1. Einführung
In den vorherigen Artikeln habe ich vorgestellt, wie man Python-Quellcode analysiert Crawl-Blogs, Wikipedia-InfoBox und Bilder, der Artikellink lautet wie folgt:
[Python-Lernen] Einfaches Crawlen des Meldungsfelds der Wikipedia-Programmiersprache
[Python-Lernen] Einfacher Webcrawler zum Crawlen von Blogartikeln und Einführung von Ideen
[Python-Lernen] Einfaches Crawlen von Bildern in der Bilder-Website-Galerie
Der Kerncode lautet wie folgt:
# coding=utf-8
import urllib
import re
#下载静态HTML网页
url='http://www.csdn.net/'
content = urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取标题
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, content)
title=title_obj.group()
print title
#获取超链接内容
href = r'<a href=.*?>(.*?)</a>'
m = re.findall(href,content,re.S|re.M)
for text in m:
print unicode(text,'utf-8')
break #只输出一个urlNach dem Login kopieren
Das Ausgabeergebnis lautet wie folgt:
>>>
CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
登录
>>>
Nach dem Login kopieren
Der Kerncode für das Herunterladen von Bildern lautet wie folgt:
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://creatim.allyes.com.cn/imedia/csdn/20150228/15_41_49_5B9C9E6A.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename)Nach dem Login kopieren
Aber die obige Methode der HTML-Analyse zum Crawlen von Website-Inhalten hat viele Nachteile, wie zum Beispiel:
1. Reguläre Ausdrücke sind durch den HTML-Quellcode eingeschränkt, nicht durch die abstraktere Struktur; kleine Änderungen in der Struktur der Webseite können dazu führen, dass das Programm abstürzt.
2. Das Programm muss den Inhalt basierend auf dem tatsächlichen HTML-Quellcode analysieren. Es kann auf HTML-Funktionen wie Zeichenentitäten wie & stoßen und eine Verarbeitung wie , Symbol-Hyperlinks, Indizes usw. Unterschiedlicher Inhalt.
3. Reguläre Ausdrücke sind nicht vollständig lesbar und komplexere HTML-Codes und Abfrageausdrücke werden unübersichtlich.
Da „Python Basics Tutorial (2. Auflage)“ zwei Lösungen annimmt: Die erste besteht darin, das Tidy-Programm (Python-Bibliothek) und die XHTML-Analyse zu verwenden; die zweite ist um die BeautifulSoup-Bibliothek zu verwenden.
2. Installation und Einführung Beautiful Soup-Bibliothek
Beautiful Soup ist ein in Python geschriebener HTML/XML-Parser, der das kann Behandeln Sie unregelmäßiges Markup gut und generieren Sie einen Parse-Baum. Es bietet einfache und häufig verwendete Vorgänge zum Navigieren, Suchen und Ändern von Analysebäumen. Es kann Ihre Programmierzeit erheblich sparen.
Wie es im Buch heißt: „Du hast diese schlechten Webseiten nicht geschrieben, du hast nur versucht, ein paar Daten daraus zu bekommen. Jetzt ist es dir egal.“ Wie der HTML-Code aussieht, hilft Ihnen der Parser dabei.
Download-Adresse:
http://www .php.cn/
setup.py install
 Es wird empfohlen, sich für bestimmte Verwendungsmethoden auf Chinesisch zu beziehen: http://www.php.cn/
Es wird empfohlen, sich für bestimmte Verwendungsmethoden auf Chinesisch zu beziehen: http://www.php.cn/
Darunter die Verwendung von BeautifulSoup wird am offiziellen Beispiel von „Alice im Wunderland“ kurz erklärt:
Inhalt ausgeben
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#获取BeautifulSoup对象并按标准缩进格式输出
soup = BeautifulSoup(html_doc)
print(soup.prettify())
Nach dem Login kopieren
Ausgabe gemäß der Standardstruktur des Einrückungsformats
Wie folgt: Folgendes ist eine einfache und schnelle Einführung in die BeautifulSoup-Bibliothek: (Referenz: Offizielle Dokumentation)
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>Nach dem Login kopieren
Wenn Sie den gesamten Textinhalt erhalten möchten Im Artikel lautet der Code wie folgt:
'''获取title值'''
print soup.title
# <title>The Dormouse's story</title>
print soup.title.name
# title
print unicode(soup.title.string)
# The Dormouse's story
'''获取<p>值'''
print soup.p
# <p class="title"><b>The Dormouse's story</b></p>
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
'''从文档中找到<a>的所有标签链接'''
print soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
for link in soup.find_all('a'):
print(link.get('href'))
# http://www.php.cn/
# http://www.php.cn/
# http://www.php.cn/
print soup.find(id='link3')
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>Nach dem Login kopieren
'''从文档中获取所有文字内容'''
print soup.get_text()
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
Nach dem Login kopieren
同时在这过程中你可能会遇到两个典型的错误提示:
1.ImportError: No module named BeautifulSoup
当你成功安装BeautifulSoup 4库后,“from BeautifulSoup import BeautifulSoup”可能会遇到该错误。
其中的原因是BeautifulSoup 4库改名为bs4,需要使用“from bs4 import BeautifulSoup”导入。
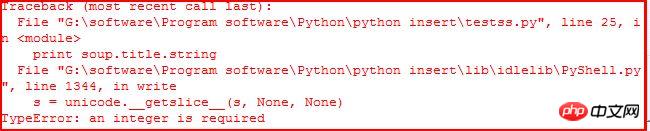
2.TypeError: an integer is required
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:
