
 Datenbank
MySQL-Tutorial
MySQL-Optimierung – spezifische Analyse von Hinzufügungen, Löschungen und Änderungen (Bild)
Datenbank
MySQL-Tutorial
MySQL-Optimierung – spezifische Analyse von Hinzufügungen, Löschungen und Änderungen (Bild)
MySQL-Optimierung – spezifische Analyse von Hinzufügungen, Löschungen und Änderungen (Bild)

MySQL-Optimierung - spezifische Analyse von Hinzufügungen, Löschungen und Änderungen (Bild)
Einfügen
Weitere Zeilenabfrageergebnisse werden in die Tabelle eingefügt
Syntax
INSERT INTO table_name1(column_list1) SELECT (column_list2) FROM table_name2 WHERE (condition)
Tabellenname1 gibt die Tabelle an, in die Daten eingefügt werden sollen; Spaltenliste1 gibt an, welche Spalten in der Tabelle in welche eingefügt werden sollen Daten sollen eingefügt werden; Tabellenname2 gibt die Quelle an, aus der die Daten eingefügt werden sollen.
Von welcher Tabelle wird die Abfragespalte der Datenquellentabelle angegeben Felder und den gleichen Datentyp wie die Spalte_Liste1;
Bedingung gibt die SELECT-Anweisung an. Die Abfragebedingung
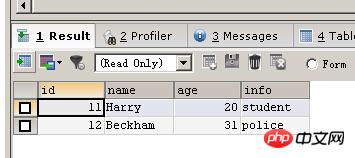
fragt alle Datensätze aus der Tabelle person_old ab und fügt sie in die Personentabelle
<🎜 ein >CREATE TABLE person ( id INT UNSIGNED NOT NULL AUTO_INCREMENT, NAME CHAR(40) NOT NULL DEFAULT '', age INT NOT NULL DEFAULT 0, info CHAR(50) NULL, PRIMARY KEY (id) ) CREATE TABLE person_old ( id INT UNSIGNED NOT NULL AUTO_INCREMENT, NAME CHAR(40) NOT NULL DEFAULT '', age INT NOT NULL DEFAULT 0, info CHAR(50) NULL, PRIMARY KEY (id) ) INSERT INTO person_old VALUES (11,'Harry',20,'student'),(12,'Beckham',31,'police') SELECT * FROM person_old

INSERT INTO person(id,NAME,age,info) SELECT id,NAME,age,info FROM person_old; SELECT * FROM person
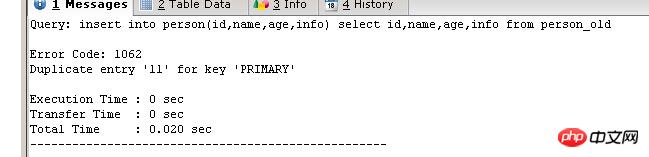
Wenn die zu importierenden Daten doppelte Werte enthalten, verfügt MYSQL über drei Optionen
Option 1: Verwenden Sie das Schlüsselwort „ignore“Option 2: Verwenden Sie „replace into“
Option drei: ON DUPLICATE KEY UPDATE
Die zweite und dritte Option werden hier nicht vorgestellt, da sie komplizierter sind und dies auch tun Hier wird nur die erste Option besprochen
