zum Erstellen von XML-Pull-Parsern in der XMPULL V1-API verwendet.
XmlPullParserException: Löst einen einzelnen Fehler im Zusammenhang mit dem XML-Pull-Parser aus.
Der Parsing-Prozess von PULL ist wie folgt:
[Zusätzlich] Der vierte Weg: Android.util.Xml-Klasse
in Android In der API wird auch Android bereitgestellt. util. Die XML-Klasse kann auch XML-Dateien analysieren. Sie müssen auch einen Handler schreiben, um die XML-Analyse durchzuführen, aber sie ist einfacher zu verwenden als SAX, wie unten gezeigt:
Mit Android. util. XML implementiert XML-Parsing,
MyHandler myHandler=new MyHandler0
android. util. Xm1. parse(ur1.openC0nnection().getlnputStream0, Xm1.Encoding.UTF-8, myHandler);
river.xml, abgelegt im Verzeichnis Assets . lautet wie folgt:
<?xml version="1.0" encoding="utf-8"?> <rivers> <river name="灵渠" length="605"> <introduction>
Der Lingqu-Kanal liegt im Kreis Xing'an in der Autonomen Region Guangxi der Zhuang. Er ist einer der ältesten Kanäle der Welt und gilt als „Perle der antiken Wasserschutzarchitektur der Welt“. In der Antike war der Ling-Kanal als Qin-Zhuo-Kanal, Ling-Kanal, Dou-Fluss und Xing'an-Kanal bekannt. Er wurde 214 v. Chr. gebaut und für die Schifffahrt freigegeben.
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="胶莱运河"
length
="200"
>
<
introduction
>
胶莱运河南起黄海灵山海口,北抵渤海三山岛,流经现胶南、胶州、平度、高密、昌邑和莱州等,全长200公里,流域面积达5400平方公里,南北贯穿山东半岛,沟通黄渤两海。胶莱运河自平度姚家村东的分水岭南北分流。南流由麻湾口入胶州湾,为南胶莱河,长30公里。北流由海仓口入莱州湾,为北胶莱河,长100余公里。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="苏北灌溉总渠"
length
="168"
>
<
introduction
>
位于淮河下游江苏省北部,西起洪泽湖边的高良涧,流经洪泽,青浦、淮安,阜宁、射阳,滨海等六县(区),东至扁担港口入海的大型人工河道。全长168km。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
</
rivers
>
采用DOM解析时具体处理步骤是:
1 首先利用DocumentBuilderFactory创建一个DocumentBuilderFactory实例
2 然后利用DocumentBuilderFactory创建DocumentBuilder
3 然后加载XML文档(Document),
4 然后获取文档的根结点(Element),
5 然后获取根结点中所有子节点的列表(NodeList),
6 然后使用再获取子节点列表中的需要读取的结点。
当然我们观察节点,我需要用一个River对象来保存数据,抽象出River类
public class River implements Serializable {
privatestaticfinallong serialVersionUID = 1L;
private String name;
public String getName() {
return name; }
public void setName(String name) {
this.name = name; }
public int getLength() {
return length; }
public void setLength(int length) {
this.length = length; }
public String getIntroduction() {
return introduction; }
public void setIntroduction(String introduction) {
this.introduction = introduction; }
public String getImageurl() {
return imageurl; }
public void setImageurl(String imageurl) {
this.imageurl = imageurl; }
private int length;
private String introduction;
private String imageurl; }下面我们就开始读取xml文档对象,并添加进List中:
代码如下: 我们这里是使用assets中的river.xml文件,那么就需要读取这个xml文件,返回输入流。 读取方法为:inputStream=this.context.getResources().getAssets().open(fileName); 参数是xml文件路径,当然默认的是assets目录为根目录。
然后可以用DocumentBuilder对象的parse方法解析输入流,并返回document对象,然后再遍历doument对象的节点属性。
//获取全部河流数据
/**
* 参数fileName:为xml文档路径
*/
public List<River> getRiversFromXml(String fileName){
List<River> rivers=new ArrayList<River>();
DocumentBuilderFactory factory=null;
DocumentBuilder builder=null;
Document document=null;
InputStream inputStream=null;
//首先找到xml文件
factory=DocumentBuilderFactory.newInstance();
try {
//找到xml,并加载文档
builder=factory.newDocumentBuilder();
inputStream=this.context.getResources().getAssets().open(fileName);
document=builder.parse(inputStream);
//找到根Element
Element root=document.getDocumentElement();
NodeList nodes=root.getElementsByTagName(RIVER);
//遍历根节点所有子节点,rivers 下所有river
River river=null;
for(int i=0;i<nodes.getLength();i++){
river=new River();
//获取river元素节点
Element riverElement=(Element)(nodes.item(i));
//获取river中name属性值
river.setName(riverElement.getAttribute(NAME));
river.setLength(Integer.parseInt(riverElement.getAttribute(LENGTH)));
//获取river下introduction标签
Element introduction=(Element)riverElement.getElementsByTagName(INTRODUCTION).item(0);
river.setIntroduction(introduction.getFirstChild().getNodeValue());