它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:stackoverflow。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
三. Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|
1.Tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="start"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html)
tag = soup.p
print tag
# <p class="title" id="start"><b>The Dormouse's story</b></p>
print type(tag)
# <class 'bs4.element.Tag'>
print tag.name
# p 标签名字
print tag['class']
# [u'title']
print tag.attrs
# {u'class': [u'title'], u'id': u'start'}Nach dem Login kopieren
使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,Beautiful Soup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。
print unicode(tag.string)
# The Dormouse's story
print type(tag.string)
# <class 'bs4.element.NavigableString'>
tag.string.replace_with("No longer bold")
print tag
# <p class="title" id="start"><b>No longer bold</b></p>Nach dem Login kopieren
这是获取“The Dormouse's story
”中tag = soup.p的值,其中tag中包含的字符串不能编辑,但可通过函数replace_with()替换。
NavigableString 对象支持遍历文档树和搜索文档树 中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现——soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
print type(comment)
# <class 'bs4.element.Comment'>
print unicode(comment)
# Hey, buddy. Want to buy a used parser?
Nach dem Login kopieren
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子:
操作文档最简单的方法是告诉你想获取tag的name,如下:
soup.head# <head><title>The Dormouse's story</title></head>soup.title# <title>The Dormouse's story</title>soup.body.b# <b>The Dormouse's story</b>
Nach dem Login kopieren
注意:通过点取属性的放是只能获得当前名字的第一个Tag,同时可以在文档树的tag中多次调用该方法如soup.body.b获取标签中第一个标签。
如果想得到所有的标签,使用方法find_all(),在前面的Python爬取维基百科等HTML中我们经常用到它+正则表达式的方法。
soup.find_all('a')# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Nach dem Login kopieren
子节点:在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
Nach dem Login kopieren
通过tag的 .children 生成器,可以对tag的子节点进行循环:
for child in title_tag.children:
print(child)
# The Dormouse's storyNach dem Login kopieren
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:
for child in head_tag.descendants:
print(child)
# <title>The Dormouse's story</title>
# The Dormouse's storyNach dem Login kopieren
父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,标签是标签的父节点,换句话就是增加一层标签。<br/> <span style="color:#ff0000">注意:文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的 .parent 是None。</span><br/></span></strong></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">title_tag = soup.titletitle_tag# <title>The Dormouse's story</title>title_tag.parent# <head><title>The Dormouse's story</title></head>title_tag.string.parent# <title>The Dormouse's story</title></pre><div class="contentsignin">Nach dem Login kopieren</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">兄弟节点</span>:因为<b>标签和<c>标签是同一层:他们是同一个元素的子节点,所以<b>和<c>可以被称为兄弟节点。一段文档以标准格式输出时,兄弟节点有相同的缩进级别.在代码中也可以使用这种关系。</span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>")print(sibling_soup.prettify())# <html># <body># <a># <b># text1# </b># <c># text2# </c># </a># </body># </html></pre><div class="contentsignin">Nach dem Login kopieren</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。<b>标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为<b>标签在同级节点中是第一个。同理<c>标签有.previous_sibling 属性,却没有.next_sibling 属性:</span></span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup.b.next_sibling# <c>text2</c>sibling_soup.c.previous_sibling# <b>text1</b></pre><div class="contentsignin">Nach dem Login kopieren</div></div><p><strong><span style="font-size:18px"> 介绍到这里基本就可以实现我们的BeautifulSoup库爬取网页内容,而网页修改、删除等内容建议大家阅读文档。下一篇文章就再次爬取维基百科的程序语言的内容吧!希望文章对大家有所帮助,如果有错误或不足之处,还请海涵!建议大家阅读官方文档和《Python基础教程》书。</span><br><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px"> </span><span style="font-size:18px; font-family:Arial; line-height:26px"><span style="color:#ff0000"> (By:Eastmount 2015-3-25 下午6点</span></span><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px">
</span>http://www.php.cn/<span style="font-family:Arial; color:#ff0000"><span style="font-size:18px; line-height:26px">)</span></span></strong><br></p>
<p></p>
<p><br></p>
<p class="pmark"><br></p>
<p>
</p><p>Das obige ist der detaillierte Inhalt vonInstallation und Einführung der Python BeautifulSoup-Bibliothek. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!</p> </div>
</div>
<div style="display: flex;">
<div class="wzconBq" style="display: inline-flex;">
<span>Verwandte Etiketten:</span>
<div class="wzcbqd">
<a onclick="hits_log(2,'www',this);" href-data="https://www.php.cn/de/search?word=beautifulsoup" target="_blank">beautifulsoup</a> <a onclick="hits_log(2,'www',this);" href-data="https://www.php.cn/de/search?word=python" target="_blank">python</a> <a onclick="hits_log(2,'www',this);" href-data="https://www.php.cn/de/search?word=知识" target="_blank">知识</a> </div>