TRUNCATE TABLE person TRUNCATE TABLE persona_old INSERT INTO person_old VALUES (11,'Harry',20,'student'),(12,'Beckham',31,'police') ##注意下面这条insert语句是没有ignore关键字的 INSERT INTO person(id,NAME,age,info) SELECT id,NAME,age,info FROM person_old; INSERT INTO person_old VALUES (13,'kay',26,'student') ##注意下面这条insert语句是有ignore关键字的 INSERT IGNORE INTO person(id,NAME,age,info) SELECT id,NAME,age,info FROM person_old;
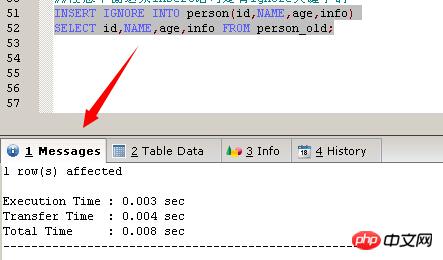
Sie können sehen, dass die Einfügung erfolgreich war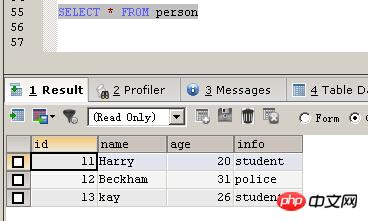
SQLSERVER
Auf der SQLSERVER-Seite, wenn Sie es ignorieren möchten, müssen beim Erstellen der Tabelle doppelte Schlüssel angegeben werden
WITH(IGNORE_DUP_KEY =EIN) EIN [PRIMÄR] Auf diese Weise behält SQLSERVER beim ersten Einfügen doppelter Werte den Wert bei, und wenn er zum zweiten Mal doppelte Werte findet, ignoriert SQLSERVER das
Unterschied zweiDer Unterschied beim Einfügen einer automatisch inkrementierenden Spalte
SQLSERVER muss
SET< verwenden 🎜>IDENTITY_INSERTTabellenname EIN, um den Wert des Felds für die automatische Inkrementierung in die Tabelle einzufügen. Wenn Sie nicht hinzufügen, SET IDENTITY_INSERT Tabellenname EIN Beim Einfügen von Daten in die Tabelle kann der Wert des Felds für die automatische Inkrementierung nicht angegeben werden, und der Wert des Felds „ID“ kann nicht automatisch angegeben werden. SQLSERVER hilft Ihnen beim automatischen Hinzufügen eins
, während MYSQL es nicht benötigt und der Freiheitsgrad sehr groß ist
INSERTINTO person(NAME,age,info) VALUES ('feicy',33,'student')
Sie können den Wert des ID-Felds als NULL angeben, und MYSQL fügt automatisch einen für Sie hinzu
INSERTINTO person(id,NAME,age,info) VALUES (NULL,'feicy',33,'student')
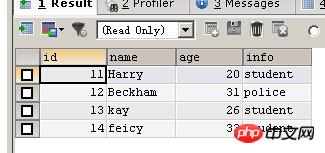
INSERT IGNORE INTO person(id,NAME,age,info) VALUES (16,'tom',88,'student')
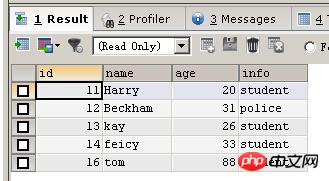
INSERT IGNORE INTO person(NAME,age,info) VALUES ('amy',12,'bb')
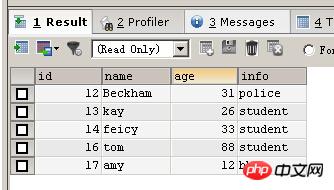 Der Freiheitsgrad ist sehr groß und es besteht keine Notwendigkeit, die Option