Element imageUrl=(Element)riverElement.getElementsByTagName(IMAGEURL).item(0);
river.setImageurl(imageUrl.getFirstChild().getNodeValue());
rivers.add(river);
}
}catch (IOException e){
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
catch (ParserConfigurationException e) {
e.printStackTrace();
}finally{
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return rivers;
}
在这里添加到List中, 然后我们使用ListView将他们显示出来。如图所示:
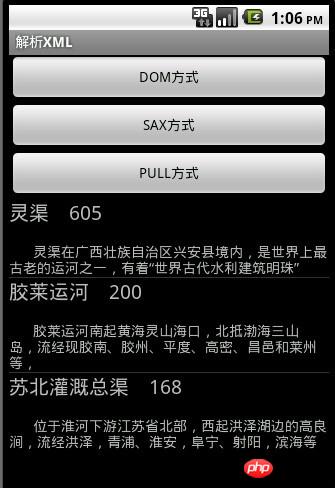
采用SAX解析时具体处理步骤是:
1 创建SAXParserFactory对象
2 根据SAXParserFactory.newSAXParser()方法返回一个SAXParser解析器
3 根据SAXParser解析器获取事件源对象XMLReader
4 实例化一个DefaultHandler对象
5 连接事件源对象XMLReader到事件处理类DefaultHandler中
6 调用XMLReader的parse方法从输入源中获取到的xml数据
7 通过DefaultHandler返回我们需要的数据集合。
代码如下:
public List<River> parse(String xmlPath){
List<River> rivers=null;
SAXParserFactory factory=SAXParserFactory.newInstance();
try {
SAXParser parser=factory.newSAXParser();
//获取事件源
XMLReader xmlReader=parser.getXMLReader();
//设置处理器
RiverHandler handler=new RiverHandler();
xmlReader.setContentHandler(handler);
//解析xml文档
//xmlReader.parse(new InputSource(new URL(xmlPath).openStream()));
xmlReader.parse(new InputSource(this.context.getAssets().open(xmlPath)));
rivers=handler.getRivers();
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return rivers;
}
重点在于DefaultHandler对象中对每一个元素节点,属性,文本内容,文档内容进行处理。
前面说过DefaultHandler是基于事件处理模型的,基本处理方式是:当SAX解析器导航到文档开始标签时回调startDocument方法,导航到文档结束标签时回调endDocument方法。当SAX解析器导航到元素开始标签时回调startElement方法,导航到其文本内容时回调characters方法,导航到标签结束时回调endElement方法。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到文档开始标签时,在回调函数startDocument中,可以不做处理,当然你可以验证下UTF-8等等。
2:当导航到rivers开始标签时,在回调方法startElement中可以实例化一个集合用来存贮list,不过我们这里不用,因为在构造函数中已经实例化了。
3:导航到river开始标签时,就说明需要实例化River对象了,当然river标签中还有name ,length属性,因此实例化River后还必须取出属性值,attributes.getValue(NAME),同时赋予river对象中,同时添加为导航到的river标签添加一个boolean为真的标识,用来说明导航到了river元素。
4:当然有river标签内还有子标签(节点),但是SAX解析器是不知道导航到什么标签的,它只懂得开始,结束而已。那么如何让它认得我们的各个标签呢?当然需要判断了,于是可以使用回调方法startElement中的参数String localName,把我们的标签字符串与这个参数比较下,就可以了。我们还必须让SAX知道,现在导航到的是某个标签,因此添加一个true属性让SAX解析器知道。
5:它还会导航到文本内标签,(就是里面的内容),回调方法characters,我们一般在这个方法中取出就是
里面的内容,并保存。 6:当然它是一定会导航到结束标签 或者的,如果是标签,记得把river对象添加进list中。如果是river中的子标签,就把前面设置标记导航到这个标签的boolean标记设置为false. 按照以上实现思路,可以实现如下代码:
/**导航到开始标签触发**/
publicvoid startElement (String uri, String localName, String qName, Attributes attributes){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签开始,则实例化River
if(tagName.equals(RIVER)){
isRiver=true;
river=new River();
/**导航到river开始节点后**/
river.setName(attributes.getValue(NAME));
river.setLength(Integer.parseInt(attributes.getValue(LENGTH)));
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=true;
}else if(tagName.equals(IMAGEURL)){
ximageurl=true;
}
}
}
/**导航到结束标签触发**/
public void endElement (String uri, String localName, String qName){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签结束,则把River添加进集合中
if(tagName.equals(RIVER)){
isRiver=true;
rivers.add(river);
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=false;
}else if(tagName.equals(IMAGEURL)){
ximageurl=false;
}
}
}
//这里是读取到节点内容时候回调
public void characters (char[] ch, int start, int length){
//设置属性值
if(xintroduction){
//解决null问题
river.setIntroduction(river.getIntroduction()==null?"":river.getIntroduction()+new String(ch,start,length));
}else if(ximageurl){
//解决null问题
river.setImageurl(river.getImageurl()==null?"":river.getImageurl()+new String(ch,start,length));
}
}
运行效果跟上例DOM 运行效果相同。
采用PULL解析基本处理方式:
当PULL解析器导航到文档开始标签时就开始实例化list集合用来存贮数据对象。导航到元素开始标签时回判断元素标签类型,如果是river标签,则需要实例化River对象了,如果是其他类型,则取得该标签内容并赋予River对象。当然它也会导航到文本标签,不过在这里,我们可以不用。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到XmlPullParser.START_DOCUMENT,可以不做处理,当然你可以实例化集合对象等等。
2:当导航到XmlPullParser.START_TAG,则判断是否是river标签,如果是,则实例化river对象,并调用getAttributeValue方法获取标签中属性值。
3:当导航到其他标签,比如Introduction时候,则判断river对象是否为空,如不为空,则取出Introduction中的内容,nextText方法来获取文本节点内容
4:当然啦,它一定会导航到XmlPullParser.END_TAG的,有开始就要有结束嘛。在这里我们就需要判读是否是river结束标签,如果是,则把river对象存进list集合中了,并设置river对象为null.