</div>
<!-- <div style="display: inline-flex;float: right; color:#333333;">Quelle:php.cn</div>
-->
</div>
<div class="wzconOtherwz">
<a href="https://www.php.cn/de/faq/355982.html" title="Detaillierte Erläuterung der Methoden, Eigenschaften und Iteratoren in Python">
<span>Vorheriger Artikel:Detaillierte Erläuterung der Methoden, Eigenschaften und Iteratoren in Python</span>
</a>
<a href="https://www.php.cn/de/faq/356004.html" title="Verwendung der Funktionen map() und Reduce() in Python">
<span>Nächster Artikel:Verwendung der Funktionen map() und Reduce() in Python</span>
</a>
</div>
<div class="wzconShengming">
<div class="bzsmdiv">Erklärung dieser Website</div>
<div>Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn</div>
</div>
<ins class="adsbygoogle"
style="display:block"
data-ad-format="autorelaxed"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="2507867629"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzconZzwz">
<div class="wzconZzwztitle">Neueste Artikel des Autors</div>
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/354750.html">Beispiele für HTML-Einstellungen für Fett, Kursiv, Unterstrichen, Durchgestrichen und andere Schrifteffekte</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/338018.html">Implementieren Sie eine Java-Version von Redis</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/353509.html">Die einfachste WeChat-Applet-Demo</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/356272.html">Einführung in einfache Betriebsmethoden von pandas.DataFrame (Erstellen, Indizieren, Hinzufügen und Löschen) in Python</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/354839.html">WeChat Mini-Programm: Beispiel für die Implementierung des Tab-Effekts</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/354423.html">Python erstellt benutzerdefinierte Methoden, um die Ausgabe der Wörterbuchstruktur zu verschönern</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/350853.html">HTML5: Verwenden Sie Canvas, um Videos in Echtzeit zu verarbeiten</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/346502.html">Asp.net verwendet SignalR zum Senden von Bildern</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/354842.html">WeChat Mini-Programmentwicklungs-Tutorial – Übersicht über die Funktionen von App() und Page()</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/356574.html">Ausführliche Erklärung zur Verwendung von Python Redis</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
</ul>
</div>
<div class="wzconZzwz">
<div class="wzconZzwztitle">Aktuelle Ausgaben</div>
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/1796784897.html">Wie können Sie Datenbankabfragen in Python optimieren?</a>
</div>
<div>2025-03-26 16:39:41</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/1796784895.html">Erklären Sie das Konzept der Data Warehousing. Was sind Sternschemata und Schneeflockenschemata?</a>
</div>
<div>2025-03-26 16:38:35</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/1796784894.html">Was sind die verschiedenen Arten von Verknüpfungen in SQL? Wie können Sie Verbindungen mit Pandas durchführen?</a>
</div>
<div>2025-03-26 16:37:42</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/1796784893.html">Beschreiben Sie den Prozess von ETL (Extrakt, Transformation, Last). Wie können Sie eine ETL -Pipeline in Python implementieren?</a>
</div>
<div>2025-03-26 16:36:43</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="https://www.php.cn/de/faq/1796784891.html">Wie können Sie Pandas verwenden, um Daten in Python zu reinigen, zu transformieren und zu analysieren?</a>
</div>
<div>2025-03-26 16:35:41</div>
</li>
</ul>
</div>
<div class="wzconZt" >
<div class="wzczt-title">
<div>verwandte Themen</div>
<a href="https://www.php.cn/de/faq/zt" target="_blank">Mehr>
</a>
</div>
<div class="wzcttlist">
<ul>
<li class="ul-li">
<a target="_blank" href="https://www.php.cn/de/faq/pythonkfgj"><img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/subject/202407/22/2024072214424826783.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Python-Entwicklungstools" /> </a>
<a target="_blank" href="https://www.php.cn/de/faq/pythonkfgj" class="title-a-spanl" title="Python-Entwicklungstools"><span>Python-Entwicklungstools</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="https://www.php.cn/de/faq/pythondb"><img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/subject/202407/22/2024072214312147925.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Python in ausführbare Datei gepackt" /> </a>