Der Freiheitsgrad ist sehr groß und es besteht keine Notwendigkeit, die Option
option
anzugeben Unterschied drei
Unique Das Problem wiederholter NULL-Werte im IndexMYSQL
In MYSQL schlägt der UNIQUE-Index fehl für Nullfelder
Die obige Einfügeanweisung kann wiederholt eingefügt werden (Joint). Das Gleiche gilt für eindeutige Indizes. SQLSERVERinsert into test(a) values(null) insert into test(a) values(null)
SQLSERVER funktioniert nicht
CREATE TABLE person (
id INT NOT NULL IDENTITY(1,1),
NAME CHAR(40) NULL DEFAULT '',
age INT NOT NULL DEFAULT 0,
info CHAR(50) NULL,
PRIMARY KEY (id)
)
CREATE UNIQUE INDEX IX_person_unique ON [dbo].[person](name)
INSERT INTO [dbo].[person]
( [NAME], [age], [info] )
VALUES ( NULL, -- NAME - char(40)
1, -- age - int
'aa' -- info - char(50)
),
( NULL, -- NAME - char(40)
2, -- age - int
'bb' -- info - char(50)
)消息 2601,级别 14,状态 1,第 1 行 不能在具有唯一索引“IX_person_unique”的对象“dbo.person”中插入重复键的行。重复键值为 (<NULL>)。 语句已终止。
Das Update ist relativ einfach, daher werde ich nicht viel mehr sagen
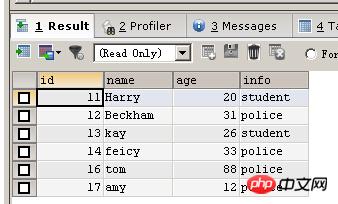
删除
删除person表中一定范围的数据
DELETE FROM person WHERE id BETWEEN 14 AND 17 SELECT * FROM person
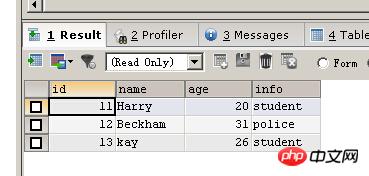
如果要删除表的所有记录可以使用下面的两种方法
##方法一 DELETE FROM person ##方法二 TRUNCATE TABLE person
跟SQLSERVER一样,TRUNCATE TABLE会比DELETE FROM TABLE 快
MYISAM引擎下的测试结果,30行记录
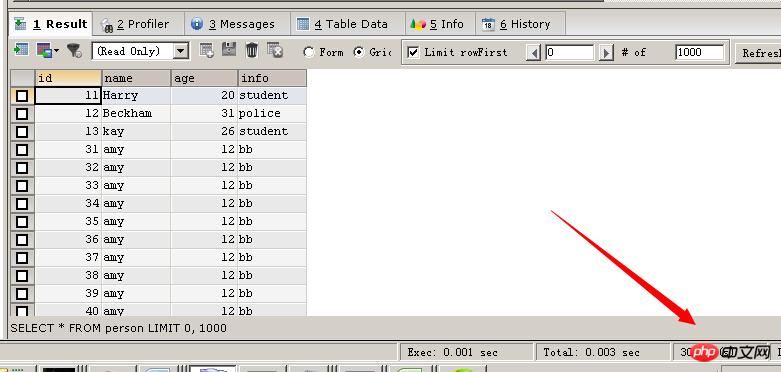
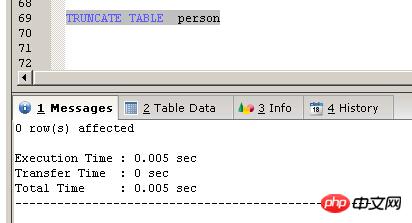
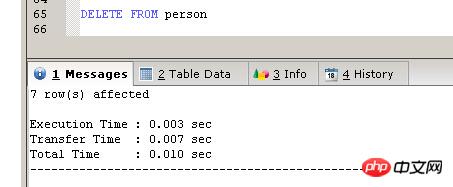
跟SQLSERVER一样,执行完TRUNCATE TABLE后,自增字段重新从一开始。
################################ INSERT IGNORE INTO person(id,NAME,age,info) SELECT id,NAME,age,info FROM person_old; SELECT * FROM person TRUNCATE TABLE person INSERT IGNORE INTO person(NAME,age,info) VALUES ('amy',12,'bb') SELECT * FROM person
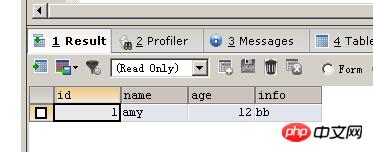
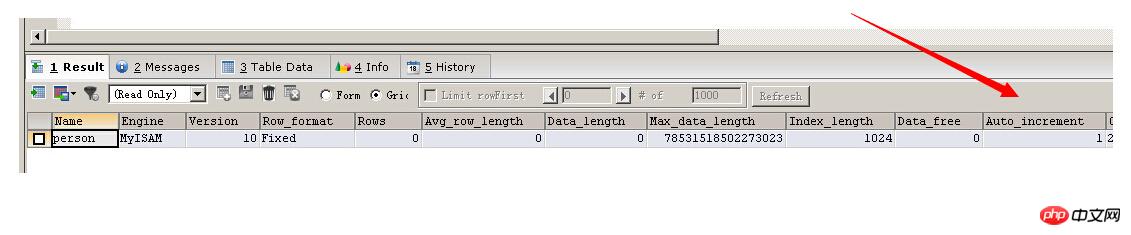
当你刚刚truncate了表之后执行下面语句就会看到重新从一开始
SHOW TABLE STATUS LIKE 'person'
Das obige ist der detaillierte Inhalt vonMySQL-Optimierung – spezifische Analyse von Hinzufügungen, Löschungen und Änderungen (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1676