由以上的处理逻辑,我们可以得出以下代码:
public List<River> parse(String xmlPath){
List<River> rivers=new ArrayList<River>();
River river=null;
InputStream inputStream=null;
//获得XmlPullParser解析器
XmlPullParser xmlParser = Xml.newPullParser();
try {
//得到文件流,并设置编码方式
inputStream=this.context.getResources().getAssets().open(xmlPath);
xmlParser.setInput(inputStream, "utf-8");
//获得解析到的事件类别,这里有开始文档,结束文档,开始标签,结束标签,文本等等事件。
int evtType=xmlParser.getEventType();
//一直循环,直到文档结束
while(evtType!=XmlPullParser.END_DOCUMENT){
switch(evtType){
case XmlPullParser.START_TAG:
String tag = xmlParser.getName();
//如果是river标签开始,则说明需要实例化对象了
if (tag.equalsIgnoreCase(RIVER)) {
river = new River();
//取出river标签中的一些属性值
river.setName(xmlParser.getAttributeValue(null, NAME));
river.setLength(Integer.parseInt(xmlParser.getAttributeValue(null, LENGTH)));
}else if(river!=null){
//如果遇到introduction标签,则读取它内容
if(tag.equalsIgnoreCase(INTRODUCTION)){
river.setIntroduction(xmlParser.nextText());
}else if(tag.equalsIgnoreCase(IMAGEURL)){
river.setImageurl(xmlParser.nextText());
}
}
break;
case XmlPullParser.END_TAG:
//如果遇到river标签结束,则把river对象添加进集合中
if (xmlParser.getName().equalsIgnoreCase(RIVER) && river != null) {
rivers.add(river);
river = null;
}
break;
default:break;
}
//如果xml没有结束,则导航到下一个river节点
evtType=xmlParser.next();
}
} catch (XmlPullParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
return rivers;
}运行效果和上面的一样。
几种解析技术的比较与总结:
对于Android的移动设备而言,因为设备的资源比较宝贵,内存是有限的,所以我们需要选择适合的技术来解析XML,这样有利于提高访问的速度。
1 DOM在处理XML文件时,将XML文件解析成树状结构并放入内存中进行处理。当XML文件较小时,我们可以选DOM,因为它简单、直观。
2 SAX则是以事件作为解析XML文件的模式,它将XML文件转化成一系列的事件,由不同的事件处理器来决定如何处理。XML文件较大时,选择SAX技术是比较合理的。虽然代码量有些大,但是它不需要将所有的XML文件加载到内存中。这样对于有限的Android内存更有效,而且Android提供了一种传统的SAX使用方法以及一个便捷的SAX包装器。 使用Android.util.Xml类,从示例中可以看出,会比使用 SAX来得简单。
3 XML pull解析并未像SAX解析那样监听元素的结束,而是在开始处完成了大部分处理。这有利于提早读取XML文件,可以极大的减少解析时间,这种优化对于连接速度较漫的移动设备而言尤为重要。对于XML文档较大但只需要文档的一部分时,XML Pull解析器则是更为有效的方法。
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Android-Implementierung der XML-Parsing-Technologie (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Drei wichtige Frameworks für die Android-Entwicklung
Drei wichtige Frameworks für die Android-Entwicklung
 Welches System ist Android?
Welches System ist Android?
 So entsperren Sie Android-Berechtigungsbeschränkungen
So entsperren Sie Android-Berechtigungsbeschränkungen
 Welche Methoden gibt es zum Neustarten von Anwendungen in Android?
Welche Methoden gibt es zum Neustarten von Anwendungen in Android?
 Implementierungsmethode für die Android-Sprachwiedergabefunktion
Implementierungsmethode für die Android-Sprachwiedergabefunktion
 So konvertieren Sie PDF in das XML-Format
So konvertieren Sie PDF in das XML-Format
 Was bedeutet es, eine Verbindung zu Windows herzustellen?
Was bedeutet es, eine Verbindung zu Windows herzustellen?
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