<a target="_blank" href="https://www.php.cn/de/faq/pythondb" class="title-a-spanl" title="Python in ausführbare Datei gepackt"><span>Python in ausführbare Datei gepackt</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="https://www.php.cn/de/faq/pythonnzsm"><img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/subject/202407/22/2024072214301218201.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="was Python kann" /> </a>
<a target="_blank" href="https://www.php.cn/de/faq/pythonnzsm" class="title-a-spanl" title="was Python kann"><span>was Python kann</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="https://www.php.cn/de/faq/formatzpython"><img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/subject/202407/22/2024072214275096159.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="So verwenden Sie das Format in Python" /> </a>
<a target="_blank" href="https://www.php.cn/de/faq/formatzpython" class="title-a-spanl" title="So verwenden Sie das Format in Python"><span>So verwenden Sie das Format in Python</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="https://www.php.cn/de/faq/pythonjc"><img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/subject/202407/22/2024072214254329480.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Python-Tutorial" /> </a>
<a target="_blank" href="https://www.php.cn/de/faq/pythonjc" class="title-a-spanl" title="Python-Tutorial"><span>Python-Tutorial</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="https://www.php.cn/de/faq/pythonhjblbz"><img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/subject/202407/22/2024072214252616529.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Konfiguration von Python-Umgebungsvariablen" /> </a>
<a target="_blank" href="https://www.php.cn/de/faq/pythonhjblbz" class="title-a-spanl" title="Konfiguration von Python-Umgebungsvariablen"><span>Konfiguration von Python-Umgebungsvariablen</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="https://www.php.cn/de/faq/pythoneval"><img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/subject/202407/22/2024072214251549631.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Python-Bewertung" /> </a>
<a target="_blank" href="https://www.php.cn/de/faq/pythoneval" class="title-a-spanl" title="Python-Bewertung"><span>Python-Bewertung</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="https://www.php.cn/de/faq/scratchpyt"><img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/subject/202407/22/2024072214235344903.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Der Unterschied zwischen Scratch und Python" /> </a>
<a target="_blank" href="https://www.php.cn/de/faq/scratchpyt" class="title-a-spanl" title="Der Unterschied zwischen Scratch und Python"><span>Der Unterschied zwischen Scratch und Python</span> </a>
</li>
</ul>
</div>
</div>
</div>
</div>
<div class="phpwzright">
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="3653428331"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzrOne">
<div class="wzroTitle">Beliebte Empfehlungen</div>
<div class="wzroList">
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="Was bedeutet Auswertung in Python?" href="https://www.php.cn/de/faq/419793.html">Was bedeutet Auswertung in Python?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="So lesen Sie den Inhalt einer TXT-Datei in Python" href="https://www.php.cn/de/faq/479676.html">So lesen Sie den Inhalt einer TXT-Datei in Python</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="py-Datei?" href="https://www.php.cn/de/faq/418747.html">py-Datei?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="Was bedeutet str in Python?" href="https://www.php.cn/de/faq/419809.html">Was bedeutet str in Python?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="So verwenden Sie das Format in Python" href="https://www.php.cn/de/faq/471817.html">So verwenden Sie das Format in Python</a>
</div>
</li>
</ul>
</div>
</div>
<script src="https://sw.php.cn/hezuo/cac1399ab368127f9b113b14eb3316d0.js" type="text/javascript"></script>
<div class="wzrThree">
<div class="wzrthree-title">
<div>Beliebte Tutorials</div>
<a target="_blank" href="https://www.php.cn/de/course.html">Mehr>
</a>
</div>
<div class="wzrthreelist swiper2">
<div class="wzrthreeTab swiper-wrapper">
<div class="check tabdiv swiper-slide" data-id="one">Verwandte Tutorials <div></div></div>
<div class="tabdiv swiper-slide" data-id="two">Beliebte Empfehlungen<div></div></div>
<div class="tabdiv swiper-slide" data-id="three">Aktuelle Kurse<div></div></div>
</div>
<ul class="one">
<li>
<a target="_blank" href="https://www.php.cn/de/course/812.html" title="Das neueste Video-Tutorial zur Weltpremiere von ThinkPHP 5.1 (60 Tage zum Online-Schulungskurs zum PHP-Experten)" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="Das neueste Video-Tutorial zur Weltpremiere von ThinkPHP 5.1 (60 Tage zum Online-Schulungskurs zum PHP-Experten)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Das neueste Video-Tutorial zur Weltpremiere von ThinkPHP 5.1 (60 Tage zum Online-Schulungskurs zum PHP-Experten)" href="https://www.php.cn/de/course/812.html">Das neueste Video-Tutorial zur Weltpremiere von ThinkPHP 5.1 (60 Tage zum Online-Schulungskurs zum PHP-Experten)</a>