1676
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Beispiel für Laravel -Einführung
Apr 18, 2025 pm 12:45 PM
Beispiel für Laravel -Einführung
Apr 18, 2025 pm 12:45 PM
Laravel ist ein PHP -Framework zum einfachen Aufbau von Webanwendungen. Es bietet eine Reihe leistungsstarker Funktionen, darunter: Installation: Installieren Sie die Laravel CLI weltweit mit Komponisten und erstellen Sie Anwendungen im Projektverzeichnis. Routing: Definieren Sie die Beziehung zwischen der URL und dem Handler in Routen/Web.php. Ansicht: Erstellen Sie eine Ansicht in Ressourcen/Ansichten, um die Benutzeroberfläche der Anwendung zu rendern. Datenbankintegration: Bietet eine Out-of-the-Box-Integration in Datenbanken wie MySQL und verwendet Migration, um Tabellen zu erstellen und zu ändern. Modell und Controller: Das Modell repräsentiert die Datenbankentität und die Controller -Prozesse HTTP -Anforderungen.
 MySQL und PhpMyAdmin: Kernfunktionen und Funktionen
Apr 22, 2025 am 12:12 AM
MySQL und PhpMyAdmin: Kernfunktionen und Funktionen
Apr 22, 2025 am 12:12 AM
MySQL und PhpMyAdmin sind leistungsstarke Datenbankverwaltungs -Tools. 1) MySQL wird verwendet, um Datenbanken und Tabellen zu erstellen und DML- und SQL -Abfragen auszuführen. 2) PHPMYADMIN bietet eine intuitive Schnittstelle für Datenbankverwaltung, Tabellenstrukturverwaltung, Datenoperationen und Benutzerberechtigungsverwaltung.
 MySQL gegen andere Programmiersprachen: Ein Vergleich
Apr 19, 2025 am 12:22 AM
MySQL gegen andere Programmiersprachen: Ein Vergleich
Apr 19, 2025 am 12:22 AM
Im Vergleich zu anderen Programmiersprachen wird MySQL hauptsächlich zum Speichern und Verwalten von Daten verwendet, während andere Sprachen wie Python, Java und C für die logische Verarbeitung und Anwendungsentwicklung verwendet werden. MySQL ist bekannt für seine hohe Leistung, Skalierbarkeit und plattformübergreifende Unterstützung, die für Datenverwaltungsanforderungen geeignet sind, während andere Sprachen in ihren jeweiligen Bereichen wie Datenanalysen, Unternehmensanwendungen und Systemprogramme Vorteile haben.