<div class="wzrthreerb">
<div>1439990 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/74.html" title="PHP-Einführungs-Tutorial eins: Lernen Sie PHP in einer Woche" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/068/6253d1e28ef5c345.png" alt="PHP-Einführungs-Tutorial eins: Lernen Sie PHP in einer Woche"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="PHP-Einführungs-Tutorial eins: Lernen Sie PHP in einer Woche" href="https://www.php.cn/de/course/74.html">PHP-Einführungs-Tutorial eins: Lernen Sie PHP in einer Woche</a>
<div class="wzrthreerb">
<div>4301335 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="74">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/286.html" title="JAVA-Video-Tutorial für Anfänger" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA-Video-Tutorial für Anfänger"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA-Video-Tutorial für Anfänger" href="https://www.php.cn/de/course/286.html">JAVA-Video-Tutorial für Anfänger</a>
<div class="wzrthreerb">
<div>2686709 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/504.html" title="Das nullbasierte Einführungsvideo-Tutorial von Little Turtle zum Erlernen von Python" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="Das nullbasierte Einführungsvideo-Tutorial von Little Turtle zum Erlernen von Python"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Das nullbasierte Einführungsvideo-Tutorial von Little Turtle zum Erlernen von Python" href="https://www.php.cn/de/course/504.html">Das nullbasierte Einführungsvideo-Tutorial von Little Turtle zum Erlernen von Python</a>
<div class="wzrthreerb">
<div>518067 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/2.html" title="PHP Zero-basiertes Einführungs-Tutorial" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/068/6253de27bc161468.png" alt="PHP Zero-basiertes Einführungs-Tutorial"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="PHP Zero-basiertes Einführungs-Tutorial" href="https://www.php.cn/de/course/2.html">PHP Zero-basiertes Einführungs-Tutorial</a>
<div class="wzrthreerb">
<div>879780 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="2">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="two" style="display: none;">
<li>
<a target="_blank" href="https://www.php.cn/de/course/812.html" title="Das neueste Video-Tutorial zur Weltpremiere von ThinkPHP 5.1 (60 Tage zum Online-Schulungskurs zum PHP-Experten)" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="Das neueste Video-Tutorial zur Weltpremiere von ThinkPHP 5.1 (60 Tage zum Online-Schulungskurs zum PHP-Experten)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Das neueste Video-Tutorial zur Weltpremiere von ThinkPHP 5.1 (60 Tage zum Online-Schulungskurs zum PHP-Experten)" href="https://www.php.cn/de/course/812.html">Das neueste Video-Tutorial zur Weltpremiere von ThinkPHP 5.1 (60 Tage zum Online-Schulungskurs zum PHP-Experten)</a>
<div class="wzrthreerb">
<div >1439990 Lernzeiten</div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/286.html" title="JAVA-Video-Tutorial für Anfänger" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA-Video-Tutorial für Anfänger"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA-Video-Tutorial für Anfänger" href="https://www.php.cn/de/course/286.html">JAVA-Video-Tutorial für Anfänger</a>
<div class="wzrthreerb">
<div >2686709 Lernzeiten</div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/504.html" title="Das nullbasierte Einführungsvideo-Tutorial von Little Turtle zum Erlernen von Python" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="Das nullbasierte Einführungsvideo-Tutorial von Little Turtle zum Erlernen von Python"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Das nullbasierte Einführungsvideo-Tutorial von Little Turtle zum Erlernen von Python" href="https://www.php.cn/de/course/504.html">Das nullbasierte Einführungsvideo-Tutorial von Little Turtle zum Erlernen von Python</a>
<div class="wzrthreerb">
<div >518067 Lernzeiten</div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/901.html" title="Kurze Einführung in die Web-Frontend-Entwicklung" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/067/64be28a53a4f6310.png" alt="Kurze Einführung in die Web-Frontend-Entwicklung"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Kurze Einführung in die Web-Frontend-Entwicklung" href="https://www.php.cn/de/course/901.html">Kurze Einführung in die Web-Frontend-Entwicklung</a>
<div class="wzrthreerb">
<div >217305 Lernzeiten</div>
<div class="courseICollection" data-id="901">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/234.html" title="Meistern Sie PS-Video-Tutorials von Grund auf" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/068/62611f57ed0d4840.jpg" alt="Meistern Sie PS-Video-Tutorials von Grund auf"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Meistern Sie PS-Video-Tutorials von Grund auf" href="https://www.php.cn/de/course/234.html">Meistern Sie PS-Video-Tutorials von Grund auf</a>
<div class="wzrthreerb">
<div >925669 Lernzeiten</div>
<div class="courseICollection" data-id="234">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="three" style="display: none;">
<li>
<a target="_blank" href="https://www.php.cn/de/course/1648.html" title="[Web-Frontend] Node.js-Schnellstart" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png" alt="[Web-Frontend] Node.js-Schnellstart"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="[Web-Frontend] Node.js-Schnellstart" href="https://www.php.cn/de/course/1648.html">[Web-Frontend] Node.js-Schnellstart</a>
<div class="wzrthreerb">
<div >10096 Lernzeiten</div>
<div class="courseICollection" data-id="1648">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/1647.html" title="Vollständige Sammlung ausländischer Full-Stack-Kurse zur Webentwicklung" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/067/6628cc96e310c937.png" alt="Vollständige Sammlung ausländischer Full-Stack-Kurse zur Webentwicklung"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Vollständige Sammlung ausländischer Full-Stack-Kurse zur Webentwicklung" href="https://www.php.cn/de/course/1647.html">Vollständige Sammlung ausländischer Full-Stack-Kurse zur Webentwicklung</a>
<div class="wzrthreerb">
<div >8179 Lernzeiten</div>
<div class="courseICollection" data-id="1647">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/1646.html" title="Gehen Sie zur praktischen Anwendung von GraphQL" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/067/662221173504a436.png" alt="Gehen Sie zur praktischen Anwendung von GraphQL"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Gehen Sie zur praktischen Anwendung von GraphQL" href="https://www.php.cn/de/course/1646.html">Gehen Sie zur praktischen Anwendung von GraphQL</a>
<div class="wzrthreerb">
<div >6924 Lernzeiten</div>
<div class="courseICollection" data-id="1646">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/1645.html" title="Der 550-W-Lüftermeister lernt Schritt für Schritt JavaScript von Grund auf" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/067/662077e163124646.png" alt="Der 550-W-Lüftermeister lernt Schritt für Schritt JavaScript von Grund auf"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Der 550-W-Lüftermeister lernt Schritt für Schritt JavaScript von Grund auf" href="https://www.php.cn/de/course/1645.html">Der 550-W-Lüftermeister lernt Schritt für Schritt JavaScript von Grund auf</a>
<div class="wzrthreerb">
<div >851 Lernzeiten</div>
<div class="courseICollection" data-id="1645">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="https://www.php.cn/de/course/1644.html" title="Python-Meister Mosh, ein Anfänger ohne Grundkenntnisse, kann in 6 Stunden loslegen" class="wzrthreelaimg">
<img class="lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/course/000/000/067/6616418ca80b8916.png" alt="Python-Meister Mosh, ein Anfänger ohne Grundkenntnisse, kann in 6 Stunden loslegen"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Python-Meister Mosh, ein Anfänger ohne Grundkenntnisse, kann in 6 Stunden loslegen" href="https://www.php.cn/de/course/1644.html">Python-Meister Mosh, ein Anfänger ohne Grundkenntnisse, kann in 6 Stunden loslegen</a>
<div class="wzrthreerb">
<div >33761 Lernzeiten</div>
<div class="courseICollection" data-id="1644">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper2', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrthreeTab>div').click(function(e){
$('.wzrthreeTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrthreelist>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
<div class="wzrFour">
<div class="wzrfour-title">
<div>Neueste Downloads</div>
<a href="https://www.php.cn/de/xiazai">Mehr>
</a>
</div>
<script>
$(document).ready(function(){
var sjyx_banSwiper = new Swiper(".sjyx_banSwiperwz",{
speed:1000,
autoplay:{
delay:3500,
disableOnInteraction: false,
},
pagination:{
el:'.sjyx_banSwiperwz .swiper-pagination',
clickable :false,
},
loop:true
})
})
</script>
<div class="wzrfourList swiper3">
<div class="wzrfourlTab swiper-wrapper">
<div class="check swiper-slide" data-id="onef">Web-Effekte <div></div></div>
<div class="swiper-slide" data-id="twof">Quellcode der Website<div></div></div>