 Laravel Framework Installationsmethode
Apr 18, 2025 pm 12:54 PM
Laravel Framework Installationsmethode
Apr 18, 2025 pm 12:54 PM
Artikelzusammenfassung: Dieser Artikel enthält detaillierte Schritt-für-Schritt-Anweisungen, um die Leser zu leiten, wie das Laravel-Framework einfach installiert werden kann. Laravel ist ein leistungsstarkes PHP -Framework, das den Entwicklungsprozess von Webanwendungen beschleunigt. Dieses Tutorial deckt den Installationsprozess von den Systemanforderungen bis zur Konfiguration von Datenbanken und das Einrichten von Routing ab. Durch die Ausführung dieser Schritte können die Leser schnell und effizient eine solide Grundlage für ihr Laravel -Projekt legen.
 Erklären Sie den Zweck von Fremdschlüssel in MySQL.
Apr 25, 2025 am 12:17 AM
Erklären Sie den Zweck von Fremdschlüssel in MySQL.
Apr 25, 2025 am 12:17 AM
In MySQL besteht die Funktion von Fremdschlüssel darin, die Beziehung zwischen Tabellen herzustellen und die Konsistenz und Integrität der Daten zu gewährleisten. Fremdeschlüssel behalten die Wirksamkeit von Daten durch Referenzintegritätsprüfungen und Kaskadierungsvorgänge bei. Achten Sie auf die Leistungsoptimierung und vermeiden Sie bei der Verwendung häufige Fehler.
 Vergleichen und kontrastieren Sie MySQL und Mariadb.
Apr 26, 2025 am 12:08 AM
Vergleichen und kontrastieren Sie MySQL und Mariadb.
Apr 26, 2025 am 12:08 AM
Der Hauptunterschied zwischen MySQL und Mariadb ist Leistung, Funktionalität und Lizenz: 1. MySQL wird von Oracle entwickelt und Mariadb ist seine Gabel. 2. Mariadb kann in Umgebungen mit hoher Last besser abschneiden. 3.MariADB bietet mehr Speichermotoren und Funktionen. 4.Mysql nimmt eine doppelte Lizenz an, und Mariadb ist vollständig Open Source. Die vorhandene Infrastruktur, Leistungsanforderungen, funktionale Anforderungen und Lizenzkosten sollten bei der Auswahl berücksichtigt werden.
 SQL gegen MySQL: Klärung der Beziehung zwischen den beiden
Apr 24, 2025 am 12:02 AM
SQL gegen MySQL: Klärung der Beziehung zwischen den beiden
Apr 24, 2025 am 12:02 AM
SQL ist eine Standardsprache für die Verwaltung von relationalen Datenbanken, während MySQL ein Datenbankverwaltungssystem ist, das SQL verwendet. SQL definiert Möglichkeiten, mit einer Datenbank zu interagieren, einschließlich CRUD -Operationen, während MySQL den SQL -Standard implementiert und zusätzliche Funktionen wie gespeicherte Prozeduren und Auslöser bereitstellt.
 MySQL: Die Datenbank, PhpMyAdmin: Die Verwaltungsschnittstelle
Apr 29, 2025 am 12:44 AM
MySQL: Die Datenbank, PhpMyAdmin: Die Verwaltungsschnittstelle
Apr 29, 2025 am 12:44 AM
MySQL und PhpMyAdmin können in den folgenden Schritten effektiv verwaltet werden: 1. Erstellen und Löschen von Datenbank: Klicken Sie einfach in phpMyadmin, um sie zu vervollständigen. 2. Verwalten Sie Tabellen: Sie können Tabellen erstellen, Strukturen ändern und Indizes hinzufügen. 3. Datenbetrieb: Unterstützt das Einsetzen, Aktualisieren, Löschen von Daten und Ausführung von SQL -Abfragen. 4. Daten importieren und exportieren: Unterstützt SQL, CSV, XML und andere Formate. 5. Optimierung und Überwachung: Verwenden Sie den Befehl optimizetable, um Tabellen zu optimieren und Abfrageanalysatoren und Überwachungstools zu verwenden, um Leistungsprobleme zu lösen.