<div class="swiper-slide" data-id="threef">Website-Materialien<div></div></div>
<div class="swiper-slide" data-id="fourf">Frontend-Vorlage<div></div></div>
</div>
<ul class="onef">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="Kontaktcode für das jQuery-Enterprise-Nachrichtenformular" href="https://www.php.cn/de/toolset/js-special-effects/8071">[Formular-Schaltfläche] Kontaktcode für das jQuery-Enterprise-Nachrichtenformular</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="Wiedergabeeffekte für HTML5-MP3-Spieluhren" href="https://www.php.cn/de/toolset/js-special-effects/8070">[Spezialeffekte für Spieler] Wiedergabeeffekte für HTML5-MP3-Spieluhren</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="HTML5 coole Partikelanimations-Navigationsmenü-Spezialeffekte" href="https://www.php.cn/de/toolset/js-special-effects/8069">[Menünavigation] HTML5 coole Partikelanimations-Navigationsmenü-Spezialeffekte</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="Drag-and-Drop-Bearbeitungscode für visuelle jQuery-Formulare" href="https://www.php.cn/de/toolset/js-special-effects/8068">[Formular-Schaltfläche] Drag-and-Drop-Bearbeitungscode für visuelle jQuery-Formulare</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="VUE.JS imitiert den Kugou-Musik-Player-Code" href="https://www.php.cn/de/toolset/js-special-effects/8067">[Spezialeffekte für Spieler] VUE.JS imitiert den Kugou-Musik-Player-Code</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="Klassisches HTML5-Pushing-Box-Spiel" href="https://www.php.cn/de/toolset/js-special-effects/8066">[HTML5-Spezialeffekte] Klassisches HTML5-Pushing-Box-Spiel</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery-Scrollen zum Hinzufügen oder Reduzieren von Bildeffekten" href="https://www.php.cn/de/toolset/js-special-effects/8065">[Bildspezialeffekte] jQuery-Scrollen zum Hinzufügen oder Reduzieren von Bildeffekten</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="Persönlicher CSS3-Albumcover-Hover-Zoom-Effekt" href="https://www.php.cn/de/toolset/js-special-effects/8064">[Fotoalbumeffekte] Persönlicher CSS3-Albumcover-Hover-Zoom-Effekt</a>
</div>
</li>
</ul>
<ul class="twof" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8328" title="Website-Vorlage für Reinigungs- und Reparaturdienste für Inneneinrichtungen" target="_blank">[Frontend-Vorlage] Website-Vorlage für Reinigungs- und Reparaturdienste für Inneneinrichtungen</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8327" title="Persönliche Lebenslauf-Leitfaden-Seitenvorlage in frischen Farben" target="_blank">[Frontend-Vorlage] Persönliche Lebenslauf-Leitfaden-Seitenvorlage in frischen Farben</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8326" title="Web-Vorlage für kreativen Job-Lebenslauf für Designer" target="_blank">[Frontend-Vorlage] Web-Vorlage für kreativen Job-Lebenslauf für Designer</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8325" title="Website-Vorlage eines modernen Ingenieurbauunternehmens" target="_blank">[Frontend-Vorlage] Website-Vorlage eines modernen Ingenieurbauunternehmens</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8324" title="Responsive HTML5-Vorlage für Bildungseinrichtungen" target="_blank">[Frontend-Vorlage] Responsive HTML5-Vorlage für Bildungseinrichtungen</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8323" title="Vorlage für die Website eines Online-E-Book-Shops für Einkaufszentren" target="_blank">[Frontend-Vorlage] Vorlage für die Website eines Online-E-Book-Shops für Einkaufszentren</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8322" title="IT-Technologie löst Website-Vorlage für Internetunternehmen" target="_blank">[Frontend-Vorlage] IT-Technologie löst Website-Vorlage für Internetunternehmen</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8321" title="Website-Vorlage für Devisenhandelsdienste im violetten Stil" target="_blank">[Frontend-Vorlage] Website-Vorlage für Devisenhandelsdienste im violetten Stil</a>
</div>
</li>
</ul>
<ul class="threef" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-materials/3078" target="_blank" title="可爱的夏天元素矢量素材(EPS+PNG)">[PNG material] 可爱的夏天元素矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-materials/3077" target="_blank" title="四个红的的 2023 毕业徽章矢量素材(AI+EPS+PNG)">[PNG material] 四个红的的 2023 毕业徽章矢量素材(AI+EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-materials/3076" target="_blank" title="唱歌的小鸟和装满花朵的推车设计春天banner矢量素材(AI+EPS)">[Banner image] 唱歌的小鸟和装满花朵的推车设计春天banner矢量素材(AI+EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-materials/3075" target="_blank" title="金色的毕业帽矢量素材(EPS+PNG)">[PNG material] 金色的毕业帽矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-materials/3074" target="_blank" title="黑白风格的山脉图标矢量素材(EPS+PNG)">[PNG material] 黑白风格的山脉图标矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-materials/3073" target="_blank" title="不同颜色披风和不同姿势的超级英雄剪影矢量素材(EPS+PNG)">[PNG material] 不同颜色披风和不同姿势的超级英雄剪影矢量素材(EPS+PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-materials/3072" target="_blank" title="扁平风格的植树节banner矢量素材(AI+EPS)">[Banner image] 扁平风格的植树节banner矢量素材(AI+EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-materials/3071" target="_blank" title="九个漫画风格的爆炸聊天气泡矢量素材(EPS+PNG)">[PNG material] 九个漫画风格的爆炸聊天气泡矢量素材(EPS+PNG)</a>
</div>
</li>
</ul>
<ul class="fourf" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8328" target="_blank" title="Website-Vorlage für Reinigungs- und Reparaturdienste für Inneneinrichtungen">[Frontend-Vorlage] Website-Vorlage für Reinigungs- und Reparaturdienste für Inneneinrichtungen</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8327" target="_blank" title="Persönliche Lebenslauf-Leitfaden-Seitenvorlage in frischen Farben">[Frontend-Vorlage] Persönliche Lebenslauf-Leitfaden-Seitenvorlage in frischen Farben</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8326" target="_blank" title="Web-Vorlage für kreativen Job-Lebenslauf für Designer">[Frontend-Vorlage] Web-Vorlage für kreativen Job-Lebenslauf für Designer</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8325" target="_blank" title="Website-Vorlage eines modernen Ingenieurbauunternehmens">[Frontend-Vorlage] Website-Vorlage eines modernen Ingenieurbauunternehmens</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8324" target="_blank" title="Responsive HTML5-Vorlage für Bildungseinrichtungen">[Frontend-Vorlage] Responsive HTML5-Vorlage für Bildungseinrichtungen</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8323" target="_blank" title="Vorlage für die Website eines Online-E-Book-Shops für Einkaufszentren">[Frontend-Vorlage] Vorlage für die Website eines Online-E-Book-Shops für Einkaufszentren</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8322" target="_blank" title="IT-Technologie löst Website-Vorlage für Internetunternehmen">[Frontend-Vorlage] IT-Technologie löst Website-Vorlage für Internetunternehmen</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="https://www.php.cn/de/toolset/website-source-code/8321" target="_blank" title="Website-Vorlage für Devisenhandelsdienste im violetten Stil">[Frontend-Vorlage] Website-Vorlage für Devisenhandelsdienste im violetten Stil</a>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper3', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrfourlTab>div').click(function(e){
$('.wzrfourlTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrfourList>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
</div>
</div>
<footer>
<div class="footer">
<div class="footertop">
<img src="/static/imghw/logo.png" alt="">
<p>Online-PHP-Schulung für das Gemeinwohl,Helfen Sie PHP-Lernenden, sich schnell weiterzuentwickeln!</p>
</div>
<div class="footermid">
<a href="https://www.php.cn/de/about/us.html">Über uns</a>
<a href="https://www.php.cn/de/about/disclaimer.html">Haftungsausschluss</a>
<a href="https://www.php.cn/de/update/article_0_1.html">Sitemap</a>
</div>
<div class="footerbottom">
<p>
© php.cn All rights reserved
</p>
</div>
</div>
</footer>
<input type="hidden" id="verifycode" value="/captcha.html">
<script>layui.use(['element', 'carousel'], function () {var element = layui.element;$ = layui.jquery;var carousel = layui.carousel;carousel.render({elem: '#test1', width: '100%', height: '330px', arrow: 'always'});$.getScript('/static/js/jquery.lazyload.min.js', function () {$("img").lazyload({placeholder: "/static/images/load.jpg", effect: "fadeIn", threshold: 200, skip_invisible: false});});});</script>
<script src="/static/js/common_new.js"></script>
<script type="text/javascript" src="/static/js/jquery.cookie.js?1742985748"></script>
<script src="https://vdse.bdstatic.com//search-video.v1.min.js"></script>
<link rel='stylesheet' id='_main-css' href='/static/css/viewer.min.css?2' type='text/css' media='all'/>
<script type='text/javascript' src='/static/js/viewer.min.js?1'></script>
<script type='text/javascript' src='/static/js/jquery-viewer.min.js'></script>
<script type="text/javascript" src="/static/js/global.min.js?5.5.53"></script>
<!-- Matomo -->
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="https://tongji.php.cn/";
_paq.push(['setTrackerUrl', u+'matomo.php']);
_paq.push(['setSiteId', '9']);
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
})();
</script>
<!-- End Matomo Code -->
</body>
</html>


 Es wird empfohlen, sich für bestimmte Verwendungsmethoden auf Chinesisch zu beziehen: http://www.php.cn/
Es wird empfohlen, sich für bestimmte Verwendungsmethoden auf Chinesisch zu beziehen: http://www.php.cn/